Поиск
Показаны результаты для тегов 'vivado'.
-
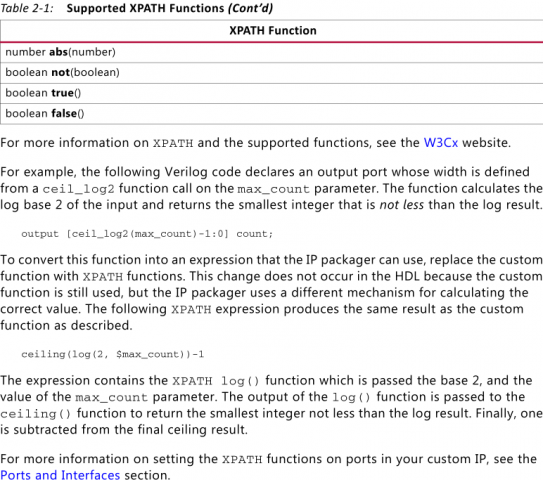
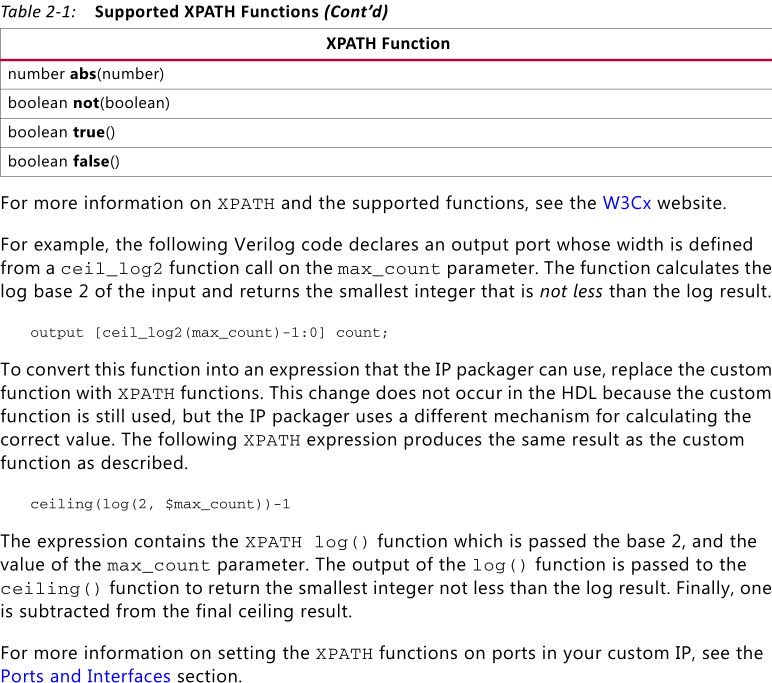
Здравствуйте. Нужно создать в Vivado IP Core, чтобы интегрировать его в Block Design и подключать к Zynq. Был неприятно удивлён тем, что не поддерживаются пользовательские функции (к примеру log2 для задания параметра ширины шины). На форуме Xilinx нашёл пару похожих тем (например, ), только вот решения так и не увидел. В основном описываются проблемы "парсера" IP Packager. Но вроде как в том же ug1118 Creating and Packaging Custom IP говорится о поддержке более сложных математических выражений при помощи XPATH функций: Вот только как и где использовать эти функции XPATH? Как ни пытался ничего не получилось. Даже в описываемом примере, как можно в Verilog коде "output [ceil_log2(max_count)-1:0] count;" заменить пользовательскую функцию ceil_log2 на некую XPATH функцию ceiling(log(2, $max_count)), у которой параметр $max_count описывается как в языке Tcl. Как понять фразы: Может знает кто, как собственно можно использовать эти самые XPATH функции? Или вообще, как кто боролся с кастомизацией параметров для ядер в IP Packager?

-
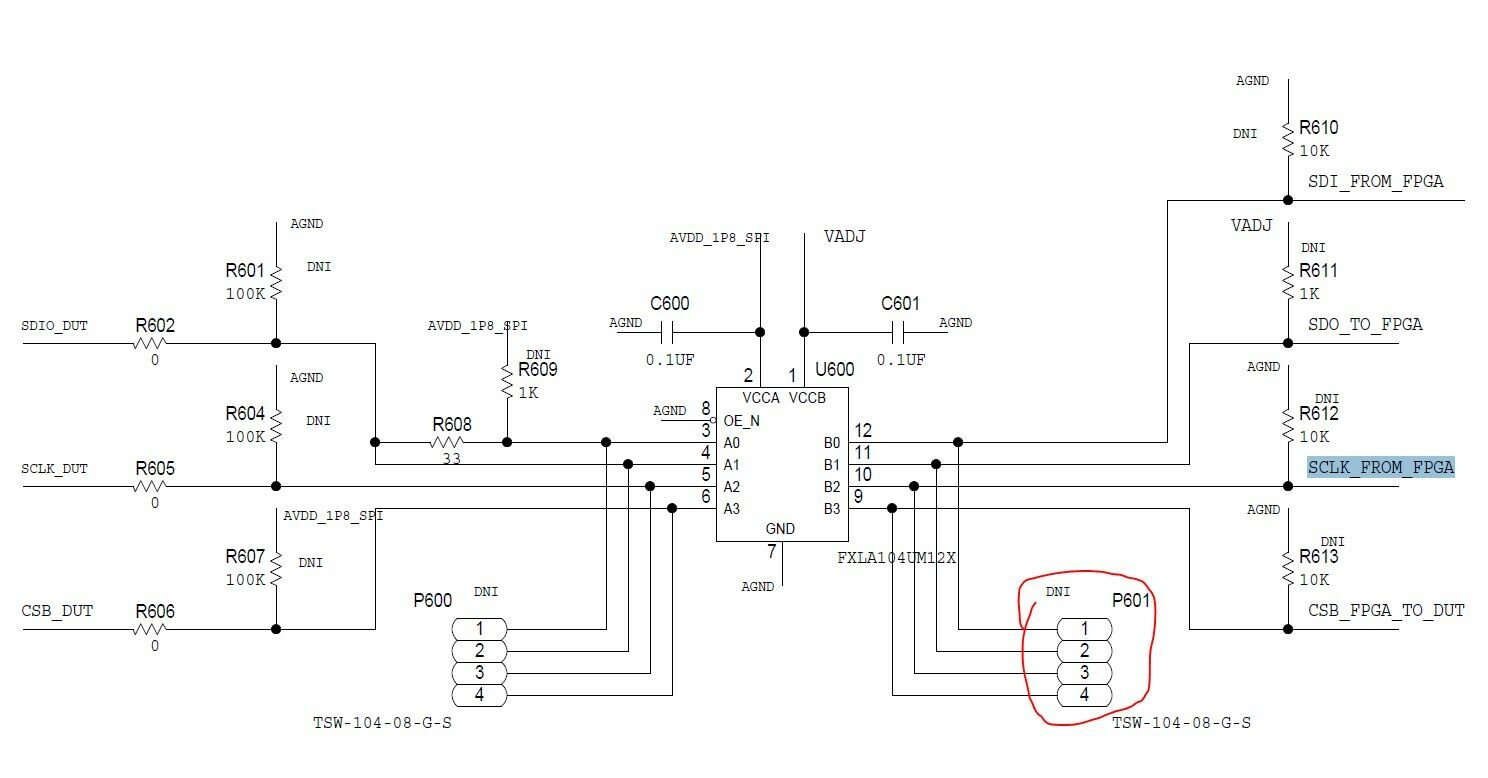
Захотелось поднять JESD на двух КИТах ZCU102 (Zynq Ultrascale+) и АЦП AD9695 1300EBZ Eval соединив их по FMC. С проектом никаких сложностей не возникло, ядра все быстро настроил, принялся работать, но микруха AD9695 молчит по SPI и никаких признаков жизни не подаёт. Стандарты протокола, сигналов и распиновку перепроверил много раз, проблем не увидел. На мезонине есть чудесная возможность отладки SPI через контрольные точки Осциллом, ей и воспользовался. Рис.1 - Часть схемы AD9695 Eval Ткнулся в контрольные точки и увидел странную картину. Сигналы "SDI_from_FPGA" и "SCLK_FROM FPGA" накладываются друг на друга и мешают корректно друг другу работать. Когда на шине SDI есть данные (уровень "1"), Клок на SCLK задирается и портится... Рис.2,3 - Осциллограммы на тестовых пинах (Сверху SCLK, снизу SDI); При этом сам клок фонит на данные превращая их в кашу. Рассмотрел более подробно схему и понял, что эти два пина являются ДИФФ парой на разъёме FMC (LA01_P_CC/LA01_N_CC) Рис.4 - Часть схемы AD9695 Eval (FMC) Думал в начале может проблема в настройках VIVADO и как то случайно поставил стандарт не тот на эти выводы, но нет. Стандарт явно обозначен "LVCMOS18" у всех пинов SPI. Залез на всякий случай в схематик в имплементации, там всё верно стоит на выходе "OBUF". О Дифференциальном выходе и речи нет... Кто знает, почему соседние сигналы могут портить друг друга? и что можно с этим сделать? Рис.5 - Мои настройки для пинов SPI в VIVADO Рис.6 - Схематик из VIVADO; PS: На всякий случай ещё уточню, что проблема точно не в мезонине или его разводке. Мезонин снимал и смотрел щупами прямо на FMC разъёме со стороны ZCU102. Картинка та-же. Такими сигналы идут из ПЛИС.






-
поток данных через 10GE
Drakonof опубликовал тема в Работаем с ПЛИС, области применения, выбор
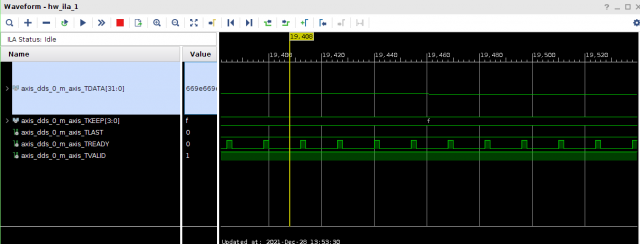
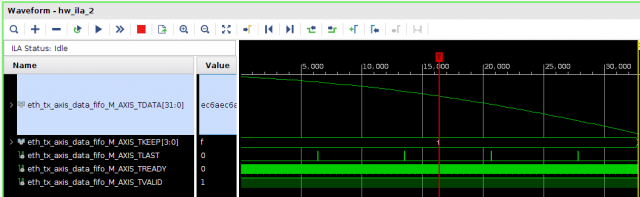
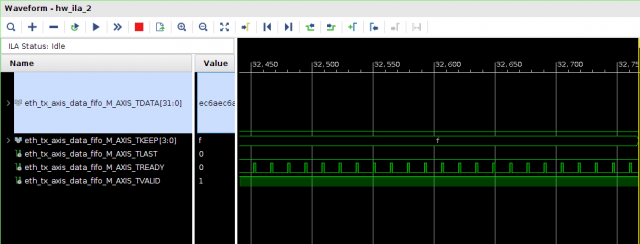
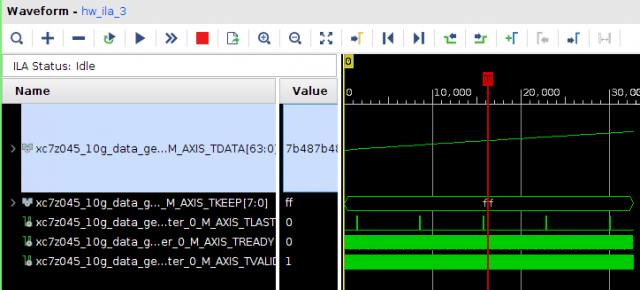
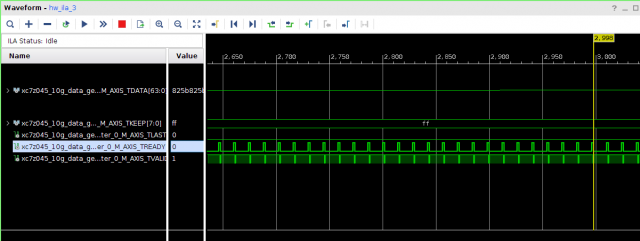
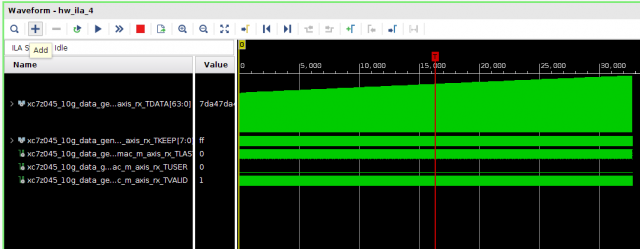
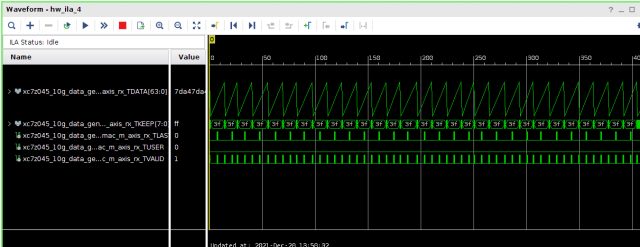
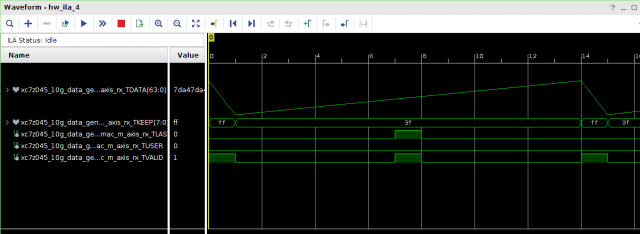
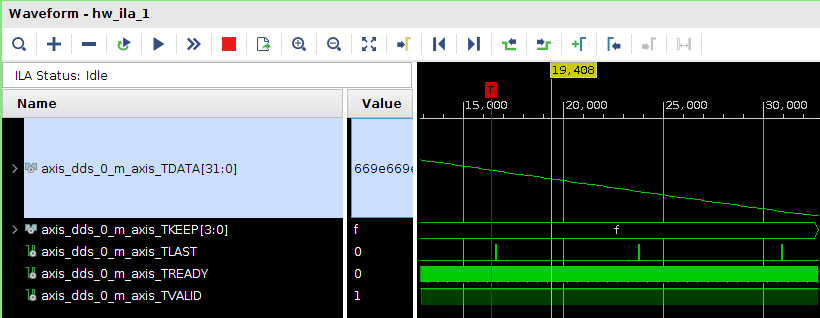
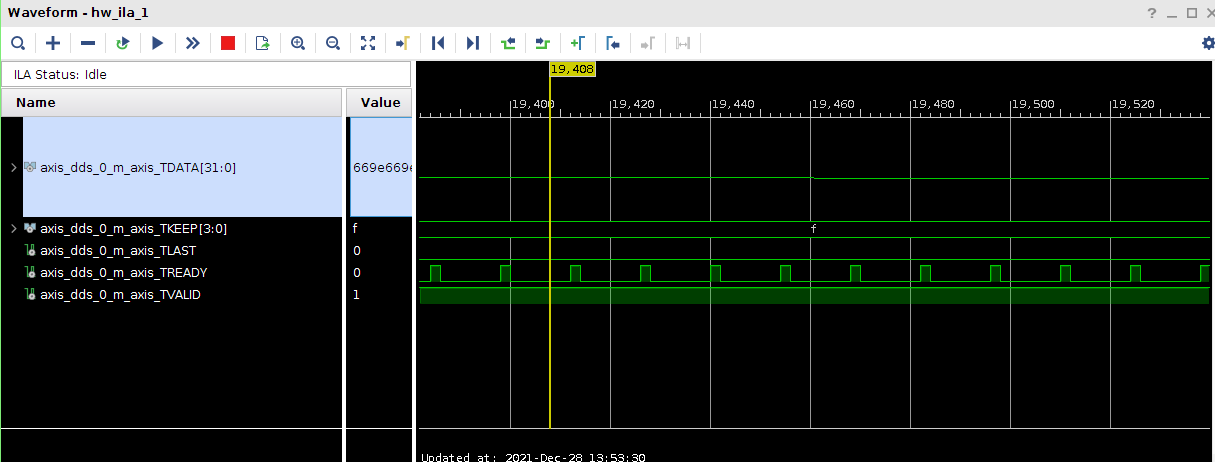
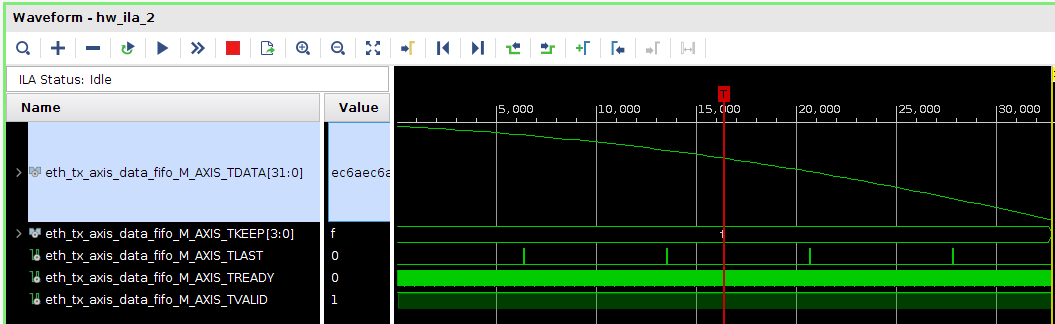
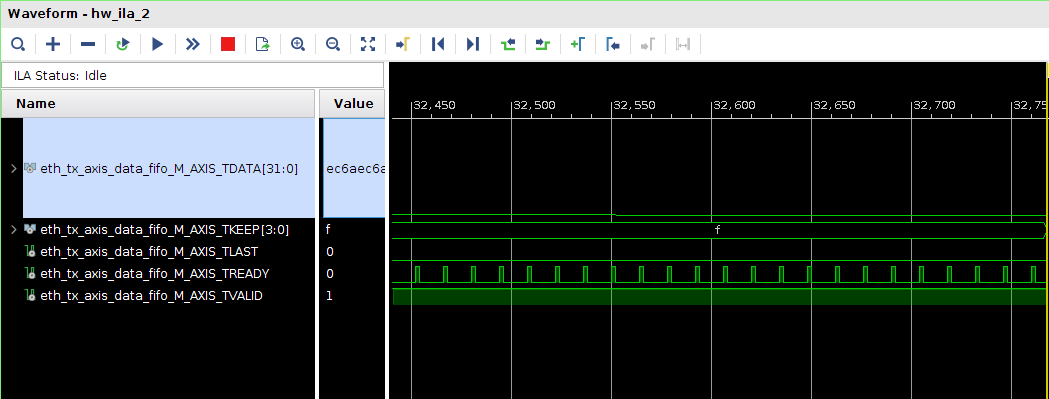
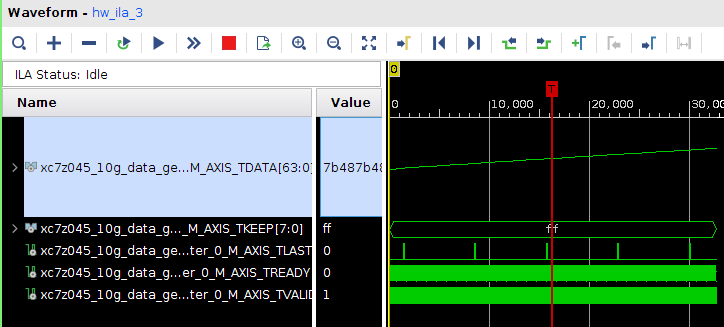
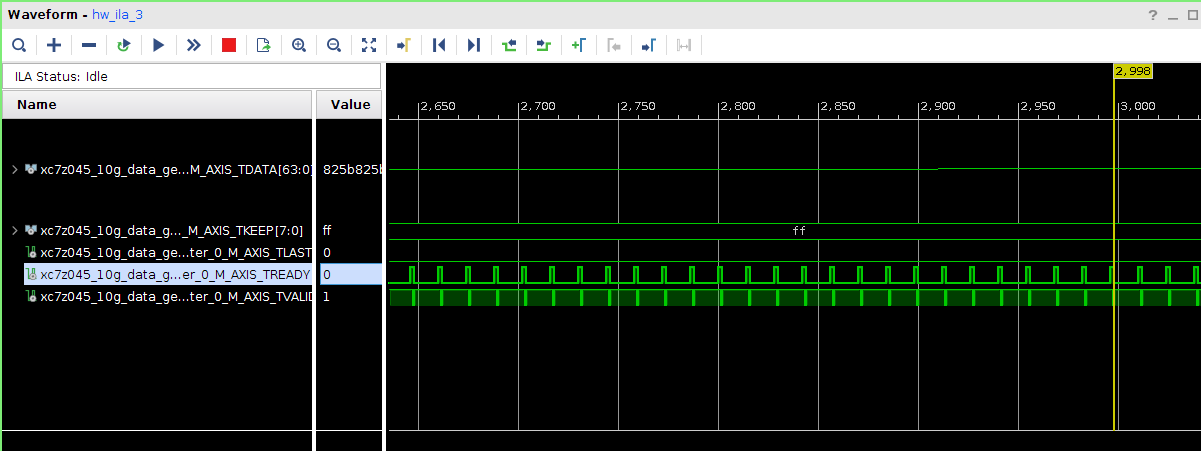
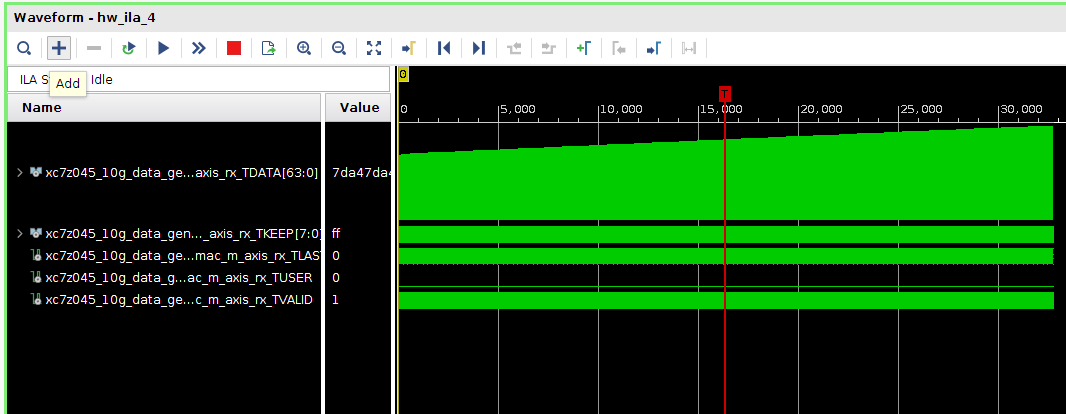
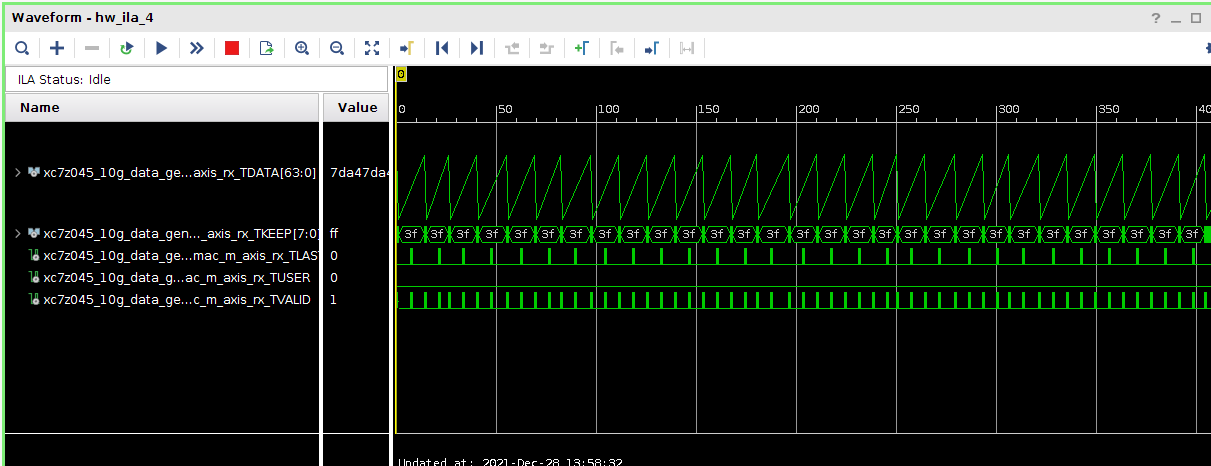
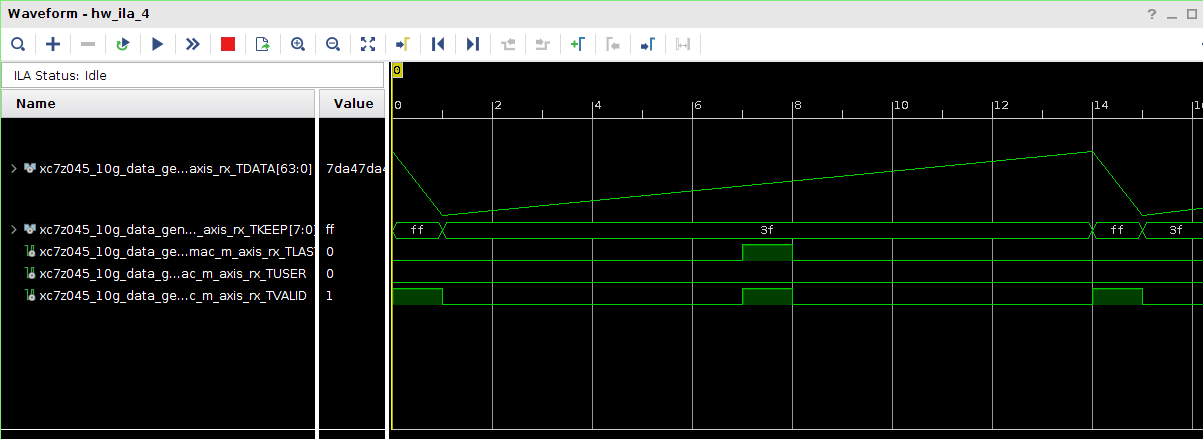
Всем привет! Друзья подскажите, почему принемаемые данные прореженны нулями. dds -> axis_fifo -> width_converter (32 -> 64) -> 10ge (mac + pcs/pma) -> axis_checker -> ila Тактовый генератор настроен и работает на 156.25МГц. ЕСли чегото не хватает говорите, дозалью) Заранее спасибо! dds -> fifo dds -> fifo зазумлен fifo -> width converter fifo -> width converter зазумлен width converter -> mac 10G tx width converter -> mac 10G зазумлен rx -> axis checker rx -> axis checker зазумлен 1 rx -> axis checker зазумлен 2 bd.pdf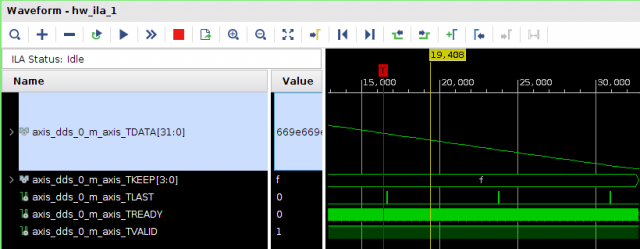
-
Компания Xilinx сообщила о выходе нового релиза программного обеспечения Vivado ML и Vitis версии 2021.2. Подробнее

-
вебинар Язык TCL в проектировании на Xilinx. Вебинар
МакроГрупп опубликовал тема в Объявления пользователей
Первый вебинар из серии – «Основы TCL» будет посвящен основным элементам языка TCL. Подробнее
-
вебинар Знакомство с экосистемой Xilinx. Вебинар
МакроГрупп опубликовал тема в Объявления пользователей
На вебинаре Вы узнаете, какие готовые устройства и отладочные платы существуют, какие фреймворки и библиотеки можно использовать для ускорения приложений и где найти всю необходимую информацию. Подробнее
-
Xilinx ADAPT EMEA. Онлайн конференция
МакроГрупп опубликовал тема в Объявления пользователей
Компания Xilinx c 9 ноября по 16 декабря 2021 года проведёт онлайн конференцию для регионов Европы, Ближнего Востока и Африки по адаптивным вычислительным технологиям Xilinx. Подробнее
-
Я написал функцию "memcpy" для копирования блока данных с исходного адреса на адрес назначения. Хочу протестировать на плате (Zynq). Я новичок в MCU и изучаю эту тему самостоятельно, извините, если мой вопрос для вас глупый. Что я сделал: Я создал проект в vivado, начал block design с Zynq, изменил конфигурацию PS-PL (добавил GP Master и Slave AXI Interface) [Смотри приложение]. Я читал, что Zynq может быть Master, но Slave/ периферийнoe устройство я должен спроектировать как настраиваемое IP-ядро. Я уже нашел, как создать собственный AXI IP (slave или master). Vivado создает шаблон настраиваемого IP-ядра (slave). (1) Могу ли я использовать этот шаблон без каких-либо изменений? (2) Следует ли мне добавить дополнительную информацию (сигналы, которые я использую в функции memcpy: адреса и количество битов)? Я пропустил дизайн custom master . (3) Я сделал правильно или мастер должен быть частью настраиваемого IP ядра?
-
Нужна помощь по SPI, DMA, Vivado
Nano2021 опубликовал тема в Работаем с ПЛИС, области применения, выбор
Здравствуйте! Я работаю над реализацией высокоскоростной передачи SPI и ищу лучший вариант для блока DMA. Схематическое изображение моей конструкции:прикрепил На сайте Xilinx я нашел следующиe блоки, который могу использовать: DMA Central Direct Memory Access DataMover 1. В чем разница между DMA и CDMA? Судя по описаниям и блок-схемам, это ... как будто потоковым устройством будет устройство, которое производит или потребляет поток байтов. Устройство с отображением памяти подключается к шине памяти. Таким образом, периферийному устройству, которое хранит входящие данные в регистре с отображением в память, потребуется CDMA, а периферийному устройству, где данные поступают непосредственно из буфера FIFO, потребуется DMA. 2. AXI Data Mover. Если я подключу его с блоком AXI FIFO Stream (параметры передачи команд), я получу блок DMA, как я понял. Этот блок дает мне больше свободы в реализации? 3. Какой вариант лучше всего для передачи данных из высокоскоростного SPI через DMA в память? Я бы хотел достичь 50-100 Мбит / с Заранее спасибо за вашу помощь
-
vitis Компания Xilinx представила релиз Vitis 2021.1
МакроГрупп опубликовал тема в Объявления пользователей
Компания Xilinx сообщила о выходе нового релиза программного обеспечения Vitis 2021.1. Подробнее
-
На сайте компании Xilinx размещена для скачивания версия среды разработки для ПЛИС и СнК Vivado под номером 2021.1. Подробнее

-
В данном вебинаре вы познакомитесь с основными особенностями нового поколения адаптивных систем Versal, с тем, какие среди них существуют вариации и в каких сферах их применение принесёт максимальную пользу. Подробнее

-
Всем привет. Мы проводим стримы по FPGA/ПЛИС тематике на твиче по адресу twitch.tv/fpgasystems Обычно, это среда и суббота в 20:00. Записи прошедших стримов лежат на youtube: youtube.com/c/fpgasystems Ждём Вас на стриме. Анонсы предстоящих эфиров в группе в телеграм @fpgasystems (https://t.me/fpgasystems) и VK и FB

-
Приглашаем на информационно практический вебинар «Решения Xilinx для интеллектуального управления электроприводом». На вебинаре будут рассмотрены решения Xilinx на базе систем на кристалле (SoC) для экосистем, в которые входят различные электроприводы. Эти решения обеспечивают не только оптимальное управление одним или несколькими моторами/электроприводами, но также осуществляют управление через Интернет, сбор и обработку аналитики в облаке, обнаружение неисправностей и даже предсказание времени их наступления. Зарегистрироваться

-
Временные ограничения (timing constraints) используются для задания временных характеристик дизайна. Временные ограничения влияют на все внутренние временные взаимосвязи, задержки в комбинаторной логике (LUT) и между триггерами, регистрами или ОЗУ. Временные ограничения могут быть глобальными или зависящими от пути. Для достижения требуемых временных характеристик проекта, разработчику необходимо задать набор ограничений для этапов синтеза и физической реализации, которые представляют собой требования, предъявляемые к заданным путям или цепям. Ими могут быть период, частота, перекос на шинах, максимальная задержка между конечными точками или максимальная чистая задержка. После синтеза или реализации достигнутые характеристики анализируются с помощью инструментов статического временного анализа Vivado. Статический анализ тайминга – это метод определения соответствия схемы временным ограничениям без необходимости моделирования, поэтому он намного быстрее, чем симуляция с учетом временных задержек. Инструменты Vivado STA проверяют настройки, временные характеристики (setup and hold time), ограничения синхронизации, максимальную частоту и многие другие правила проектирования. Статический анализ тайминга в качестве исходных данных принимает синтезированный список соединений либо физический список соединений проекта. На основе этих списков, алгоритмы Xilinx рассчитывают временные задержки и их соответствие задаваемым разработчиком требованиям. Запись вебинара:
.thumb.jpg.81a4945a234826d4eb04fb86119e9230.jpg)
-
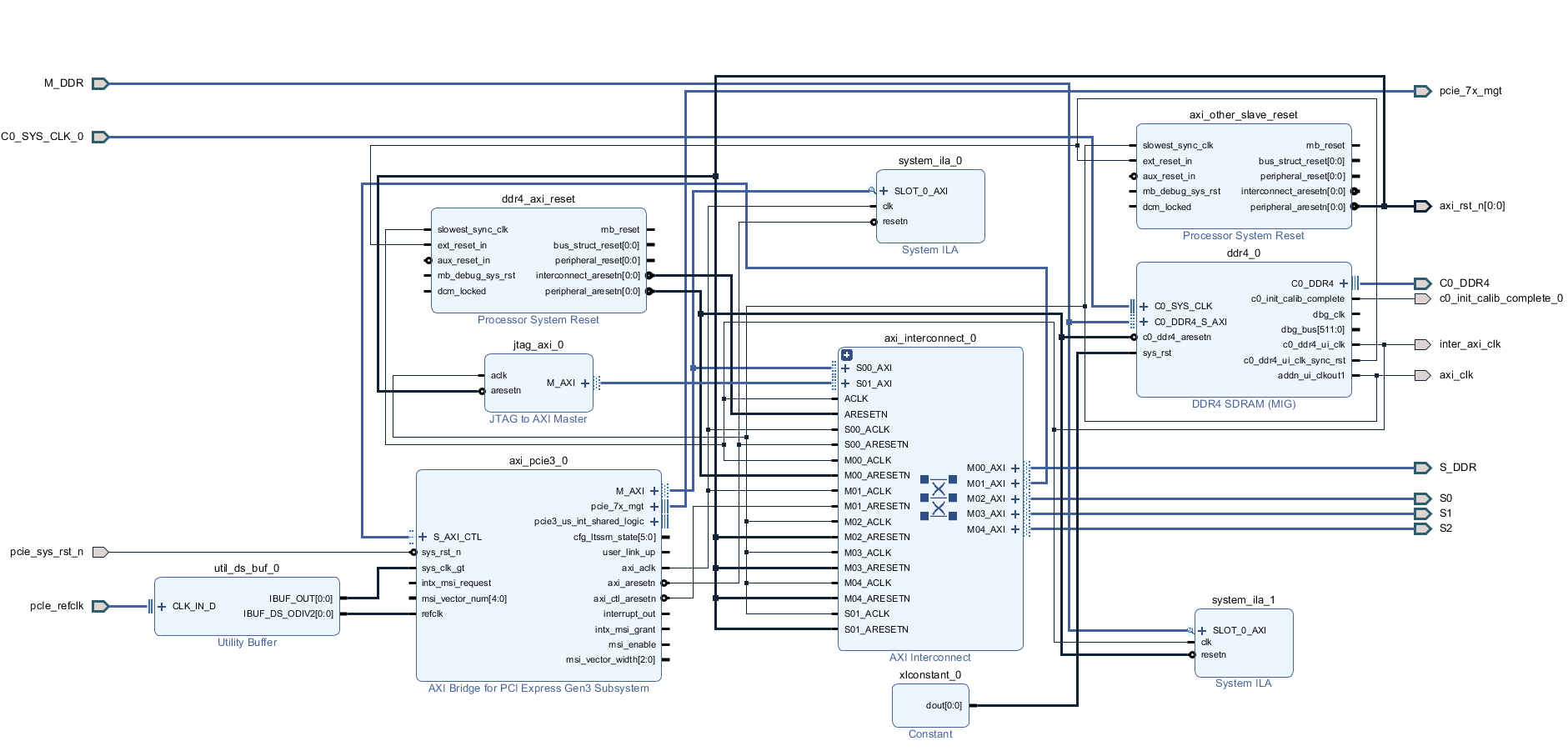
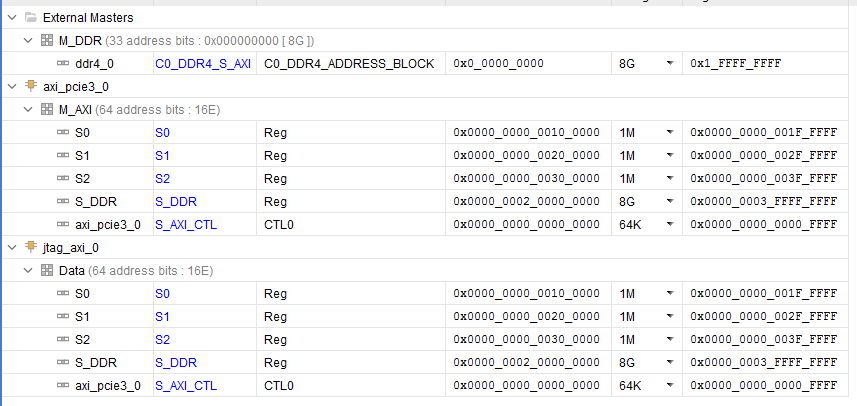
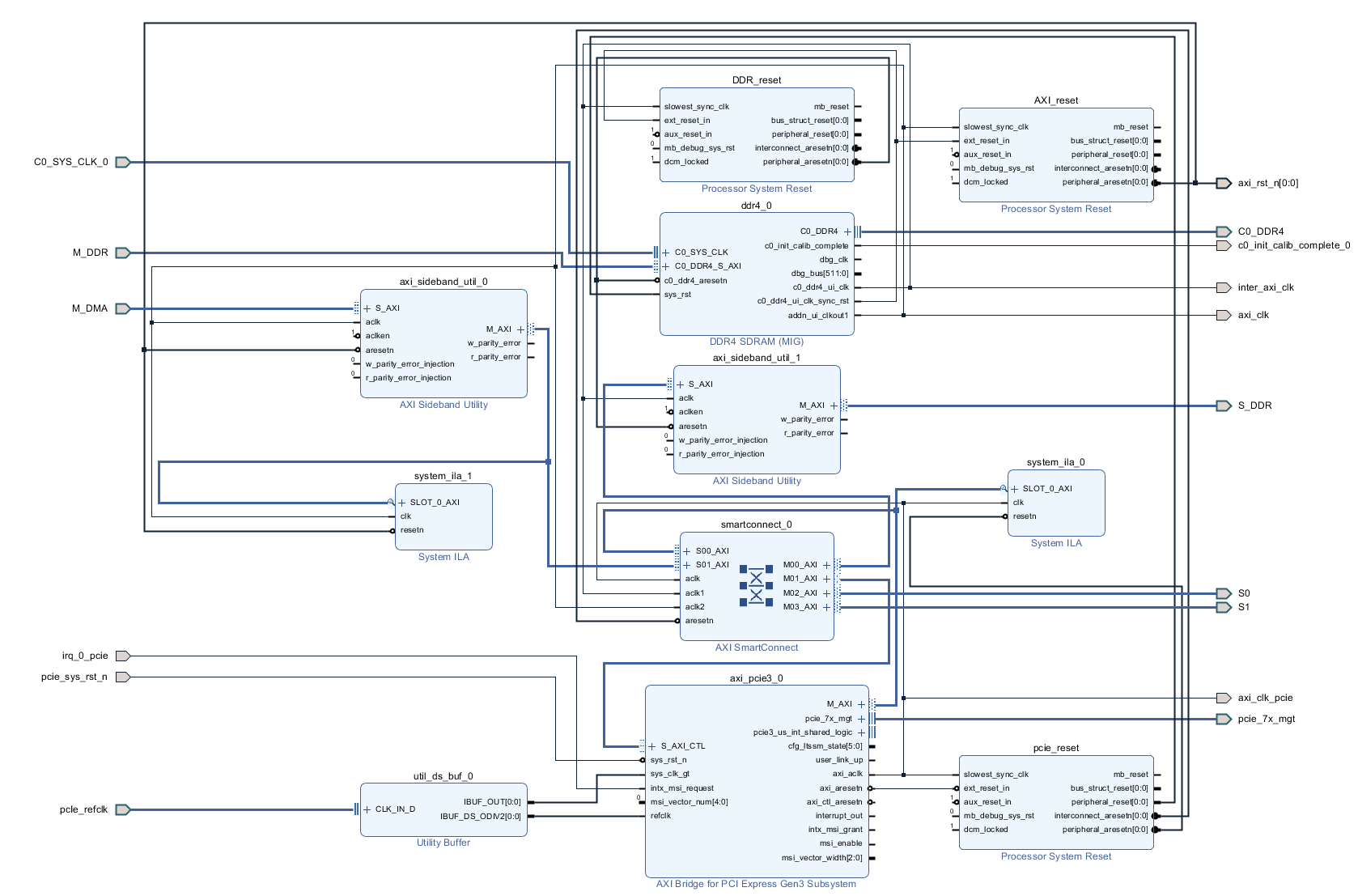
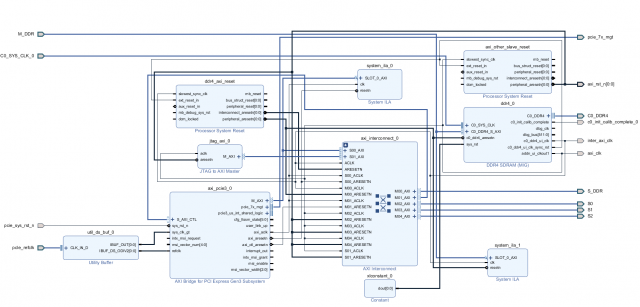
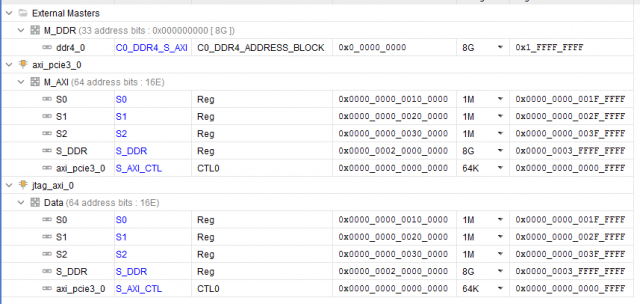
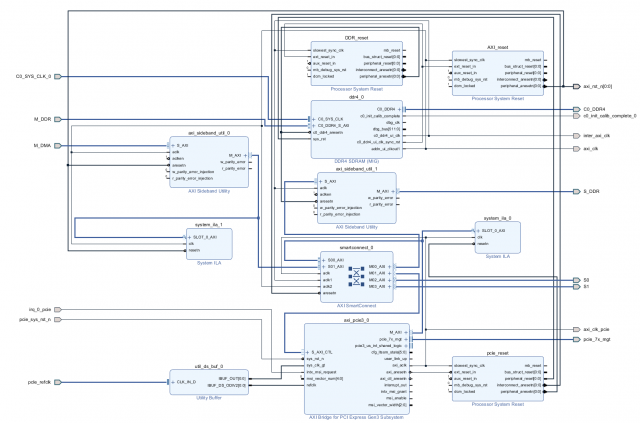
Добрый день. Долго работал с Intel (Altera) бед не знал в среде Quartus и вот пришлось перейти (к глубокому сожалению) на работу с Xilinx... Сразу был разочарован, многое из того, что доведено до автоматизма у Intel тут нужно делать самому, вникая в низкоуровневые тонкости. Очень большие ограничения на использования ip-ядер (плюс скудный набор изменяемых параметров) и плохие тайминги заводят меня в тупик. Так вот, какова суть проблемы. Работаю с Kintex Ultrascale. Понадобилось собрать систему из ядра PCIe -> interconnect ->DDR4. Прочитал кучу мануалов (PG194 v3.0, PG059 и тд.., Ответы с форумов, Видео пример настройки, Вивадовские примеры). В общем собрал систему похожую на систему из примеров. Рис. 1 Тут добавил ещё Jtag консоль для удобства отладки (в дальнейшем необходимо заменить её на свой блок ДМА), вывел интерфейсы для своих слейвов наружу. ДДР тоже вывел наружу (как S_DDR) на верхнем уровне закольцевал и вернул обратно (как M_DDR, опять же дикость связанная с XILINX пришлось решать одну из его проблем таким образом). Повесил ещё пару ИЛА для отладки и отображения шины АXI. Назначил адресные пространства. Рис. 2 Вроде всё задышало. Но с большими слеками на интерконнекте... То PCIe сама развестись не может, то на ядре ДДР какие то проблемы по таймингам. В общем всё плохо, но как то работает. По PCIe есть доступ и к DDR и к регистрам в слейвах, вроде всё корректно. Начинаю работать через Jtag консоль (в дальнейшем её нужно заменить своим блоком ДМА) и всё, ДДР не читается не пишется, комп умирает, интерконнект виснет. Проблема только при обращении к ДДР, при работе с моими слейвами регистровыми проблем нет, данные корректно пишутся и читаются. Залез по ИЛА и увидел что от ДДР не доходит сигнал BVALID и BID через интерконнект. Собственно из ДДР он вышел, но через интерконнект до второго мастера он не приходит, а для первого без проблем, всегда всё хорошо. Окей, меняю местами Jtag и PCIe та же шляпа. Jtag работает корректно, до PCIe не доходит BVALID и BID. Получается что второму мастеру по счёту просто не даётся доступ к ДДР. Листал форумы, читал советы, нашёл. Говорят что на Ultrascale и Ultrascale+ стандартный интерконнект не работает корректно, нужно ставить некий "SMARTCONNECT"... Ну окей.. читаю документацию, разбираюсь, вставляю смартконнект.. А у него оказывается выкидывает все ID(r/w/b) на шине AXI. Чтобы ID не выкидывались, ставьте "axi sideband" (говорит XILINX) до и после интерконнекта на каждой шине.. окей, поставил. Спустя все эти манипуляции я получил рабочую схему, которая может работать с двумя мастерами и без проблем читать и писать в ДДР. Рис. 3 Но эта штука разводится очень плохо. Сложность в том, что у AXI PCIe максимальная частота 250МГц, у ДДР в моём режиме (1200МГц частота памяти) AXI DDR 300МГц. Слейвы свои на такой частоте я не потяну, иначе вообще всё по таймингам умрёт... пришлось ставить в 2 раза меньше. Поставил 150МГц на слейвах. В итоге интерконнект городит очень сложную структуру из ядер клоковых конвертеров, конвертеров данных, протоколов и тд.. А потом при имплементации на эти же ядра и ругается Вивадо. Долго бьюсь над этой проблемой, не могу нормально побороть слеки. Пришлось понизить частоту ДДР до 1000МГц, соответственно AXI DDR стала 250Мгц, а частота моих слейвов 125 МГц. Слеки явно улучшились, работать можно, но проблема совсем не ушла. Как мне правильно настроить систему, чтобы не было конфликтов между ядер XILINX и всё нормально разводилось при требуемых параметрах?









.jpg.fa77b49fea2edf6b4c0e4d867a1cdf76.jpg)