l1l1l1
-
Постов
2 167 -
Зарегистрирован
Весь контент l1l1l1
-
Вопросы по Microwave Office
l1l1l1 ответил EUrry тема в RF & Microwave Design
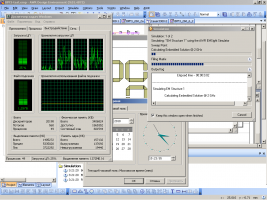
железо неплохое. да, у меня то же самое. но я нашел кое-что, оставшееся от студентов, и хочу вам показать.DIVx2.rar DIVx4.rar откройте их и просто запустите оптимизацию, не меняя установок. если всё пойдет как надо, в первом проекте распараллеливания не будет, а во втором будет. если этого не произойдет, я буду сильно удивлен. а если произойдет, подумайте почему. потом обменяемся мнениями. по поводу EMSight всё проще. взгляните на этот проект: EMSight_test.rar если погоняете в нем анализ минут 15, увидите, что распараллеливается только Factoring Matrix, а всё остальное, в том числе первая длительная операция, Filling Matrix, выполняется в один поток. в этом проекте на моём железе Filling Matrix длится 2.5 минуты, а Factoring Matrix всего 20 секунд. EMSight_log.txt зависимость нелинейная, если взять простую модель, одночастотный анализ которой длится 30 секунд, операции Factoring Matrix невозможно будет заметить.