


rloc
-
Постов
3 154 -
Зарегистрирован
-
Победитель дней
12
Сообщения, опубликованные rloc
-
-
Хочу поделиться результатами эксперимента проверки FMC132P
Кто такой щедрый, что не задумываясь купит XCVU7P-2FLVB2104 ?
-
EvilWrecker, в каком САПР на ваш взгляд с наибольшей эффективностью (минимальными трудозатратами) можно "утрамбовать" зиг-заги, чтобы они занимали любое доступное пространство ПП, в условиях высокой плотности разводки и соблюдении DRC? А в дальнейшем проще было редактировать: удалять, вставлять, сдвигать?
-
Каденс в районе 10k$...
За эти деньги можно купить только оркадовские пакеты (эквивалент PADS Pro, который на базе Xpedition), а аллегровские - также выйдут 100-150k$
Поэтому, в ценовой категории 10к$ логичнее сравнивать:
1. Cadence OrCAD PCB Designer Professional
2. Mentor PADS Professional
3. Altium Designer 18
-
интрес был к достижимой добротности ненагруженного резонатора из различных монокристаллов ( сапфир, ниобат лития етс) в зависимости от частоты.
Есть зависимость f*Q0 от твердости материала. При комнатной температуре лучше алмаз (как DR и как пьезоэлектрик) :) В MEMS так и делают.
-
Насколько они устойчивы к акустическим шумам и вибрации?
Да, в генераторах с высокодобротными элементами это серьезная проблема. С кварцевыми генераторами точно такие же проблемы, исключений нет. Только, за счет мЕньших размеров, легче бороться с акустикой: включением нескольких резонаторов с ортогональным расположением осей, демпфированием ...
Немцы мало написали о термостабилизации, только для случая, когда добротность достаточно низкая, и есть возможность подстройки варикапом (кстати, за счет снижения добротности, и в узком интервале температур +-6 гр.). При высокой добротности, решений с помощью электронной подстройки не предлагают. На E5052 частотная "болтанка" выглядит как резкий рост шумов по закону 40 дБ/дек (по памяти). На FSWP частотная девиация не так заметна, наверное полоса FLL шире. Здесь хотелось бы отметить серьезные продвижения Сергея Бельчикова, потратившего немало усилий в решении этой проблемы. Думаю, решение проблем с акустическими шумами лежит в том же направлении.
-
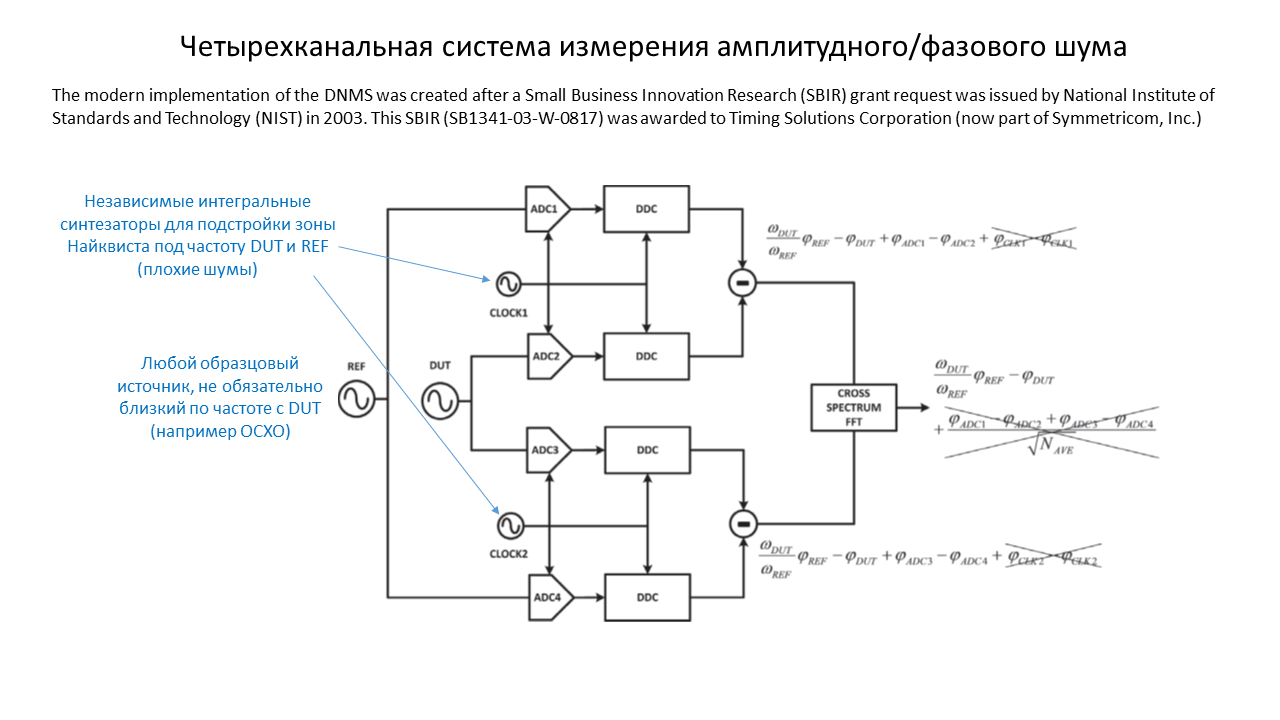
не лучше ли использовать сдвоенные АЦП (1 и 2 и отдельно 3 и 4), прав ли я, что идентичность в паре даст преимущество?
Согласен с преимуществом, когда попарно в одном кристалле, на это и рассчитан четырехканальный вариант построения.
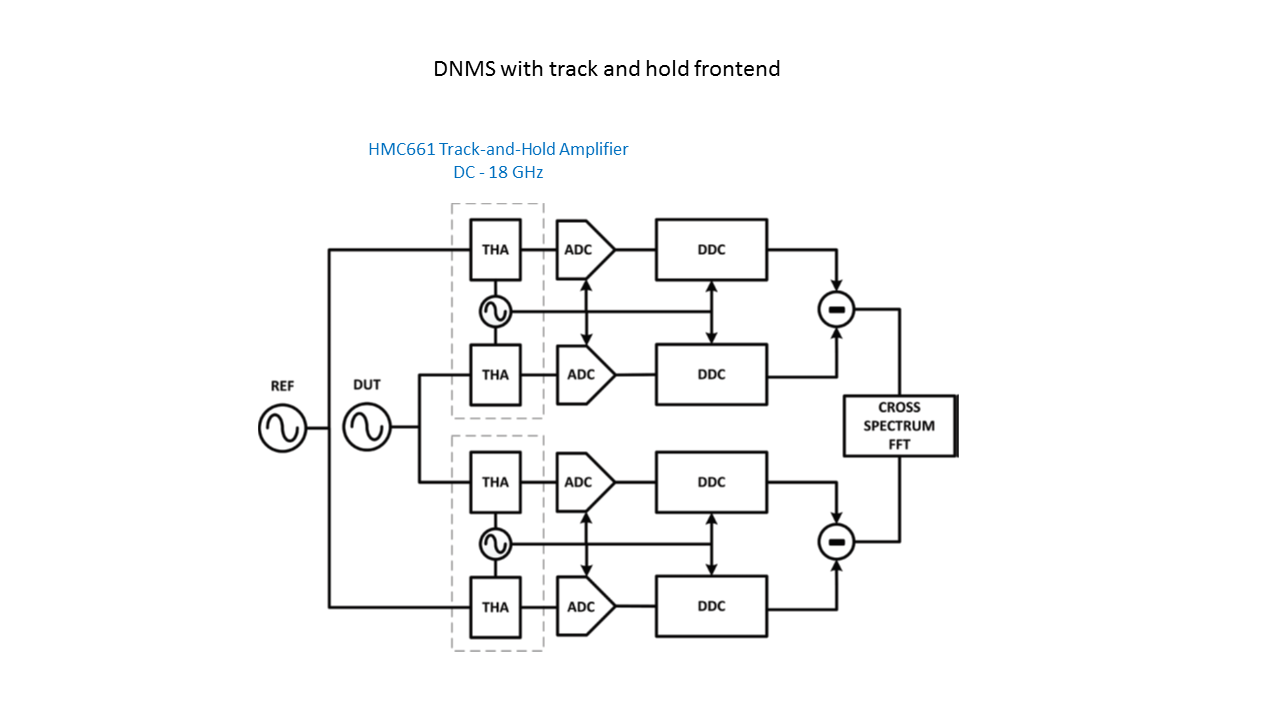
В THA, можно ли использовать NLTL для генерации гармоник? И еще, THA нужны для работы с более высокочастотными источниками?Внутри THA есть свой генератор коротких импульсов (фронтов). NLTL хорош в паре с широкополосным смесителем, по аналогии с SPD (Sampling Phase Detector). По THA хорошо написано у Hittite, HMC661.
Нужны ли фильтры (антиалиасинг) на АЦП?В общем случае нужны, Symmetricom, как помню, использует фильтры. Обычно для измерителя ФШ не ставится задача селекции от соседних каналов, т.е. функции фильтрации (тот же антиалиасинг) лежат на пользователе. Широкополосный шум при стробировании будет заворачиваться в полосу полезного сигнала. Фильтры бесспорно усложняют конструкцию, но попытаться уйти от них можно, например, как предлагает Александр, за счет некоторого смещения по частоте/фазе тактовых сигналов АЦП или синтезаторов, осуществляющих перенос частоты:
Значит в каждой корреляционной точке можно слегка изменять частоту (можно по случайному закону).Конечно это требует дополнительных исследований, поэтому не избежать корректировок в одну или другую сторону.
Не совсем понятно, как сюда вписываются синтезаторы, если использовать 100 МГц OCXO в качестве REF (что ставить в нижних каналах, где сейчас показаны ТНА)?Вместо THA - смесители, OCXO - заменить на более высокочастотный источник, или как писал Шаманъ, перейти к двухканальной схеме, в этом случае хорошо реализовать квадратурный перенос частоты. Вопрос с фильтрацией сразу упростится, можно полностью отказаться от фильтрации. В разных вариантах 4-х канальная система даст свои преимущества, значит нужно закладывать в базу.
Сейчас на E5052 это фактически делаешь сам в ручном режиме. Если надо померять малые шумы на дальних отстройках, то запускаешь шкалу отстроек от 1 кГц (больше почему-то не позволяет) и тогда корреляции накапливаются довольно быстро.Где-то видел патент на этот прибор. Вроде есть там разбивка на диапазоны, но похоже количество накоплений указывается для стартовой частоты, для более высоких - соответственно больше. Есть еще переключение между узким спаном и широким (разные режимы) - все это не от хорошей жизни, а от уровня элементной базы на момент создания.
rlocСкажите, как у Вас с макетом для LC генератора, есть ли результаты?
В верхних строчках плана, после закрытия обязательств по другим задачам. Приблизительно через 1-2 недели. Пока прорисовано и посчитано, возможно воспользуюсь помощью коллег, чтобы ускорить процесс. Когда макет рядом, легче в интерактивном режиме подкорректировать.
-
как Вы относитесь к упрощенному варианту с двумя АЦП, в котором сравнение фазы идет с "идеальным" сигналом (а не с полученным второй парой АЦП)?
Размышления такие. В четырехканальном варианте измеряемый и образцовый сигналы проходят одинаковые пути с одинаковыми нелинейностями. Добавочный шум, после преобразования на нелинейностях, вычитается на выходе без потери чувствительности. Эти тонкие материи можно увидеть только на практике, пока приходится доверять опыту людей.
Даже если взять смесители вместо THA, то казалось бы при полном сходстве LO и RF, уровни сигналов подаются разные (на LO - с ограничением, на RF - на линейном участке), и набегают шумы преобразования.
-
Ребята
Жень, что случилось? Не думаю, что у Александра все гладко и сладко. Если есть возможность вернуться в Анритсу, буду очень рад. Измерительная техника - одно из самых наукоемких направлений, есть где развернуться творческому человеку.
-
Я сторонник отправить все по максимуму на обработку на ПК, тем более, что 100МГц полоса анализа мне не нужна, а до 10МГц обработка на ПК не должна вызывать проблемы.
Все обсуждаемо.
Интересно зачем они нарисовали независимые генераторы для тактирования АЦП?Можно и одинаковую, для цифровой обработки легче. Если АЦП внутри одной микросхемы, то нужно обязательно разносить по фазам или частотам. Я сторонник разделения по разным корпусам и хорошей фильтрации по питанию, но даже в этом случае не избежать связи через входные цепи, где чаще используют резистивные делители мощности.
-
Это понятно, задача в принципе не слишком сложная (в вычислительном плане) весь вопрос в объеме FPGA и, соответственно, цене.
300 Eu за простенький модуль с Zynq US+ c 1GB 32bit DD4, контроллером Ethernet и USB, и необходимым количеством выводов для подключения нескольких АЦП с частотой 100-2600 МГц - много по цене? Есть более дорогие и производительные в таком же форм-факторе. Возможно есть дешевле на других семействах FPGA, детально не смотрел.
Для обсуждения предлагаю следующий вариант решения:
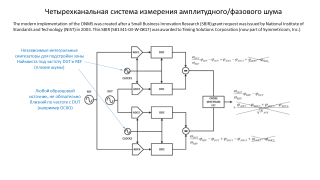
Один из путей расширения диапазона (на мой взгляд не самый оптимальный):
1. Добавлением широкополосных THA.
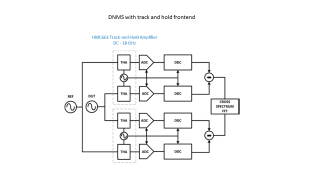
Другие варианты развития:
2. В качестве THA - строб-смеситель на базе ГГ на транзисторе и широкополосного смесителя (отправная точка - SIM-153LH+, потом - Marki).
3. В качестве THA - строб-смеситель на базе формирователя коротких импульсов (HMC705) и широкополосного смесителя.
4. Применение более скоростных ADC с широкой входной полосой (встроенный THA).
5. Добавлением двух независимых малошумящих синтезаторов (подстройка по частоте и фазе не нужна, а это большой плюс).
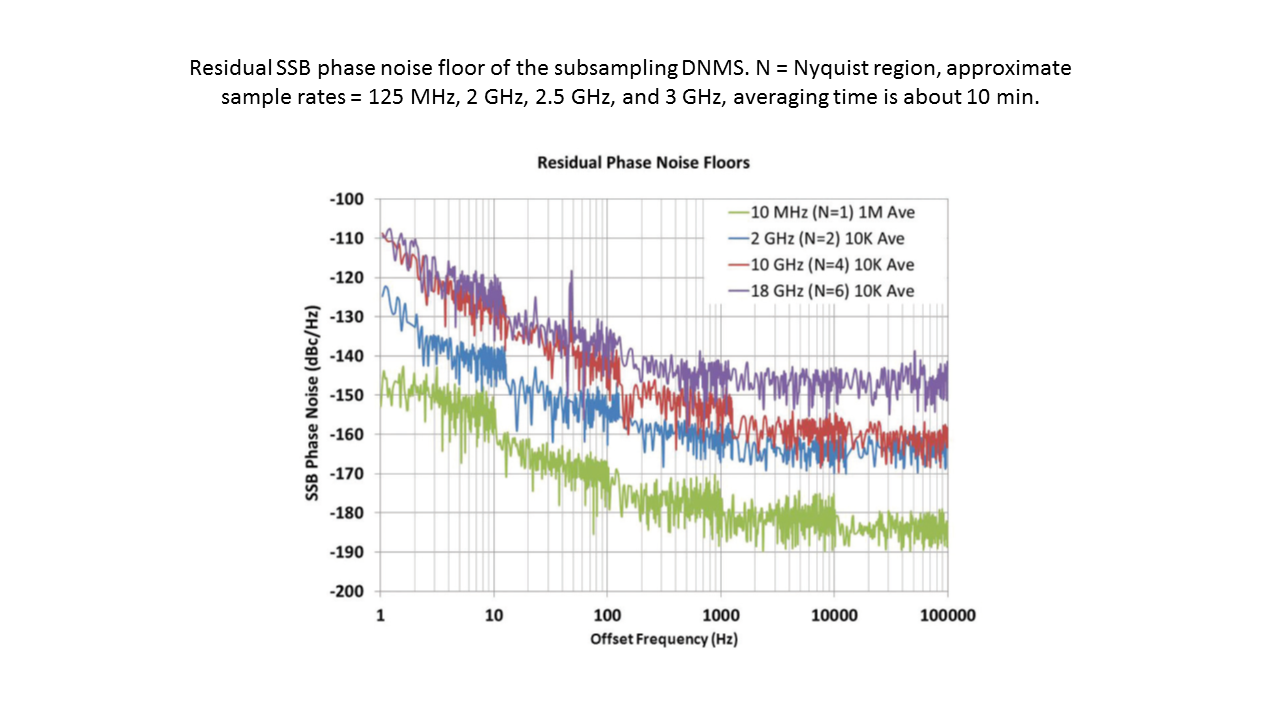
Результаты c HMC661 (прошу учесть, 2003-2004 год, ADC 2-3 GHz 8bit):
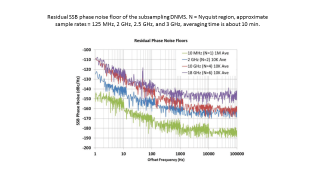
Статья в оригинале: 2650.pdf
-
Если несколько урезать аппетиты по полосе анализа (или пожертвовать временем измерения), то для удешевления всю обработку можно сделать на ПК. Не вижу, чтобы просто децимация на FPGA, без БПФ, дала существенные преимущества, вот если там же сделать БПФ...
На FPGA можно попробовать сделать ДПФ сразу в логарифмическом масштабе, допустим на 1024 точки. Производительности хватает на такие операции. При этом в каждой частотной точке будет наибольшее накопление за определенный интервал времени, а кривая на экране будет плавно приближаться к уровню измеряемого источника.
В принципе можно еще несколько плюшек добавить типа FLL цепи для измерения ФШ дрейфующих по частоте источниковХорошо PLL и FLL делать в цифре, чтобы не добавлять лишних шумов, поэтому вариант без синтезаторов более привлекателен. Речь о Symmetricom и NIST.
-
1. Базовый блок две микросхемы АЦП типа AK5397, полоса до 384 кГц, -173 дБн/Гц без кросс корреляции
По данным из даташита получается не лучше -164 дБн/Гц
2-4 канальный анализатор спектра, измеритель нелинейных искажений, АЧХ, ФЧХ, декодирование АМ, ФМ, SSB.Тогда я пас в этом проекте.
Предлагаю остановиться на измерителе ФШ+АШ+Power с логарифмической шкалой от несущей в полосе АЦП (мульти-Найквист), широкой, один Найквист = 50-200 МГц. Итоговая полоса может быть до 1.5 ГГц в относительно недорогом исполнении. С СВЧ частью, приемом и декодированием каждый решит сам, как продолжить. По структуре можно заложить разные варианты развития. Задачи приема и измерения ФШ не всегда оптимальны в одном устройстве. В измерителе ФШ, на мой взгляд, вполне допустимы спуры 60-70 дБн.
-
Я лично, могу участвовать в 1-5, 7, 9, 11, 15.
Мои пункты практически совпадают, добавляю п.12. Можно добавить п.13 если сделать в Matlab и найдутся желающие написать драйвер к железке.
Если нужен только логарифмический масштаб по частоте, то в обработке ничего сложного нет - это несколько этапов децимации (разбил бы на октавные диапазоны) на простой FPGA.
Fвх = 10 МГц – 20 ГГц+DC
Чувствительность: -200 дБн/Гц на 100 МГц, отстройка 10 кГцСерьезная цифра, придется отказаться от сравнения с синтезаторами. Есть такие измерители.
в России измеритель ФШ будет народным при цене 100-200 долларов США.Для меня было бы достаточно чуть выше себестоимости.
-
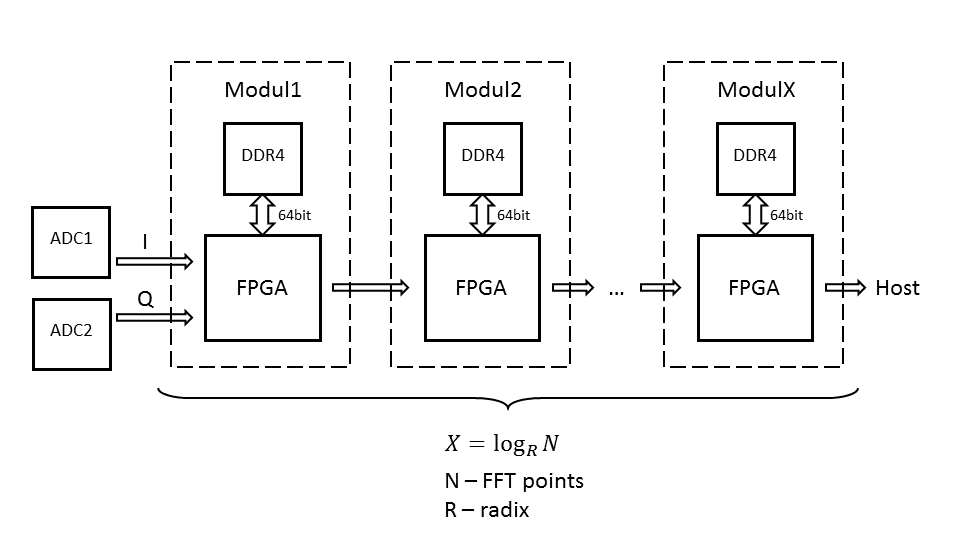
Pipeline FFT Radix-4 на 64k комплексных точек влазит в XC7K410T
Ближе к этапу проектирования станет понятно, как проще и дешевле. 64К и 500МГц - это не конечная цель, можно и больше, важнее иметь масштабируемую структуру, чтобы начать с простого преобразования на 1К и дальше развить до 16M (как пример). На текущий момент необходимо понять, что лучше подходит для потоковой обработки:
1. Можно ли сэкономить на промежуточном хранении данных, чтобы остаться в рамках 1К-16М внутри одного кристалла? Разумная ширина внешней памяти допускается. Понятие разумности определяется количеством выводов BGA. Мне кажется, нужно ограничить размерность FPGA количеством выводов не более 900. Если выше - существенно растет время компиляции и верификации, да и разработка самой платы может оказаться не простой задачей, тогда лучше перейти ко второму варианту.
2. Сократить сроки разработки и отладки за счет некоторой избыточности железа по объему и производительности, но применению простых унифицированных модулей и простых алгоритмов обработки, пусть с большим количеством операций сложения и умножения. Возможно это и есть золотая середина между GPU и FPGA.
-
будем делать универсально и модульно
Да, раз есть готовое и вкусное.
смотрим структуру FFT R22.Спасибо, посмотрим. Насколько сложно в алгоритме сделать переменную длину?
Структура FFT R22 считает семпл за тактВыравнивающие задержки есть? Какой длины? Зависят от длины преобразования?
ПЛИС одна.Память: 4 контроллера DDR3-1600 - 32х, 64х, 64х, 32х; HMC - полтора линка (х8 - слева, х16 - справа ПЛИС).
Наружу: PCIe Gen3 ext x8, PCIe Gen3 ext x4, HMC - два линка х16, serdes - два линка х4 (один слева, другой справа ПЛИС).
Очень тяжелый проект, и физически и морально.
-
На GPU в потоке не получилось - думали-смотрели, но не влезло (а может не осилили). Пришлось плисоводить :).
Подсознательно кажется с GPU больше "подводных камней" и на начальном этапе они могут быть не видны. Нет прозрачности в пути ADC->PCIe->GPU->PCIe->Host.
Сейчас на Kintex Ultrascale 16 реальных каналов (семплирование ~118МГц) получилось на 4М бинов по ~7Гц с перекрытием 25%.Пробежимся по структуре? RobFPGA, подключайтесь. Набросал по-быстрому схему, могу ошибаться, поправляйте:
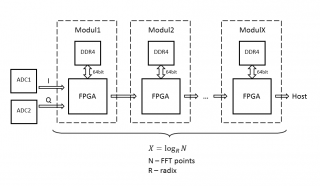
Подумал, действительно, закладываться на один "жирный" FPGA смысла не имеет. В модульной структуре легче обеспечить большую ширину памяти, ПО модулей может быть одинаковым, соответственно меньше времени на компиляцию и верификацию, выше частота работы. Последовательная структура мне показалась более удобной с точки зрения передачи данных (pipeline). Есть два вопроса:
1. Ширина полосы памяти на один модуль.
По самым оптимистичным оценкам достаточно обеспечить тройную (запись, чтение, коэффициенты) ширину входной полосы с ADC, приведенную к ширине внутренней арифметики.
2. Перектрытие.
За счет чего обеспечить? За счет увеличения кол-ва модулей или гарантии более высокой скорости обработки?
-
для БПФ сделать оценку требуемой производительности не составляет труда.
Так нужны не расчеты, а примеры реализации с конкретными цифрами, с оптимизированным кодом под определенную задачу. Зачем GPU тестируют на каждой игре отдельно?
-
Московской ISYS.
БукоФФки не хватает. Знаком с компанией ни один десяток лет. Как раз недавно ведущий разработчик делал доклад в тему:
https://www.youtube.com/watch?v=pmLUZ8hFoa0
-
2*16*500 = 16ГБит/с
Решил, что ограничение в 3 Гбит/c (в конкретном примере) было больше связано с интерфейсом, по первым ответам.
По моим расчетам, узким местом в GPU может быть ограниченная полоса памяти и возможность ее эффективного использования в случае рандомного доступа. Насколько эффективно компиляторы могут оптимизировать алгоритм - для меня темный лес, что и хотелось выяснить, с экстраполяцией результатов на Pascal GP100/Radeon RX Vega с памятью HBM2 2048 бит.
делал похоже на 4 Virtex - 2 канала 16 бит/250MHz, 16K FFT с перекрытием 50%, с кросс-кореляцией и с накоплением.С удовольствием посмотрел бы на рабочий образец в действии ) Продолжение было?
-
В моем случае данных в хосте изначально нет, сначала плата оцифровки должна передать их по шине PCIe, и возможно, если она умеет быть мастером, то напрямую в GPU. Вопрос, что является узким звеном в этом обмене?
в перспективе до 15 Гбит/сОткуда берется эта цифра?
-
На DSP закладываться опасно, основная проблема - в гибкости проектирования. Скажем, захочу перейти на radix-16, radix-32 ... Что делать в этом случае? Не позволяет DSP разменивать память на вычислительные ресурсы. С GPU чувствую такая же проблема будет.
-
главной проблемой, таким себе «бутылочным горлышком» остается обмен данными между хостом и девайсом
Вы можете сказать, чем определяется производительность обмена данными?
Перейду к конкретике. Допустим, есть 2 квадратурных канала сбора данных по 16 бит, частота 100 МГц (в перспективе больше, до 500 МГц и выше). Квадратурные каналы - аналоговые, нужно предварительно подкорректировать смещение нуля, фазы и амплитуды. Потом - FFT с заданным количеством точек (для конкретики - 64К), матобработка между каналами, накопление. На выходе - поток не большой, возможно в разы меньше входного. Насколько легко современные GPU способны "переваривать" такие задачи? В первую очередь конечно интересует скорость FFT, в идеале - с 50% перекрытием, в худшем случае - с минимальными разрывами в обработке.
длинные поточные FFT удобно делать на ПЛИСах.Да, в части FPGA мне все более-менее понятно, по гибкости и ширине полосы памяти (внутренней) возможностей значительно больше.
-
Коллеги, подскажите, какой максимальной производительности можно достичь на современных GPU при вычислении FFT 64К комплексных точек, 24 бит, radix-4 или более, с одинарной и двойной точностью? Среда разработки не имеет значения, нужно понять потолок производительности, с учетом полосы памяти. Если GPU умеет вычислять в потоке (streaming), то интересует минимальное время между загрузкой новых данных и выгрузкой обработанных.
-
А простые решения по части СЧ думаю сильно угробят ДД приемников и потребуют очень много корреляций => много времени, чтобы получить что-то приличное, ведь чтобы опуститься на 20дБ вниз с полосой анализа 10Гц потребуется минут 20 времени.
Если разбить диапазон отстройки на декадные куски (как пример) с полосами анализа 10-100-1000-... Гц? Тогда и динамика (приведенная) при удалении от несущей будет расти быстрее в sqrt(10)-sqrt(100)- ... раз, за счет большего числа накоплений. В идеале было бы хорошо изобрести дециматор с дробным коэффициентом, чтобы в каждой частотной точке иметь наибольшую динамику. В этом случае динамика АЦП уходит на второй план. В E5052, как помню, при больших отстройках накопление включено автоматически, даже при N=1, и на время анализа не влияет.
P.S. Сделал второй LNA на AD797 и увидел тепловой шум резистора 51Ом :)Красота! Насколько сложно сделать реалтайм обработку в Матлабе со ЗК? Было бы удобнее, чем с готовыми программами, по гибкости. Не хватает простого инструмента измерения шумов DC с корреляцией.
100 Ватт - модуль на Kintex UltraScale KU115
в Работаем с ПЛИС, области применения, выбор
Опубликовано · Пожаловаться
Просветите, для каких задач нужны такие мощности (вычислительные)?