Лидеры




Популярный контент
Показан контент с высокой репутацией за 27.06.2024 во всех областях
-
Так в том-то и дело, что тут надо видеть каждый кадр отображаемого значения, а иначе мельтешащий разряд сливается в нечитаемую мешанину. Даже возможно надо будет выводить еще медленнее, а иначе последний разряд не успеваешь осознать.3 балла
-
Плавали в таком, знаем ) На прошлой работе досталась в наследство линейка приборов, разработанная за 20 лет тремя поколениями разработчиков. Я, как последний оставшийся супер-стар, выдвинул предложения по комплексному рефакторингу, подкрепленные расчетом трудоемкости и описанием ближних и дальних выгод. По результатам полного игнора со стороны руководства написал заявление в день рождения начальника ) (случайно совпало) Прошу прощения за злостный оффтоп, больше не буду.
 3 балла
3 балла -
Если "дёшево и сердито" и надёжно при этом (с защитой от бабаха), то: Поставьте возле батареи большой разъём. "Маму". 8 контактов. Подключите к его контактам 1...6 ваши 6 концов батарей. И сделайте два замыкателя "папы". У одного замыкателя соедините: 2-4; 3-5; 6-7; 1-8. У другого замыкателя соедините: 1-4-5-8; 2-3-6-7. Дальше просто воткнули один замыкатель или воткнули другой. Два одновременно воткнуть невозможно. Разъёмы можно взять любые на большой ток. Нагрузка подключается к 7:8. Без всяких дидов Шоттки, хитрых реле и пр. тряхомудрии. Кондово и надёжно.3 балла
-
https://electronix.ru/forum/topic/118099-programmy-rascheta-transformatorov-i-drosseley/2 балла
-
Ой да ладно, я уже давно не наемник, и очень этому рад, и на баллы мне плевать, если доживу до пенсии, когда возраст у нас обещают обещать не увеличивать, но казна пустеет, поэтому... недвига наше все, поможет и на пенсии и до нее, ИМХО... менее и я не парюсь, а если вы так переживаете за пенсию, то мне жаль, на пенсию у нас можно только существовать, если вы не депутат или министр... Часто наезжают?)))) И коммуналка в аренду не входит, как правило... И как вас туда пускают, не русский чтоль))? штук 5 разных шняг на атмелах 90Sкакие-то там)), на сколь помню, охранку, считыватели водосчетчиков с радиоканалом, какой-то простой венд. автомат и еще по мелочи, типа миниАТСки на пине 16F84, ничего не вздувалось))) А, ну да, паяли монтажницы вручную, печки тогда были роскошью, которую могли позволить только мАсквичи))))))))2 балла
-
Эти ссылки пишут неправильно. char - это отдельный тип, который может быть как знаковым, так и беззнаковым в зависимости от ключей командной строки при вызове компилятора. Поэтому в правильно написанной программе он должен использоваться исключительно для хранения символов. Для чисел должен использоваться signed char или unsigned char (а лучше - их псевдонимы из stdint.h - int8_t и uint8_t). Поэтому ваш пример написан криворуким программистом и массив input_bytes должен быть объявлен как uint8_t input_bytes[ENCODED_FRAME_SIZE] .2 балла
-
Практически любые современные пылесосы на 1200-1800 ватт имеют регулятор скорости, который по совместительству выполняет функцию плавного старта. Движок современного пылесоса при прямом включении в сеть без регулятора тоже с большой вероятностью выносит 16а автомат. Только маломощные пылесосы до 1 квт мощи имеют включение по кнопке. Пытались применять турбины от мощных пылесосов в технологическом оборудовании и нахлебались с этим стартом по самое нехочу.2 балла
-
Удобно, но часто. Аж каждые 10 минут CR2032: диапазон напряжений 2000-3300 мВ, ёмкость 200+ мА/ч. LIR2032: диапазон напряжений 3300-4200 мВ, ёмкость 35 — 45 мА/ч.2 балла
-
Ничего лучше я сегодня на форумах уже не прочту :)))2 балла
-
Лишние позиции в BOM, лишние затраты, когда достаточно простого резистора, который стоит в серии практически ноль рублей. Везение может изменить в определённых температурных условиях. Поэтому резистор в вышеприведённой схеме нужен. Мы с коллегами тоже так делали, но людям почему-то больше нравится видеть зелёный, который показывает, что ПЛИС сконфигурировалась. Некоторые к этому так привыкли, что другого и видеть не хотят в принципе.2 балла
-
Как поставить Xilinx ISE 14.7 под windows 11. - 0 - Установить все Visual C++ Redistributable Package & Runtime Pack. - 1 - Заранее прописать системные переменные окружения: XILINXD_LICENSE_FILE C:\Xilinx\xilinx_ise.lic Xilinx C:\Xilinx\14.7\ISE_DS\ISE XIL_PAR_ENABLE_LEGALIZER 1 XILINX_VC_CHECK_NOOP 1 - 2 - Скопировать лицензию xilinx_ise.lic в папку C:\Xilinx\ - 3 - Установщик использовать 64-битный отсюда: <extracted_directory>\bin\nt64\xsetup.exe, запуск от администратора. - 4 - Примерно на 84% установщик зависнет. Над полосой прогресса будет написано что то про Web Talk. Надо запустить Диспетчер Задач, найти дерево процессов Установщика, прибить процесс этого WebTalk. Он будет выглядеть как то так: webtalk.exe или Xwebtalk.exe. После уничтожения этого процесса Установщик поедет дальше. Примечание: снятие галки с пункта "Web Talk" в диалоге начала установки не помогает. - 5 - В появившейся папке C:\Xilinx\14.7\ найти все файлы nt64\libPortability.dll и заменить их на аналогичные файлы xilinx-ise-win10-hang-hotfix\nt64\libPortability.dll - 6 - Также в папке C:\Xilinx\14.7\ найти все файлы nt64\sdk\libPortability.dll и заменить их на аналогичные файлы xilinx-ise-win10-hang-hotfix\nt64\libPortability.dll - 7 - Также в папке C:\Xilinx\14.7\ найти все файлы nt\libPortability.dll и заменить их на аналогичные файлы xilinx-ise-win10-hang-hotfix\nt\libPortability.dll - 8 - Если стоит отдельно LabTools, то последнии 3 операции проделать для него так же. - 9 - Для запуска Impact использовать бат-файлы Impact_Start_Bat.7z. Impact_Start_Bat.7z xilinx-ise-win10-hang-hotfix.zip2 балла
-
Эх, только площадь заняли змейками)) Я бы память под процессором разместил) С кварцами тоже не стоит мудрить - все эти гуард ринги никакой реальной полезности не несут.2 балла
-
лучше в редакторе слоев
 2 балла
2 балла -
Это изначально ложное утверждения - для равных свобода не может заканчиваться там где она начинается. Отсюда более корректное утверждение "свобода человека заканчивается там, где начинается свобода власти".2 балла
-
Почитайте Панчула, и книги которые он советует. Разрабатывайте свои процессоры. Изучайте физику полупроводников, химию. Делайте свои установки для изготовления микросхем.1 балл
-
Хах. Вроде полная и поновее: https://github.com/JeonghwaLee-TwinDAD/GIP-FCT/tree/main/Config/Toolkits/JLink_Windows_SDK_V764d_PXEIkg0H И обрезанные: https://github.com/dihonglongxi/FactoryTestApp/tree/1d5c47fa3c896cef256e33339684149525c0a906/JLinkSDK https://github.com/SyzTrust/syztrust/tree/main/board_manager1 балл
-
https://www.we-online.com/components/media/o563289v410 ANE009a_EN.pdf страница 101 балл
-
Я доволен тем результатом, что получился в последний раз. Но меня пытаются убедить в существовании подъёмов на 900+ МГц. Честно говоря, мне до лампочки что там после 900 МГц, так как первый фильтр до МШУ это всё уберёт, ну и про сам трансивер не забываем. А оснастка скорее всего влечёт за собой де-эмбиддинг, есть такая опция в VNA, пока не разбирался с ней. А вообще, если в СВЧ уходить с головой, то можно назад и не вынырнуть. Конечная цель - сделать задуманное, а не навсегда застрять в СВЧ.1 балл
-
Если есть собственный станок, то да. Но все равно про выставку все узнают за год. Поэтому две недели можно увеличить. По военке, да, но у нас ее нет, поэтому никого не двигаем. Да и потом глупо работать без резерва мощностей. Всякие "вдруг" появляются регулярно и вот тогда вступают в силу резервы. Мы сейчас сертифицируемся по СМК, до конца года должны податься уже на внешний аудит, а в СМК главная линия - интересы заказчика. Поэтому "им норм" это не про СМК, а про желание ухватить куш прямо сейчас. Интересы Заказчика уходят на второй план. По 120 вместо 100 - это все таки финансово довольно накладно, выгоднее поставлять компоненты с запасом. Хотя если есть уверенность что 20штук пойдут в следующую партию или ЗИП или на непредвиденные запросы, то может и оправдано. По резинкам: Хороший поставщик перепакует в вакуумную тару с силикагелем, укажет на наклейке когда перепаковка произошла и вложит индикатор влажности. И гарантирует что TQFP внутри без мятых ног и правильной ориентации. Кстати вакууматоры стоят копейки, силикагель почти бесплатен и сушильный шкаф тоже. Шкаф сухого хранения да чуть дороже, но тоже не космос. И тогда все будет замечательно!1 балл
-
Там один резистор в Чип-Дипе по цене как вся фотовспышка с Алиэкспресса. Но вот в фотовспышке уже вся схема готова и работает по принципу накачки заряда через диоды. Никаких сотен ватт, всё в компактном корпусе. Вообще, чето походу автор решил собрать электрошокер, чтоб ребенок ходил и "бодал" одноклассников. А на уроке физики детям не положено работать с напряжениями выше 36 В, если чо так. А энергия, запасенная в 8000 мкФ при 400 В... кстати, пусть ребенок посчитает, какова эта энергия насколько её хватит на примере нагрева 1 кг воды.1 балл
-
разница в индуктивности вполне приличная, эксперимент только начинается и быстро сделать не получится. разница гораздо больше. все верно, так и получается, но разница вполне прилична и ее нужно учитывать. нет, мощность поменьше немного, но несколько недель назад видел инвертор ведомый сетью на 1.5Мвт, мое уважение разработчикам...... вот там размеры впечатляющие..... жаль что никто из присутствующих не разрабатывал что-либо подобное, ответа на свой вопрос я не получил, зато ненужных вопросов с лихвой.....😁1 балл
-
А сколько вы хотите? Вот есть такой фильтр -0,73дБ на 440Мгц, на ваших 433МГц у него -1,1дБ. Можете у них же заказать аналог на ваши частоты.1 балл
-
Особенно если учесть, что допуск на индуктивность стандартных силовых дросселей, имеющихся на рынке, в лучшем случае ±10%. А то и все 20. Например (как раз с заветным прямоугольным проводом).1 балл
-
А разве применение LAA не влечет наличия обязательной настройки MAC address? Ведь оно должно настраиваться под распределение адресов в конкретной локальной сети. Что за вздорная фантазия вообще: продавать устройства с зашитым намертво LAA MAC address? LAA => обязательная настройка адреса. Без вариантов.1 балл
-
Откопать в загашниках старую-старую материнку с сетью на борту. Вычитать из нее MAC и нагенерить своих, добавляя к нему по единичке. Все ровесники этой матринки давно в утиле, пересечений не будет.1 балл
-
Совет негодный! Если серьезный корпоративный заказчик с действительно работающей службой информационной безопасности он в ТЗ впишет требование уникальности MAC. Не дай бог коллизия - разборки на уровне СИБ, немедленное отключение всей поставленной продукции до приведения к требованиям ТЗ. Все за счет поставщика + компенсация убытков и упущенной выгоды.1 балл
-
Размер хранилища в рабочей папке (не репозитория). В SVN он меньше. git хранит каждую версию файла помимо репозитория так же и в рабочей папке. Это дает преимущества 1. Возможность хранить все версии коммитов проекта и получать к ним доступ даже при отсутствии доступа к репозиторию. 2. Если делать как в п. 1, то получаем возможность восстановить репозиторий из рабочей папки, когда репозиторий грохнулся. Но размер рабочей папки раздувается сильно, особенно при больших бинарных файлах. Наши программисты как раз отказались от git, т.к. готовые бинарники готовых ядер под гигабайт и этот гигабайт плюсуется при каждом коммите. --------------- Если честно, я сам с git-ом не работаю, и они сказали, что типа все версии хранятся и отключить это невозможно. Но интеренет вроде говорит, что можно. Это видимо мне придется разбираться. Так вот, если эти преимущества гита отключить, то мы в принципе получаем одно и тоже, что git, что svn1 балл
-
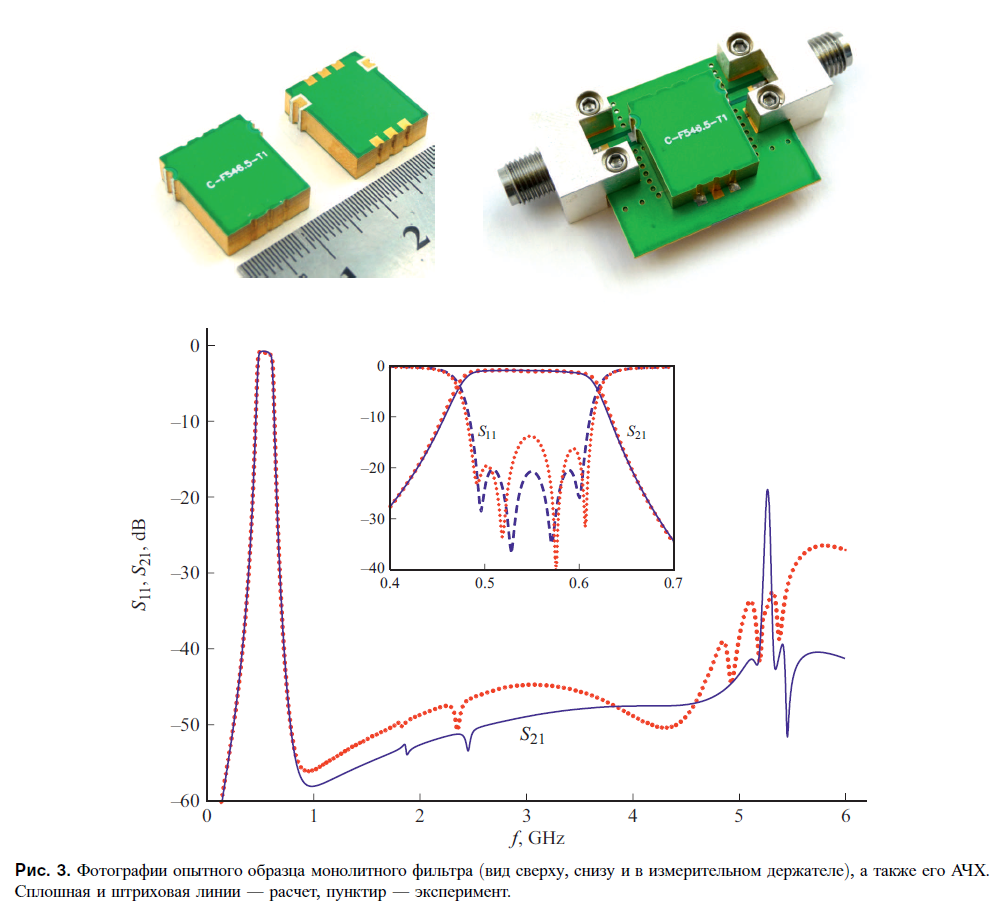
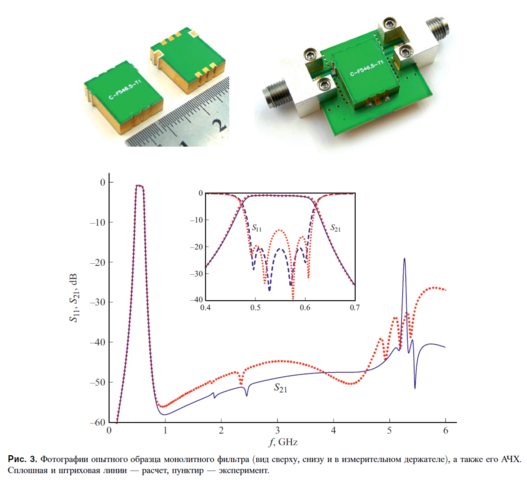
В догонку для размышления кину наработки красноярских ученых мужей: Беляева, Сержантова, Лексикова. Погуглив по фамилиям, найдете много интересного за десятки лет плодотворного труда. Серебрения и прочих "безобразий" нет, но потребуется серьезный умственный вклад в AWR, ADS, CST, HFSS и подобных. Belyaev_2021.pdf
 1 балл
1 балл -
Последовательное.1 балл
-
Может быть порядок инициализации каких-то регистров важен ? Вы документацию на микроконтроллер хорошо изучили ? Я немного работал с dsPIC33. С UART проблем никогда не было.1 балл
-
Вы изначально неверно позиционируете своё изделие на рынке! Позиционируйте его как медицинское устройство. Для развития мелкой моторики пальцев пользователя. И ваша бизнес-идея будет успешной. Ведь при ёмкости CR2032 = ~210мА/ч и токе разряда ~1А, батарейки хорошо если хватит на пару минут работы (на больших токах разряда - ёмкость ниже). А некоторые батарейки и вообще не потянут - менять надо будет сразу же. А значит - пользователю придётся часто менять батарейки. А это - множество мелких операций пальцами! Соответственно - очень полезно для развития мелкой моторики.1 балл
-
Если по каким-то причинам не выгорит с MSPM0G3107, то вспомнил тут про ещё один _возможно_ подходящий для задачи ТС МК с много-АЦП: серия SPC58NH... от STM. Совсем про них забыл.... Я сам с ними не работал, но рассматривал для какого-то проекта. Так что сужу чисто теоретически - по даташиту. Если ему верить, то они имеют по 4 SAR ADC с частотой выборок до 16MHz/5 = 3.2MS/s (в 10-битном fast режиме). И 100 АЦП-каналов. Т.е. - если каналы в чипе распределены так, что получится на каждый АЦП посадить по 10 каналов (я не смотрел распределение), то как раз получатся желаемые 0.32MS/s на канал. И того = 40 каналов на один МК. 2 МК = уже 80 каналов. На mouser-е и digikey они есть на складе, с ценой ~30 евро при 100шт. партии. Т.е. - вроде не смертельно для проекта ТС. Правда в наличии почему-то только самые тяжёлые (и дорогие) камни из линейки: SPC58NH92... (3-ядерные, с 10 МБ флеша). 6МБ-ных почему-то нет в наличии (а они думаю должны быть заметно дешевле). Но может ещё появятся вскоре? К тому-же: 3 ядра по 200МГц каждое - возможно хватит даже и для обработки данных (40 каналов на чипе). Архитектура у них правда какая-то хитрая: не народный Cortex. Но... наличие у каждого ядра своей памяти: ...а также кешей: ...и некий "лёгкий DSP-набор": дают надежду, что возможно этот МК сможет потянуть и обработку данных. И тогда - кроме двух таких МК на плате, больше ничего и не нужно будет. К тому же - там имеется некий: Если этот eDMA (enhanced?) позволит поток сэмплов со всех 4 АЦП раскидывать равномерно по регионам ОЗУ трёх ядер, распределяя таким образом вычислительную нагрузку по ним, то шансы успеть прожевать все данные и не захлебнуться - имеются. Получается: 3.2*4/3 = ~4.267 MS/s - вычислительная нагрузка на каждое 200МГц-овое ядро. При работе каждого ядра в своём регионе ОЗУ я думаю - уже должно хватить быстродействия прожевать этот поток. Хотя конечно нужно бы посмотреть - что там за система команд и что она могёт?1 балл
-
Итальянские Icel посмотрите.1 балл
-
WIMA посмотрите. Они полно конденсаторов всяких делают. Потому что это полипропиленовые В импортной терминологии вам надо смотреть полиэстер, лавсан, майлар.1 балл
-
Плюсы, если используем альтиум на двух и более рабочих местах. Например дома и на работе. Проект (или библиотеки) закоммитили на работе, пришли домой, проапдейтили, и через 5 минут продолжаем работать с той же точки. я использую именно так. откаты на какие-то предыдущие версии и прочие фишки контролей версии не помню даже, чтоб понадобились. сливы, конкатенации и т.д. с бинарными файлами в принципе невозможны. ---- если же работать на одном месте, лучше использовать бекап, причем автоматический. я использую robocopy. можно поиском много инфы нарыть или могу свою инструкцию скинуть1 балл
-
Проверять надо более комплексно, например выдернуть кабель и снова подключить, сделать power/off - power onn и т.д., наблюдать не светодиод линка, а реальный обмен пакетами. При этом время и результат (успех/неуспех) с разными компьютерами, маршрутизаторами или коммутаторами на разных скоростях и настройках может быть разным. Про задержку. Почему она существует и почему она потребовалась. Существует протокол автосогласования, для того чтобы он отработал требуется время: https://en.wikipedia.org/wiki/Autonegotiation В ST некогда переписали HAL код Ethenet и сделали множество ошибок, одной из них является само построение логики: они сбрасывают PHY, инициализируют, и ждут окончания процесса автосогласования, для чего выдерживают заданную паузу. В этом у них еще и баг, так как в некоторых случаях с гигабитными линками требуемое время существенно больше, до 3сек, то есть превышает заданную ими паузу. Правильный код должен сбросить PHY, проинициализировать, и на этом инициализация должна закончиться, перенеся время ожидания в цикл, в периодическую проверку is link up.
 1 балл
1 балл -
Аудиокодеки вам в помощь. Как раз 300 с хвостиком килогерц. 24 бита. И в одном кодеке может быть много много ацп. Порядка 6 каналов. Стоят недорого.1 балл
-
Обычно да, но в контакторах галеты обмоток сменные и можно найти на 24 вольта от автоматики станков. Про насосы на 660В была тема на чипмейкере, там все непросто, но и мощности у этих насосов от 50 квт начинаются. Надеюсь это не случай автора темы. А более высоковольтные двигатели очень редко можно встретить, и там все равно понижающий трансформатор нужен, даже если линия питающая 6 кВ1 балл
-
Ничего странного: Оттуда же про постоянный ток: Ну и подробнее по ссылке.1 балл
-
Сугубо имхо - На обычном домашнем компе в разумное время реально расчитать до 5 байт брутфорсом. На чем то заточенном - на пару порядков больше. Скажем, 8 байт. Так что исходные 8 символов, тем более заглавными - имхо маловато, если использованные алгоритмы "врагу" известны. Верхний регистр - это ASCII с 0x41 по 0x5A: (26)^8 = ... за 14 дней и ваш STM32H743 справится. ЗЫ: а энигма, говорят, погорела на всеми известном приветствии предводителю, которым оканчивалось каждое сообщение....1 балл
-
Да, так и будет)) Я просто хотел отразить саму неизбежность в обрастании классов всякими плюсовыми прибамбасами даже в низкоуровневом коде. Потому что, ИМХО, терять все те прелести C++ - равносильно покупке нового авто, а продолжать кататься на старом ведре. Я за подход в стиле "нужно чутка подумать над низкоуровневыми классами, чтобы их поведение было максимально предсказуемым при реализации в разных компиляторах и по занимаемым ресурсам".1 балл
-
static constexpr int a = 40 внутри класса может иметь место.1 балл
-
1 балл
-
Логотип производителя Brightking (их купила Yageo), диод SMBJ85CA.1 балл
-
У логотипа Bourns другой шрифт, хотя "DV" в их паспорте — SMBJ85CA, т.е. тоже без полоски и напряжение похоже.1 балл
-
Коммутация секций аккумулятора, особенно на такие большие, токи НЕПРИЕМЛЕМО в принципе. Забудьте эту затею как страшный сон. При неисправности элементов коммутации аккумулятор превратиться в бомбу, которая зазнесёт всё в дребезги пополам - там энергии всего в пять раз меньше, чем в тротиле того же веса.1 балл
-
Не имеет, она неработоспособна. Р-канальный MOSFET там вообще говоря не нужен. Вполне сгодится N-канальный, пусть на нем падает напряжение и рассеивается мошность. Зато LDO будет меньше греться при питании от 17В
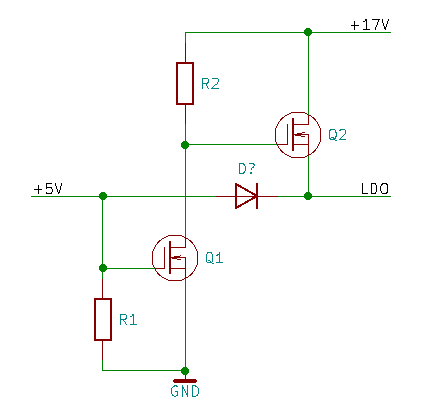 1 балл
1 балл -
Разобрался с 10G линком для Titan 2. Может будет полезно. Проверено на плате Alinx AXP-390 для одного канала. https://github.com/boikovaleksandr/axp390-pangomicro-titan2-raw-10g-link1 балл
-
походу ИИ какого-то пылесоса дорвался до интернета и решил изучать схемотехнику на этом форуме1 балл
-
Нет. Вы просто не умеете читать и анализировать, что Вам пишет собеседник, т.е. в данном случае - я. И очень красиво уходите от действительно конструктивного обсуждения. На этом действительно можно закончить, т.к. вести диалог с сомнительного качества профессионалом - терять своё время, да ещё и напитать свой опыт вероятными лжезнаниями.1 балл