


nice_vladi
Свой-
Постов
383 -
Зарегистрирован
-
Посещение
Весь контент nice_vladi
-
Сначала всё в одном модуле лепил. Потом начал выносить в отдельные таски. Последний этап до UVM - собрал некоторое подобие UVM. С внешними классами, интерфейсами и т.д. Посмотрел внимательно, понял, что изобретаю велосипед, и решил попробовать UVM. Пока решил следующим образом. В тесте: for (int i = 0; i < pN_PORTS; i++) begin eth_seq[i] = eth_sequence::type_id::create($sformatf("eth_seq[%0d]", i)); eth_seq[i].randomize(); eth_seq[i].dmac = pMAC_DST[i]; end ... eth_seq[i].start(m_env.m_agent[idx].m_sqr); ... В sequence: virtual task body(); frame_h = eth_frame_broad::type_id::create("frame_h"); start_item(frame_h); assert(frame_h.randomize()); frame_h.set_dmac(dmac); finish_item(frame_h); endtask : body И внутри самого uvm_sequnce_item: function set_dmac (bit [47:0] mac); this.dmac = mac; this.fcs_upd(); endfunction : set_dmac На мой взгляд, достаточно коряво. Но, в целом, приемлемо. Все изменения будут сделаны в высокоуровневых файлах тестов, в глубь лезть не надо. В мануалах не нашел ничего интереснее. uvm_config_db более громоздко и менее производительно (основываясь на рекомендациях из док).
-
Я буквально недавно начал серьезно погружаться. После того, как разрабатываемое тестовое окружение выросло до неприличных размеров и стало не управляемо и не масштабируемо. Здесь, конечно, есть проблема и кривых рук. Но отлаживать и, самое главное, верифицировать Н-портовый Ethernet коммутатор стало почти физически больно. От UVM ожидаю получить более-менее структурированное окружение, облегчение описания и проведения наборов тестов, упрощение работы с недетерминированным порядком передачи и задержками в данных. Плюс встроенные инструменты подсчета ошибок, репортов и т.д. Насколько это всё спасёт и упростит верификацию - пока не знаю, время покажет.
-
Всем здравствуйте, Разбираюсь с UVM. В какой-то момент перешел к "боевому" проекту. Задача следующая: Нужно передать в GMII порт(-ы) набор Ethernet пакетов. В каждом пакете существуют поля mac destination и mac source. Поле mac source допускается задавать статично на этапе сборки, с этим проблем нет. Я хочу динамически менять поле mac destination. На текущем этапе в классе uvm_sequence_item я состряпал функцию set_dmac (bit [47:0] mac). Не уверен, что это правильный способ. Да и не слишком удобно - приходится вызывать эту функцию в uvm_sequence, куда, в свою очередь, опять нужно динамически передавать нужный MAC адрес. Собственно, вопрос: как, с точки зрения UVM, правильно изменять значения в uvm_sequence во время runtime? ЗЫ. Открыл для себя `uvm_do_with, поэтому часть вопроса снимается) ЗЗЫ. Пока писал, немного посветлело в голове. Пришел к выводу, что под каждый порт должны создаваться несколько sequence со статичными MAC source. И уже в них передавать MAC destination. Выглядит логично, хотя и очень громоздко
-
Цели и задачи всегда важны. Смотрите: Хотите ускорители на ПЛИС реализовать? Тогда hdl/hls. Хотите на видеокартах считать? Тогда python/C + CUDA и иже с ними. Хотите на серверах что-то делать? Там python массово распространён. В общем, на чем хотите - на том и пишите. Хоть на Deplhi, никто же не ограничивает. Сделать-то что надо?)
-
Слышал, их даже на *HDL пишут. Все зависит от целей.
-
Тоже руками крутил delay в IO портах. И тоже *иногда* собиралось так, что паттерн передавался без ошибок. После кучи убитого времени пришел к тому, что всё это самообман, и "рабочие" сборки - просто удачно разложенные регистры, чисто случайно. Но, может быть, у вас получится чего-то добиться. Будет интересно прочесть про рабочий вариант. ЗЫ. А тестовый паттерн сколько времени проверяли? Сколько бит тестового паттерна принимается подряд без ошибок? 10^5? 10^9?
-
Встречался с подобной проблемой - сигналы были заведены на низкоскоростные ноги ПЛИС, и все танцы с бубном вокруг констрейнов ни к чему не приводили. Поэтому сначала надо посмотреть, на какие ноги заведены сигналы. Кстати, а тестовый паттерн верно принимается? Нет ошибок?
-
Попробуйте это: https://bit.ly/3zRMRiL
-
Есть неплохая статейка от ребят fpga-systems.ru: https://fpga-systems.ru/publ/jazyki/systemverilog/uvm_test_tablicy_sin_cos/13-1-0-120 Там на пальцах создание tb + UVM как раз для вивадовского симулятора, мб что-то почерпнете оттуда. В конце есть ссылка на репозиторий, можно качнуть и запустить. У меня на Vivado 2020.1 проект запустился сразу, без проблем.
-
В генераторе IP ядра на последней вкладке можно поставить галочку, которая отвечает за генерацию .bsf/.bdf файла, который и будет блоком-символом
-
Дикий оффтоп, но меня, почему-то, очень восхищают такие названия. "Целевая, прорывная, перспективная". Как это придумывают?!
-
Звучит очень близко к: DE1-SoC Board DE10-Standard
-
Ну да, так и есть. Поэтому новые Ryzen достаточно уверенно лидируют на такой задаче. Интересно было бы еще новый Threadripper погонять. По-моему, параллелиться умеет только Questasim. При это там надо не просто ключик какой-то передать симулятору, а именно писать тестбенч в несколько потоков, в общем, не тривиально.
-
Как-то проводил опыты на разных процессорах/ОС. За референс берется ПК с windows 7, 8 Gb RAM 1600MHz, i3 8го поколения, HDD 7200 rpm. Проект в Quartus 13.1, Cyclone III, 50 тысяч логики. забит на 90+ процентов. Начинаем тестировать: Перекладываем квартус и проект на SSD (~400Mbit/s) получаем -7-8% от времени сборки проекта. Берем вместо windows 7 ставим Ubuntu 18.04 получаем еще -7-8% от времени сборки. Это чисто относительные величины, в абсолютном времени на референсном ПК проект собирался около 2 часов, точно уже не помню. Выводы: нужен linux+SSD. Как минимум SSD, если к linux испытываете отвращение, либо в конторе не принято с ним работать. Так же совсем недавно проверял компиляцию на разных процах. Были Intel i5 9600KF, Intel Xeon Gold 6256, взял себе 16 ядер из 48, AMD Ryzen 5900х. Везде SSD. Референсный дизайн уже был другой, Intel MAX10, 50 логики, забитый на 95+ процентов. Время сборки: Ryzen 50 мин, i5 1 час 20 минут, Xeon 1 час 8 минут. Есть правда нюанс в отличии тактовой частоты RAM. В i5 и Xeon память была 2600 и 2934 MHz соответственно, а у Ryzen 3600 MHz. Выводы для себя сделал такие: частота всё, ядра ничто. Тем более, Quartus, Libero SoC и, вроде, Vivado не умеют больше чем с 8 ядрами работать. Да и place&route очень плохо параллелится. Даже при 16 ядрах можно видеть, что одновременно загружены только 1-2..-5. Так что, злой комп для разработки под ПЛИС на сегодня это: AMD Ryzen либо Intel i9 с топовыми в семействе частотами, число ядер не важно. 32+ Гб RAM предельной частоты, поддерживаемой процессором SSD >400 Mbit/s Linux Ну и видюшка какая-то, что бы встроенная не воровала у проца время Всё это, конечно, моё ИМХО, на истину не претендую. ЗЫ. Ну и, конечно, стоит отталкиваться от чипов, с которыми будете работать. Если там max10/CycloneIII по 10-20 тысяч логики, то вышеперечисленную конфигурацию можно смело делить на 2, а то и на 4) ЗЗЫ. А еще под Linux QuestaSim умеет в параллельную симуляцию) Правда для этого надо очень правильно писать тестбенчи.
-
С учетом того, что данные бинарные, очень похоже, что где-то с разрядностью промахнулись. И случилось переполнение.
-
Я бы попытался найти отладку от производителя и на ней попробовал бы получить характеристики. А потом уже разбирался со своим железом. Такой подход позволит исключить ошибки при разводке своей платы, в своем софте и т.д. А потом уже, когда получили характеристики на железе производителя, можно рисовать свое и сравнивать)
-
Диплом, который подкреплен работающей железкой - это 100% защита на 5. Во-первых. Во-вторых, собирая даже такую дорогую, и чего уж тут, неоптимальную и кривоватую (относительно промышленных образцов) железку вы получите уникальный, колоссальный и полезный опыт, который 100% пригодится вам в дальнейшем. А пытаться соревноваться с промышленными, серийными образцами не стоит. В них залиты годы человеко-часов. ЗЫ. Трансиверы от АД тоже нормальная тема. Если осилить схемотехнику и настройки, то это будет подешевле дискретного тракта.
-
Они SystemVerilog не поддерживают. Фтопку.
-
А какое количество отсчетов данных передаете в корку? Попробуйте параллельно с valid запустить счетчик. Или в этом режиме без разницы количество отсчетов на входе?
-
А почему именно альтеровский blaster? Чем не устраивает FT2232H, один порт которой настроен на JTAG? Или родной бластер/клон дают какие-то плюшки, которые не доступны через ту же FTDIку? ЗЫ. Неоднократно видел на отладках обычные FTDI или Cypress USB контроллеры, которые были настроены на JTAG и подключены к ПЛИС,
-
Не пользовал, но: Мануал говорит, что сигнальчиков разрешения не хватило. Смотрите, совпадают эпюры с требуемыми, мб где-то сигнал на фронт тактовой не попадает или типа того.
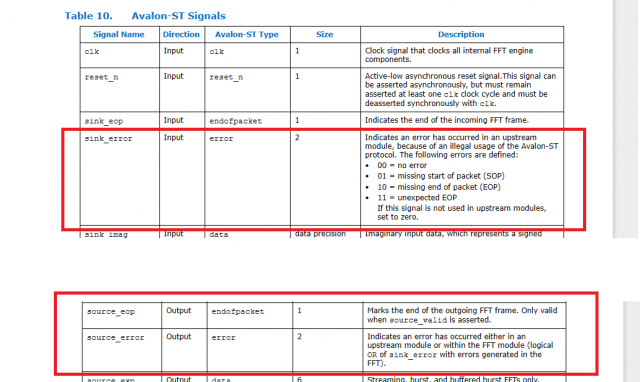
-
Интересно, по именам перечислят? Да, справедливости ради, про сами чипы я ни слова не нашел(
-
Кстати, про пристанища, есть ещё вот такое: https://ohwr.org/explore Тут даже дизайны плат публикуют
-
Там есть фраза "дать дом и пристанище различным open-source проектам для FPGA". Может быть, и синтезатор/placer будут развивать.
-
Open source FPGA foundation
nice_vladi опубликовал тема в Среды разработки - обсуждаем САПРы
Даёшь open source в ПЛИСы. Обещают демократизацию FPGA технологий. Интересно, они будут только open source софт продвигать, либо сами чипы (как-то) тоже? https://habr.com/ru/news/t/551858/
