jcxz
-
Постов
13 478 -
Зарегистрирован
-
Посещение
-
Победитель дней
34
Весь контент jcxz
-
Коммутация аккумуляторных банок
jcxz ответил fleshget тема в В помощь начинающему
Если "дёшево и сердито" и надёжно при этом (с защитой от бабаха), то: Поставьте возле батареи большой разъём. "Маму". 8 контактов. Подключите к его контактам 1...6 ваши 6 концов батарей. И сделайте два замыкателя "папы". У одного замыкателя соедините: 2-4; 3-5; 6-7; 1-8. У другого замыкателя соедините: 1-4-5-8; 2-3-6-7. Дальше просто воткнули один замыкатель или воткнули другой. Два одновременно воткнуть невозможно. Разъёмы можно взять любые на большой ток. Нагрузка подключается к 7:8. Без всяких дидов Шоттки, хитрых реле и пр. тряхомудрии. Кондово и надёжно. -
Вопрос по Error Correction Code(SEC-DED)
jcxz ответил TOG тема в Программирование
BusFault в Cortex-M - это не прерывание, а исключение. Соответственно запрет прерываний влиять на него никак не может. И при запрете какого-либо fault-а (если его возможно запретить), согласно идеологии Cortex-M, должна выполниться эскалация до HardFault. Так что - fault-а не избежать, если уж подсистема памяти решила сгенерить ошибку. Да и причём тут прерывания или fault-ы? ТС ведь нужны не прерывания, а возможность прочитать память. -
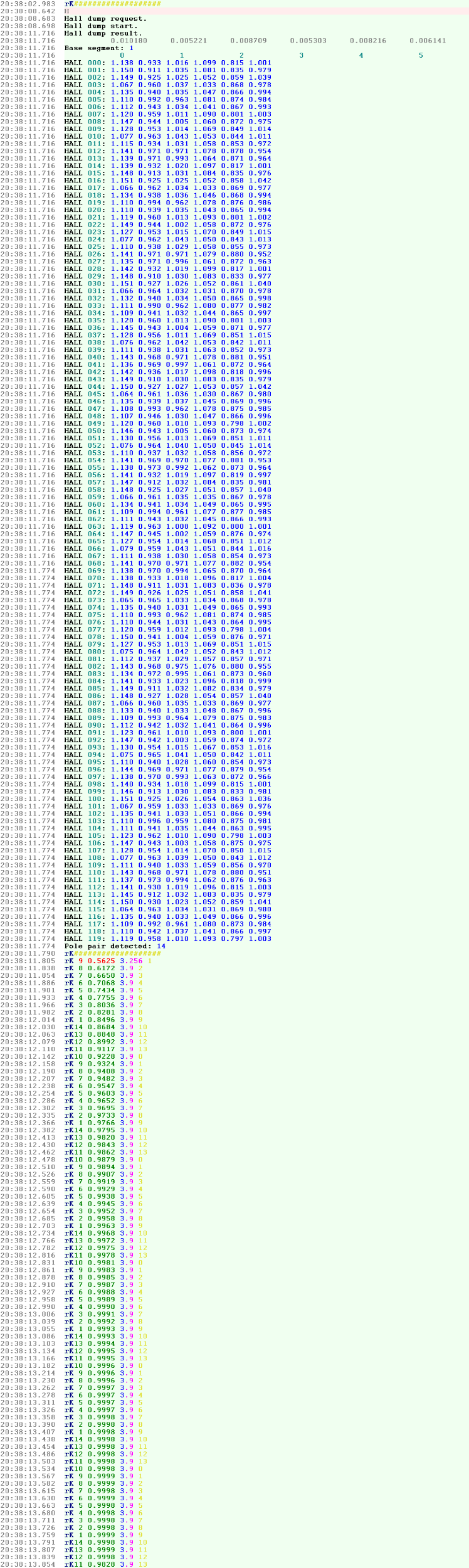
Сколько пробовал я моторов - везде неравномерность была такая, что алгоритм работал 100%-но чётко. Ни одного сбоя. Вот например делаю калибровку - сейчас кручу мотор равномерно, без ОС (просто синусом), без нагрузки на роторе с минимальным током при котором он ещё крутится (чтобы равномерно, без шажков): На участке "HALL 000 ... HALL 119" выполняется до 120 калибровочных электрических оборотов (из расчёта максимального возможного числа пар полюсов <=60) и измеряются неравномерности сигналов д.Холла. Каждый эл.оборот - 6 значений. Где каждое значение - это величина отклонения момента изменения фазы д.Холла в ту или иную сторону. Или в большую (>1.0) или в меньшую (<1.0). В конце дампа, по полученному дампу отклонений, алгоритм вычисляет число пар полюсов мотора (14 в данном случае). А затем запускается алгоритм поиска текущего положения ротора. И в сообщении "rK ..." печатается текущее найденное положение (номер эл.оборота внутри мех.оборота) и рассчитанная величина вероятности правильного вычисления. Как видно - вероятность растёт с числом оборотов (при равномерном вращении) и когда превышает некоторый порог - положение считается найденным. Эта табличка запоминается в энергонезависимой памяти и потом, при каждом старте, алгоритм запускается и ищет положение. Да по этому дампу даже на глаз видно - сколько пар полюсов у мотора. Неравномерность достаточная и повторяемая. И какие я бы моторы не смотрел - везде неравномерность была чётко видна. И повторялась от мех.оборота к мех.обороту. Это да - чтобы узнать, надо провернуть хоть немного. Но например если применение - улучшение качества управления, за счёт увеличения точности определения угла - этого вполне достаточно. Как видно по дампу - разброс значений д.Холла от самого минимального до максимального - составляет более 35%! Из-за этого точность векторного управления сильно страдает. А применив корректировку по такой таблице, можно существенно повысить КПД привода.