Krys
-
Постов
2 052 -
Зарегистрирован
-
Посещение
Весь контент Krys
-
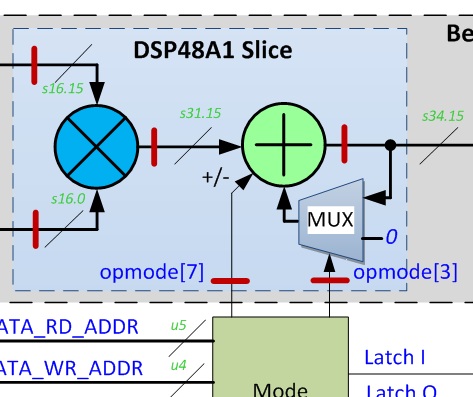
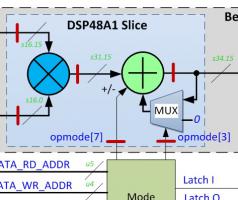
Хочу похвастаться своими успехами. Вот такую схему: реализовал вот таким кодом: (* use_dsp48 = "yes" *) reg addsub_pp, muxzero_pp; (* use_dsp48 = "yes" *) reg [DIN_BW-1 : 0] din_pp, cin_pp, din_pp2, cin_pp2; (* use_dsp48 = "yes" *) reg [DIN_BW*2 - 1 : 0] mult; (* use_dsp48 = "yes" *) reg [ACC_BW - 1 : 0] acc; (* use_dsp48 = "yes" *) wire [ACC_BW - 1 : 0] dsp48_z; // z input of post-adder // dsp48 slice logic always @(posedge clk) begin addsub_pp <= addsub; muxzero_pp <= muxzero; din_pp <= din; cin_pp <= cin; din_pp2 <= din_pp; cin_pp2 <= cin_pp; mult <= din_pp2 * cin_pp2; if(addsub_pp == 0) begin acc <= dsp48_z + mult; end else begin acc <= dsp48_z - mult; end end assign dsp48_z = muxzero_pp ? acc : 0; Т.е. это простой перемножитель комплексных чисел с накоплением суммы нескольких произведений (взятие линейной комбинации входных сигналов с применением некоторых весовых коэффициентов), реализованный в последовательной форме, когда одна операция делается за несколько тактов. Здесь необходимо переключать сложение-вычитание, а также в некоторые моменты времени начинать накопление с начала, для чего подавать 0 вместо обратной связи. Радуюсь, что удалось обойтись вот такой малой кровью, а то поначалу светила перспектива описывать DSP48 как макроблок (неприятная рутина). ЗЫ: это всё скушал XST под Spartan-6.
-
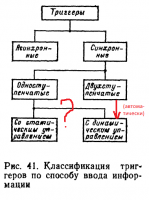
Правильно - что учили по книжке. Неправильно - что книжка содержит неправильную картинку. Итого: учили неправильно ))) Правильная картинка должна быть такая: Автор книжки в виду её (и своей) архаичности поперемешал в одну кучу аналоговые и цифровые способы получения динамического входа. В итоге связь, указанная на моей картинке вопросом - она справедлива лишь для аналогового способа выделения фронта. Итого - это всё неактуально для современных ПЛИС. С другой стороны, автор книжки забыл провести связь, указанную на моей картинке стрелкой. Эта связь образуется автоматически, т.е. любой двухступенчатый триггер по умолчанию динамический (нет, ну можно, если очень надо, умудриться сделать нединамический двухступенчатый триггер, но это неконструктивно, как велосипед с квадратными колёсами).
-
ActiveHDL+ISE (IP core)
Krys ответил hendehoh тема в Среды разработки - обсуждаем САПРы
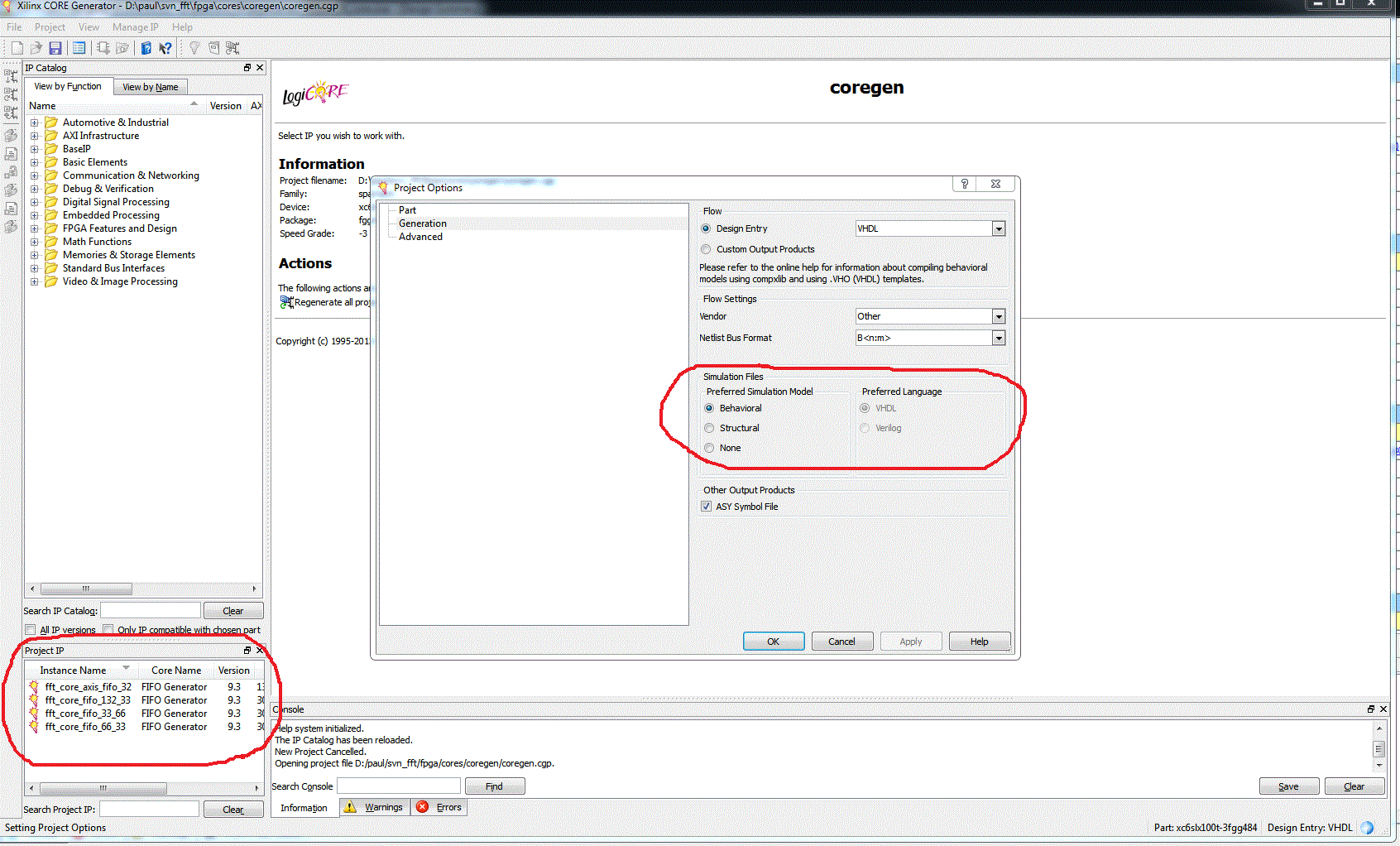
Вот смотрите: в ISE заходите в меню tools - core generator. В нём заходите в меню file - open project, указываете путь к файлу *.cgp (обычно coregen.cgp) в общей папке ваших корок. Когда откроете - увидите внизу в окошке весь список сгенерённых Вами корок. Далее заходите в меню Project - Project Options и там видите следующее: Делаете нужные настройки симуляционных файлов. Затем заходите в Project - Regenerate all project IP (можно и по одной перегенерить). Но вполне возможно эти настройки уже и так правильно стояли, поэтому симуляционные файлы и так были сгенерены. И искать их нужно в папке с коркой. Открывайте в этой папке все подряд файлы с расширениями *.vhd и смотрите - то, не то.