jcxz
-
Постов
13 731 -
Зарегистрирован
-
Посещение
-
Победитель дней
38
Весь контент jcxz
-
Плавный переход C -> C++ под МК
jcxz ответил Arlleex тема в Программирование
В том примере инита SPI для работы с flash, что я приводил ранее, как раз она используется: Эта: AtomicOrI(&DLR.LNEN, 1 << nDMALINE_df_TX); Здесь как раз производится операция '|=' между регистром DLR.LNEN и константой (1 << nDMALINE_df_TX), но не с помощью обычных команд RMW, а с помощью команд эксклюзивного доступа ARM. Т.е. - атомарно. Регистр DLR.LNEN - содержит линии DMA-запросов к разным каналам DMA. Используемым разными драйверами периферии в разных задачах/ISR. Поэтому доступ к нему нужен атомарный. Почитать можете в мануалах на ядро Cortex-M3/M4. Описание команд LDREX/STREX/CLREX. PS: AtomicOr...() у меня - это набор макросов, для атомарного '|='. На встроенном ассемблере. PPS: Вот как раз в данном конкретном случае - использование операции эксклюзивной модификации оптимальнее, чем критическая секция. О чём я и говорил. Хотя можно было конечно и критическую секцию использовать. -
STM32F405 на климатике
jcxz ответил Vladimir_T тема в STM
Не знаю конкретно насчёт STM32F405, но в других МК обычно для CAN настраиваются различные заданные моменты внутри периода одного бита CAN. Которые программист может варьировать. Например поля SJW,TSEG1,TSEG2 в XMC4700: Почти точно такие же поля есть и у LPC17xx: Качать и читать мануал STM32F405 мне лень, но думаю - что-то аналогичное должно быть и в нём. Если есть, то возможно проблема в том, что какая-то из таких настроек находится на грани работоспособности. А в температуре уходит за эту грань. Можно попробовать покрутить её чуть-чуть в обе стороны и протестить в температуре.

-
Плавный переход C -> C++ под МК
jcxz ответил Arlleex тема в Программирование
Лекция от гуру диванного программирования. Вот тут то Штирлиц и понял, что провалился!.... По постам всё видно. Видно, человек никогда на практике разработкой не занимался. Потому он и всякие советы интернетных "гуру" воспринимает догматически. Так как не может оценить их на своём опыте. А все практические вопросы заметьте - игнорирует. Или несёт какую-то чушь, вообще никак не относящуюся к делу. Ну-ну.... каждый мнит себя Наполеоном... В очередной раз (уже в 5-й?) от вас слышу про "гумно". Хотя вроде я вас не оскорблял - это вы начали и продолжаете про некое "гумно". Причём совершенно безосновательно - даже не видев моего кода(!), уже оцениваете его. Это оценивает вас как человека (как раз на аналогичную оценку). Как "специалист" вы уже себя давно "показали" во всей "красе". PS: Не буду опускаться на ваш уровень и более вступать с вами в полемику, просто буду ставить соответствующие отметки вашим словоизвержениям. Сразу пишу что оценка вам - за прямую ложь (про мой код), провокации и безосновательные оскорбления. PPS: Надеюсь в этот раз не побежите снова регить новый аккаунт и с него мстить? И требую конкретного примера (с цитатой) - где именно у меня вы увидели: "встраивать "предохранители" в виде критических секций на уровне общения с регистрами"? Цитату в студию! Иначе буду считать вас лжецом! -
Плавный переход C -> C++ под МК
jcxz ответил Arlleex тема в Программирование
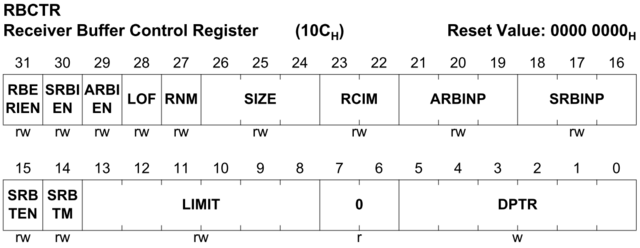
Вы всё время сравниваете с простой периферией STM32. В которой всего 5 регистров в UART и несколько бит. И где легко запомнить функции бит и ассоциировать их с названиями. А попробуйте как-нить поработать на сложном МК. Типа XMC. Где в том же UART битов - раз в десять больше. И, так как их функционал очень богатый, то и функции очень заковыристые. А потом расскажите - что вам скажут названия: 1 << SELCTR | 2 << CTQSEL1 | 1 << DX2TIEN через неделю хотя-бы? Сможете? Если битов этих не десяток, а штук 100? Я же уже писал: "уже пробовал давать символьные имена битам" - потом всё пришлось переделывать. Так как с номерами - гораздо быстрее и понятнее разобраться. Вот для справки типичный начальный инит SPI+DMA для внешней флешки на XMC4700: void InitDflash() { static TPinSel const tPinmux[] = { PINSEL_I(PIN_DF_MISO, PINSEL_USIC(nUSIC_df, DATA), STRONG_SOFT, PU), PINSEL_O(PIN_DF_MOSI, PINSEL_USIC(nUSIC_df, DOUT0), PINSEL_USIC(nUSIC_df, DATA), STRONG_SOFT), PINSEL_O(PIN_DF_SCLK, PINSEL_USIC(nUSIC_df, SCLKOUT), NONE, STRONG_SHARP, SET1), PINSEL_O(PIN_DF_CS0, PINSEL_USIC_SELO(nUSIC_df, PIN_DF_CS0), NONE, STRONG_SOFT, SET1), PINSEL_O(PIN_DF_CS1, PINSEL_USIC_SELO(nUSIC_df, PIN_DF_CS1), NONE, STRONG_SOFT, SET1) }; int i = DFLASH_CHIP_N - 1; do { chipStat[i] = CHIP_ERASE; chipWait[i] = 0; } while (--i >= 0); i = ncell(ops) - 1; do { ops[i].cmd = Op::OP_NOP; OsSemCreate1(&ops[i].sem); } while (--i >= 0); PeripheralOn(concat(SCU_PERIPH_USIC, USIC_UNIT(nUSIC_df))); spiC->KSCFG = B0 | B1 | B7 | B11; { int dummy = spiC->KSCFG; } if (~spiC->CCFG & (B0 | B6 | B7)) trap(TRAP_DFLASH | ERR_UNEMPLEMENTED << 16); spiC->CCR = 0; spiC->DXCR[0] = USIC_DXn(PIN_DF_MISO, nUSIC_df, 0) | B4; spiC->DXCR[3] = B4; spiC->FDR = B10 - 1 | 1 << 14; //Normal divider mode selected, FD_CLK = PBCLK spiC->BRG = T_LD_TD - 1 << 10 | DFLASH_PBCLK_DIV - 1 << 16 | 1 << 30; spiC->SCTR = B0 | B1 | 1 << 8 | 63 << 16 | 7 << 24; spiC->TCSR = B0 | B8 | 1 << 10; spiC->PCR = B0 | B1 | B2 | B3 | 2 << 4 | F2F_SPLIT - 1 << 8; spiC->RBCTR = spiC->TBCTR = 0; spiC->TRBSCR = B0 | B1 | B2 | B8 | B9 | B10 | B14 | B15; spiC->INPR = SRUSIC_SR(nUSIC_SR_df_ERR) * (B0 | B4 | B8 | B12 | B16); spiC->TBCTR = USIC_CH(nUSIC_df) * USIC_FIFO_SIZE * 2 | 1 << 8 | SRUSIC_SR(nUSIC_SR_df_TX) << 16 | SRUSIC_SR(nUSIC_SR_df_ERR) << 19 | concat(USIC_FIFO_SIZE_, USIC_FIFO_SIZE) << 24 | B30 | B31; spiC->RBCTR = USIC_CH(nUSIC_df) * USIC_FIFO_SIZE * 2 + USIC_FIFO_SIZE | SRUSIC_SR(nUSIC_SR_df_RX) << 16 | SRUSIC_SR(nUSIC_SR_df_ERR) << 19 | concat(USIC_FIFO_SIZE_, USIC_FIFO_SIZE) << 24 | B28 | B30 | B31; spiC->PSCR = -1; spiC->CCR = 1 | B11; DMAon(1 << nDMALINE_df_TX | 1 << nDMALINE_df_RX); rdmaC->SAR = (u32)&spiC->OUTR; rdmaC->CFG[0] = DMAPRI_SPI_RX << 5 | B10; rdmaC->CFG[1] = B1 | 1 << 2 | (nDMALINE_df_RX & 7) << 7; tdmaC->CFG[0] = DMAPRI_SPI_TX << 5 | B11; tdmaC->CFG[1] = B0 | B1 | 1 << 2 | (nDMALINE_df_TX & 7) << 11; AtomicOrI(&DLR.LNEN, 1 << nDMALINE_df_TX); PinSelN(tPinmux); } Теперь заменяем все численные позиции битов на символьные. Этот исходник распухает раз так в ~5. И заполняется всякими: Сможете через неделю вспомнить назначение всех этих RBERIEN, SRBIEN, ARBIEN, ... ? Всё равно придётся лезть в мануал и смотреть. А там смотреть удобнее по номерам битов. И строки хоть в ширину экрана влазят - исходник компактнее, значит в нём ориентироваться проще. В случае простых контроллеров с простой периферией - да, наверное. Но не в случае сложной периферии. Просто попробуйте сами на практике. Потом будете говорить. Мне и не нужно отражать. Пока я пишу драйвер - я их помню. А потом всё равно нужно лезть в мануал. А ориентироваться в более коротком коде - намного проще.