Maverick_
-
Постов
3 861 -
Зарегистрирован
Весь контент Maverick_
-
помощь с тестбенчем
Maverick_ опубликовал тема в Языки проектирования на ПЛИС (FPGA)
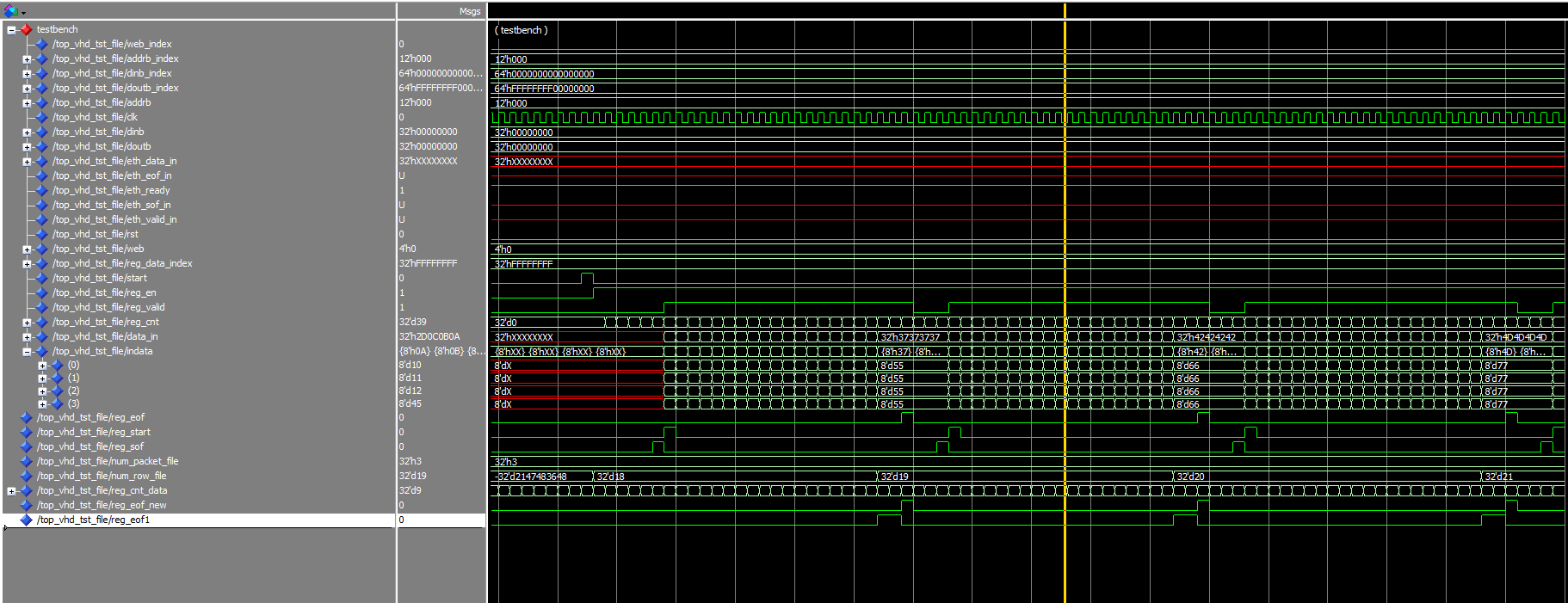
Добрый день мне стыдно обращаться с таким простым вопросом... но я что то не могу понять. Пишу тестбенч (во вложении). Там есть процесс process (all) begin if (rst = '1') then reg_eof <= '0'; reg_eof1 <= '0'; elsif (clk'event and clk = '1') then if reg_cnt_data = std_logic_vector(to_unsigned((num_row_file), reg_cnt_data'length)) then reg_eof <= '1'; else reg_eof <= '0'; end if; if reg_cnt_data = std_logic_vector(to_unsigned((num_row_file-1), reg_cnt_data'length)) then reg_eof1 <= '1'; else reg_eof1 <= '0'; end if; end if; end process; Почему reg_eof1 занимает 2 такта, а reg_eof - 1 такт. ??? Не могу понять. Прошу помощи indata.txt top_vhd_tst_file.vhd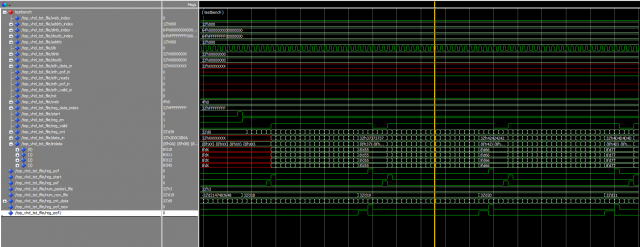
-
Добрый день
Если видите что человек продает откровенный шлак, который долго не проработает, то пишите покупателю свои мысли в личку.
Иначе продавец очень сильно злиться как сейчас...
-

Юзеры что не должны знать про этот прикол ?
Это офигенный осцилл и я выбивал его себе на работе год. А потом он сдох новый и я ничего не смог с ним сделать, после платного ремонта в Присте он проработал 2 дня(((
В личке же меня этот лихой парень назвал мудаком. Я ему ни одного слова плохого не сказал.
И потом, это не просто Лекрой. Это еще и битый Лекрой. Как нужно всадить прибор, чтобы из него вырвать кусок ? Именно поэтому возможно на 20Gs прибор он ставит такой ценник.
Возможно эта штука уже глючит....
-
-
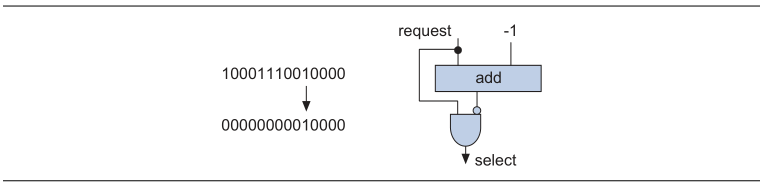
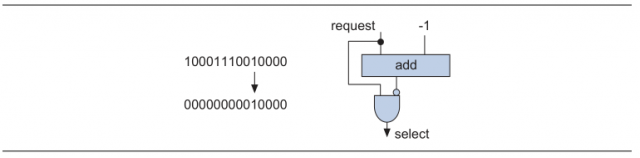
des00 спасибо за подсказку... Добрый день. (update) есть несколько индентичных модулей (размножены с помощью generic). Модуль выдает ready как данные готовы. Все модули ready выдать одновремнно не могут - только один срабатывет Выход каждого модуля это порт памяти с которого необходимо прочитать результат обработки после ready = '1'. Вопрос как мне определить с какого модуля мне надо забрать данные и как построить мультиплексор к портам памяти (возможно есть другие красивые решения). Мое решение сложное - как по мне: ниже ход мыслей Объеденяем все ready от модулей в один регистр, далее module bitscan (req,sel); parameter WIDTH = 16; input [WIDTH-1:0] req; output [WIDTH-1:0] sel; assign sel = req & ~(req-1); endmodule (что делает этот модуль во вложении картинка) от результата отнимаем 1 и считаем количество едениц ответом и будет номер модуля с какого модуля мне надо забрать данные в котором сработал ready Потом мультиплексор ... library ieee ; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity mux4 is port( d0 : in std_logic_vector(1 downto 0); d1 : in std_logic_vector(1 downto 0); d2 : in std_logic_vector(1 downto 0); d3 : in std_logic_vector(1 downto 0); s : in std_logic_vector(1 downto 0); m : out std_logic_vector(1 downto 0)); end mux4; architecture rtl of mux4 is type t_array_mux is array (0 to 3) of std_logic_vector(1 downto 0); signal array_mux : t_array_mux; begin array_mux(0) <= d0; array_mux(1) <= d1; array_mux(2) <= d2; array_mux(3) <= d3; m <= array_mux(to_integer(unsigned(s))); end rtl; Для шины адреса и данных - необходимых для чтения из памяти (BRAM) Интересуют идеи по реализации.
-
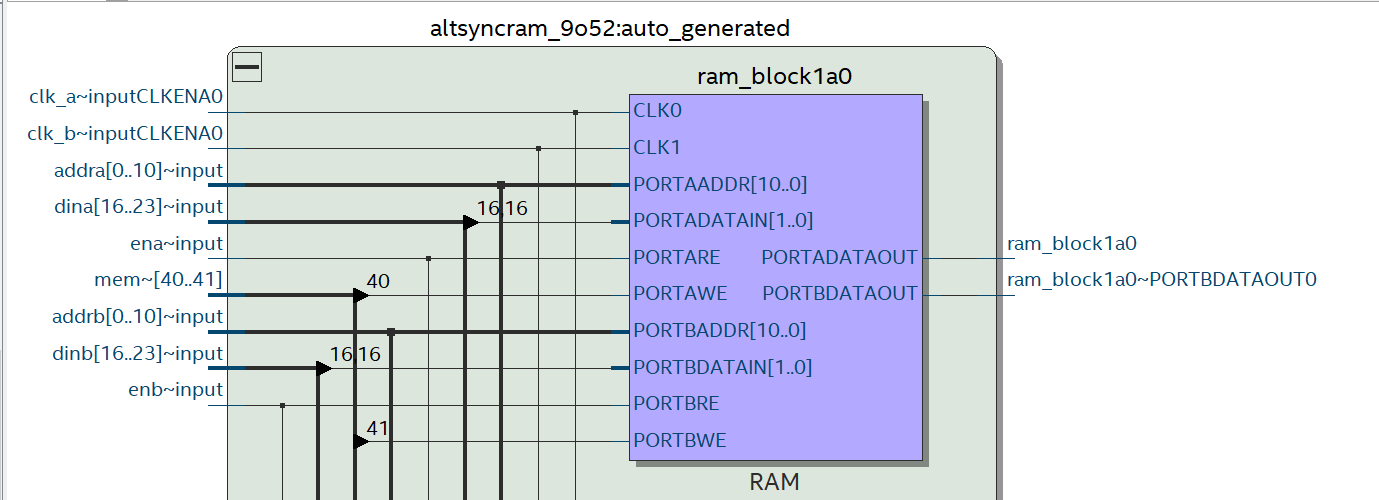
Насчет возможности с помощью Core Generator я знаю... Начал сомневаться что описать память с Chip select можно - только через Core Generator Вот еще архитектура для записи - вложение
-
описание двухпортовой памяти с CS
Maverick_ опубликовал тема в Языки проектирования на ПЛИС (FPGA)
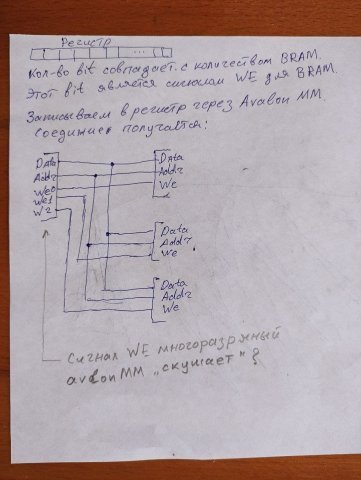
Добрый день подскажите пожалуйста как правильно описать двухпортовую память с CS(Chip select) (altera) такое решение library ieee; use ieee.std_logic_1164.all; use ieee.std_logic_unsigned.all; use IEEE.NUMERIC_STD.ALL; entity bram_tdp is generic ( DATA : integer := 32; ADDR : integer := 12 ); port ( -- Port A a_clk : in std_logic; ena : in std_logic;-- a_wr : in std_logic; a_addr : in std_logic_vector(ADDR-1 downto 0); a_din : in std_logic_vector(DATA-1 downto 0); a_dout : out std_logic_vector(DATA-1 downto 0); -- Port B b_clk : in std_logic; enb : in std_logic;-- b_wr : in std_logic; b_addr : in std_logic_vector(ADDR-1 downto 0); b_din : in std_logic_vector(DATA-1 downto 0); b_dout : out std_logic_vector(DATA-1 downto 0) ); end bram_tdp; architecture rtl of bram_tdp is -- Shared memory type mem_type is array ( (2**ADDR)-1 downto 0 ) of std_logic_vector(DATA-1 downto 0); FUNCTION initialize_ram return mem_type is variable result : mem_type; BEGIN FOR i IN ((2**ADDR)-1) DOWNTO 0 LOOP result(i) := std_logic_vector( to_unsigned(natural(i), natural'((DATA)))); END LOOP; RETURN result; END initialize_ram; shared variable mem : mem_type := initialize_ram; --shared variable mem : mem_type := (others => (others => '0')); -- := initialize_ram; begin -- Port A process(a_clk) begin if(a_clk'event and a_clk='1') then if ena = '1' then -- if(a_wr='1') then mem(conv_integer(a_addr)) := a_din; end if; a_dout <= mem(conv_integer(a_addr)); end if; -- end if; end process; -- Port B process(b_clk) begin if(b_clk'event and b_clk='1') then if enb = '1' then -- if(b_wr='1') then mem(conv_integer(b_addr)) := b_din; end if; b_dout <= mem(conv_integer(b_addr)); end if; -- end if; end process; end rtl; мне кажется не коректным т.к. не задействуется порт CS (technology viewer) - вложение. Основной вопрос как осуществить доступ к нескольким портам памяти (BRAM) имея один вход: Шина данных Шина адреса Сигнал WE Решение через сигнал WE мне кажется не очень быстродейственным - большой mux. Мне надо соедениться с 16 памятями - чтобы их инициализировать Можно конечно сделать pipeline. Может у кого есть более оригинальные решения? PS Для avalon MM для соединения мастера со многими слейвами MM - все намного проще "Chip select signal to the slave. The slave port should ignore all other Avalon signal inputs unless chipselect is asserted."