Maverick_
-
Постов
3 861 -
Зарегистрирован
Весь контент Maverick_
-
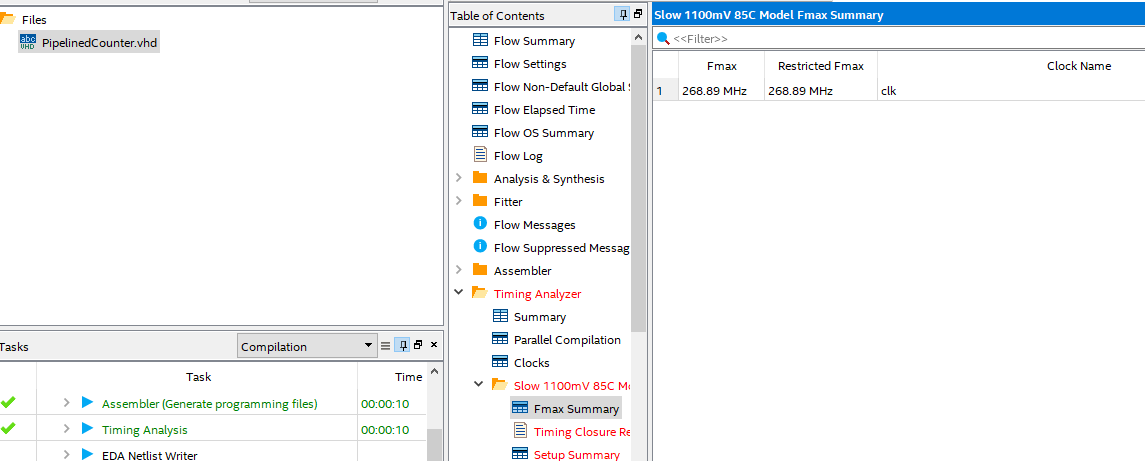
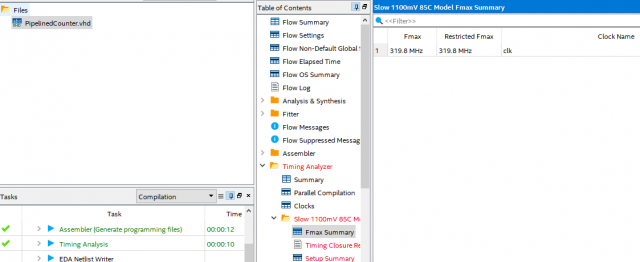
спорно (выделил жирным) это особенно если брать обработку данных в 32 бита и выше... :) и делать описание схемы с помощью языка HDL. Стараться не использовать готовые IP core производителя для обеспечения переносимости код Приведу пример на основе 64 битного счетчика Так сказать "Новороченный" счетчик: library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity PipelinedCounter is generic ( width_g: natural := 64; -- Must be divisible by parts_g. parts_g: natural := 4 ); port ( clk: in std_logic; rst: in std_logic; clear: in std_logic; enable: in std_logic; count: out std_logic_vector(width_g - 1 downto 0); tick: out std_logic ); end entity; architecture rtl of PipelinedCounter is constant part_width_c: natural := width_g / parts_g; signal almost_tick_r: std_logic_vector(parts_g - 1 downto 0); signal count_r: std_logic_vector(width_g - 1 downto 0); begin count <= count_r; process (all) variable part_v: unsigned(part_width_c - 1 downto 0); variable tick_v: std_logic; begin if rst = '1' then count_r <= (others => '0'); almost_tick_r <= (others => '0'); tick <= '0'; elsif rising_edge(clk) then tick_v := enable; for i in 0 to parts_g - 1 loop part_v := unsigned(count_r((i + 1) * part_width_c - 1 downto i * part_width_c)); if tick_v = '1' then -- Value is max - 1? if part_v = to_unsigned(2**part_width_c - 2, part_width_c) then almost_tick_r(i) <= '1'; else almost_tick_r(i) <= '0'; end if; part_v := part_v + 1; end if; count_r((i + 1) * part_width_c - 1 downto i * part_width_c) <= std_logic_vector(part_v); tick_v := tick_v and almost_tick_r(i); end loop; tick <= tick_v; if clear = '1' then count_r <= (others => '0'); almost_tick_r <= (others => '0'); tick <= '0'; end if; end if; end process; end architecture; и тот же счечик описанный стандартно: library IEEE; use IEEE.STD_LOGIC_1164.ALL; use IEEE.STD_LOGIC_ARITH.ALL; use IEEE.STD_LOGIC_UNSIGNED.ALL; entity PipelinedCounter is Port ( clk : in std_logic; en : in std_logic; rst : in std_logic; count : out std_logic_vector(63 downto 0)); end PipelinedCounter; architecture behavioral of PipelinedCounter is signal cnt: std_logic_vector (63 downto 0):= (others => '0'); begin pr_d_e: process (clk, en, cnt, rst) begin if (rst = '0') then cnt <= (others => '0'); elsif (clk'event and clk = '1') then if (en = '1') then cnt <= cnt + "0000000000000000000000000000000000000000000000000000000000000001"; end if; end if; count <= cnt; end process pr_d_e; end behavioral; обычный счетчик дает так сказать "Новороченный" счетчик PS Не для халивара. Это мое личное мнение/опыт. Все выше мною сказанное касается только если не использовать готовые IP core производителя, а стараться самому описать все вычислительные блоки на HDL, чтобы была переносимость.
-
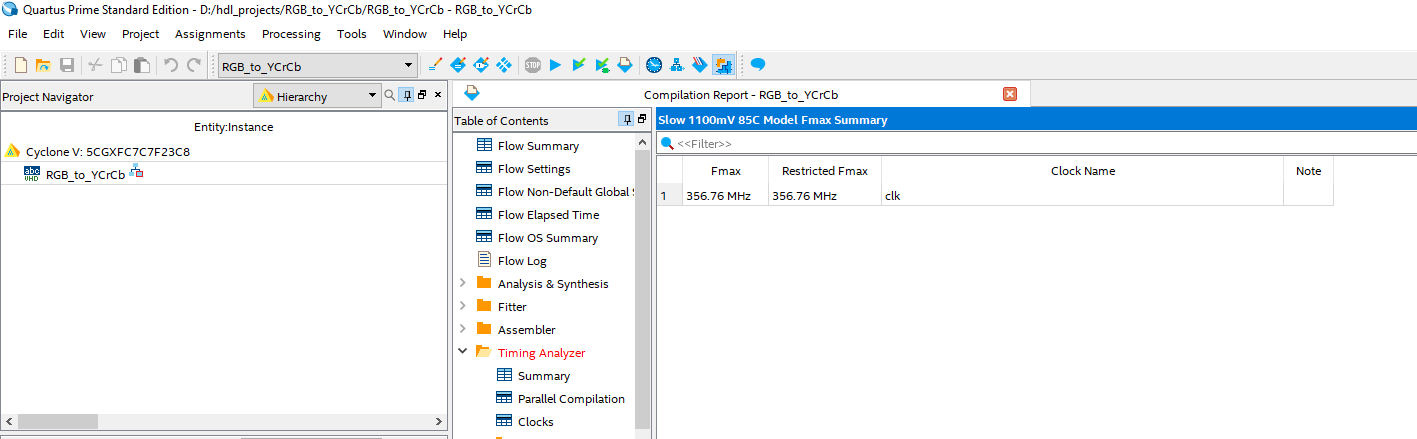
например Вы хотите посчитать то pipeline описание будет примерно следующее library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; entity RGB_to_YCrCb is generic ( N : integer:= 8; num_pixel_line : integer:= 15); port( clk : in std_logic; rst : in std_logic; en : in std_logic; --RGB pixel_R : in std_logic_vector((N-1) downto 0); pixel_G : in std_logic_vector((N-1) downto 0); pixel_B : in std_logic_vector((N-1) downto 0); --YCrCb rdy : out std_logic; Y : out std_logic_vector((N) downto 0); U : out std_logic_vector((N) downto 0); V : out std_logic_vector((N) downto 0) ); end entity RGB_to_YCrCb; architecture rtl of RGB_to_YCrCb is signal reg_R : std_logic_vector((N-1) downto 0); signal reg_G : std_logic_vector((N-1) downto 0); signal reg_B : std_logic_vector((N-1) downto 0); signal res_sum_half_RB : std_logic_vector(N downto 0); signal res_sum : std_logic_vector(N downto 0); signal sum : std_logic_vector(N downto 0); signal reg_Y : std_logic_vector((N) downto 0); --signal reg_R_shift3 : std_logic_vector((N-1) downto 0); --signal reg_G_shift3 : std_logic_vector((N-1) downto 0); --signal reg_B_shift3 : std_logic_vector((N-1) downto 0); signal reg_R_shift2 : std_logic_vector((N-1) downto 0); signal reg_G_shift2 : std_logic_vector((N-1) downto 0); signal reg_B_shift2 : std_logic_vector((N-1) downto 0); signal reg_R_shift1 : std_logic_vector((N-1) downto 0); signal reg_G_shift1 : std_logic_vector((N-1) downto 0); signal reg_B_shift1 : std_logic_vector((N-1) downto 0); signal reg_R_shift : std_logic_vector((N-1) downto 0); signal reg_G_shift : std_logic_vector((N-1) downto 0); signal reg_B_shift : std_logic_vector((N-1) downto 0); signal reg_half_R : std_logic_vector((N-1) downto 0); signal reg_half_B : std_logic_vector((N-1) downto 0); signal sum_half_RB : std_logic_vector((N) downto 0); signal reg_diff_YR : std_logic_vector((N) downto 0); signal reg_diff_YB : std_logic_vector((N) downto 0); signal res_diff0 : std_logic_vector(N downto 0); signal res_diff1 : std_logic_vector(N downto 0); signal reg_Y_shift : std_logic_vector((N) downto 0); signal reg_Y_shift1 : std_logic_vector((N) downto 0); signal reg_U : std_logic_vector(N downto 0); signal reg_V : std_logic_vector(N downto 0); signal reg_sum_U : std_logic_vector(N downto 0); signal reg_sum_V : std_logic_vector(N downto 0); signal reg_shift_ena : std_logic_vector(5 downto 0); begin process (all) begin if(rst = '1') then reg_R <= (others=>'0'); reg_G <= (others=>'0'); reg_B <= (others=>'0'); reg_half_R <= (others=>'0'); reg_half_B <= (others=>'0'); elsif rising_edge(clk) then if en = '1' then reg_half_R <= std_logic_vector(unsigned(pixel_R) / 2); reg_half_B <= std_logic_vector(unsigned(pixel_B) / 2); reg_R <= pixel_R; reg_G <= pixel_G; reg_B <= pixel_B; end if; end if; end process; process (all) begin if(rst = '1') then sum_half_RB <= (others=>'0'); reg_R_shift <= (others=>'0'); reg_G_shift <= (others=>'0'); reg_B_shift <= (others=>'0'); elsif rising_edge(clk) then if en = '1' then sum_half_RB <= res_sum_half_RB; reg_R_shift <= reg_R; reg_G_shift <= reg_G; reg_B_shift <= reg_B; end if; end if; end process; res_sum_half_RB <= STD_LOGIC_VECTOR(resize(unsigned(reg_half_R), res_sum_half_RB'length) + resize(unsigned(reg_half_B), res_sum_half_RB'length)); process (all) begin if(rst = '1') then sum <= (others=>'0'); reg_R_shift1 <= (others=>'0'); reg_G_shift1 <= (others=>'0'); reg_B_shift1 <= (others=>'0'); elsif rising_edge(clk) then if en = '1' then sum <= res_sum; reg_R_shift1 <= reg_R_shift; reg_G_shift1 <= reg_G_shift; reg_B_shift1 <= reg_B_shift; end if; end if; end process; res_sum <= STD_LOGIC_VECTOR(resize(unsigned(sum_half_RB), res_sum'length) + resize(unsigned(reg_G_shift), res_sum'length)); process (all) begin if(rst = '1') then reg_Y <= (others=>'0'); reg_R_shift2 <= (others=>'0'); reg_G_shift2 <= (others=>'0'); reg_B_shift2 <= (others=>'0'); elsif rising_edge(clk) then if en = '1' then reg_Y <= std_logic_vector(unsigned(sum) / 2); reg_R_shift2 <= reg_R_shift1; reg_G_shift2 <= reg_G_shift1; reg_B_shift2 <= reg_B_shift1; end if; end if; end process; process (all) begin if(rst = '1') then reg_diff_YR <= (others=>'0'); reg_diff_YB <= (others=>'0'); reg_Y_shift <= (others=>'0'); elsif rising_edge(clk) then if en = '1' then reg_diff_YR <= res_diff0; reg_diff_YB <= res_diff1; reg_Y_shift <= reg_Y; --reg_R_shift3 <= reg_R_shift2; --reg_G_shift3 <= reg_G_shift2; --reg_B_shift3 <= reg_B_shift2; end if; end if; end process; res_diff0 <= STD_LOGIC_VECTOR(resize(unsigned(reg_Y), res_diff0'length) - resize(unsigned(reg_R_shift2), res_diff0'length)); res_diff1 <= STD_LOGIC_VECTOR(resize(unsigned(reg_Y), res_diff1'length) - resize(unsigned(reg_B_shift2), res_diff1'length)); process (all) begin if(rst = '1') then reg_U <= (others=>'0'); reg_V <= (others=>'0'); reg_Y_shift1 <= (others=>'0'); elsif rising_edge(clk) then if en = '1' then reg_U <= reg_sum_U; reg_V <= reg_sum_V; reg_Y_shift1 <= reg_Y_shift; end if; end if; end process; reg_sum_U <= STD_LOGIC_VECTOR(resize(signed(reg_diff_YR), reg_sum_U'length) + to_signed(128, reg_sum_U'length)); reg_sum_V <= STD_LOGIC_VECTOR(resize(signed(reg_diff_YB), reg_sum_V'length) + to_signed(128, reg_sum_V'length)); U <= reg_U; V <= reg_V; Y <= reg_Y_shift1; rdy <= reg_shift_ena(5); process (all) begin if(rst = '1') then reg_shift_ena <= (others=>'0'); elsif rising_edge(clk) then for i in 0 to 4 loop reg_shift_ena(i+1) <= reg_shift_ena(i); end loop; reg_shift_ena(0) <= en; end if; end process; end rtl; так же не забываем формировать сигнал разрешенния чтения результатов вычислений для следующего модуля - в моем описании последний процесс
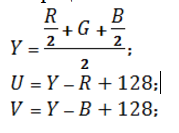
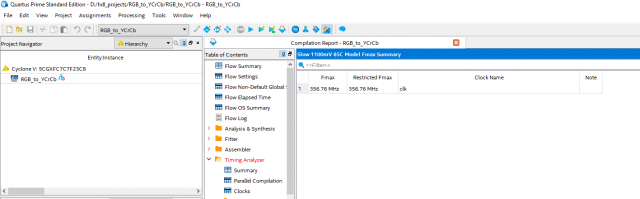
-
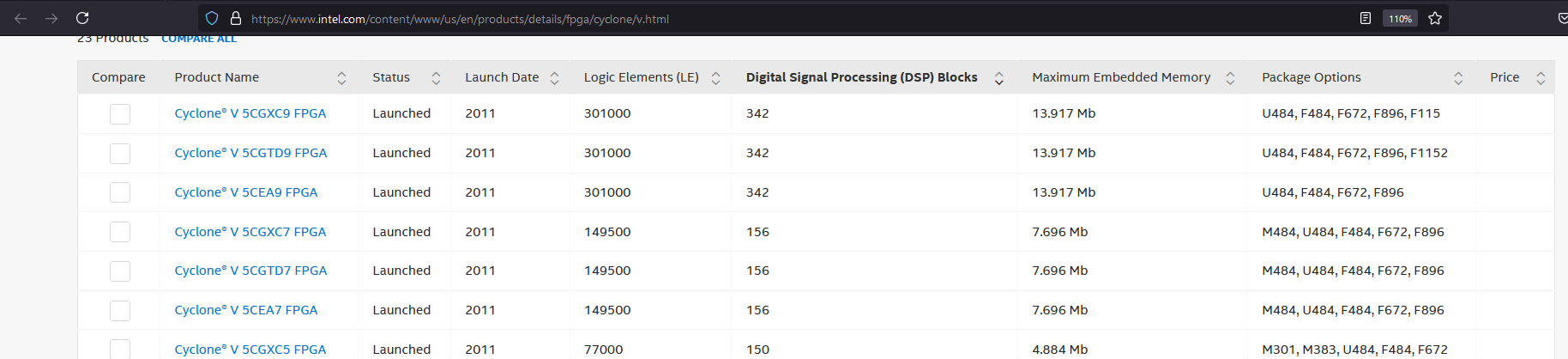
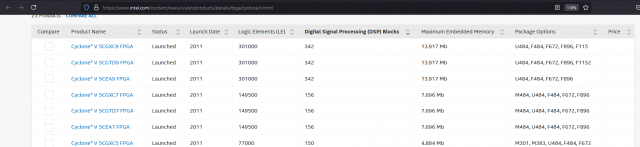
под DSP модулями имеется ввиду - столбец выделен - жирный текст DSP модули имеются в каждой современной плис у хилых он имеет вид у интел примерно такой же

-
ошибка fitter квартус
Maverick_ опубликовал тема в Работаем с ПЛИС, области применения, выбор
при компиляции выдается ошибка плата https://www.terasic.com.tw/cgi-bin/page/archive.pl?Language=English&CategoryNo=228&No=1133 прошу помощи...