Krys
-
Постов
2 052 -
Зарегистрирован
-
Посещение
Информация о Krys
-
Звание
Гуру
")
Посетители профиля
5 841 просмотр профиля



-
Китайские ПЛИС
Krys ответил МАСТЕР LO тема в Работаем с ПЛИС, области применения, выбор
https://inf.news/en/economy/7b07c778506a36eeb6bf1b5381f930b3.html -
На основе вашей подсказки доработал свою функцию (изменения под комментариями со словами aspect ratio): И вызывающий её код теперь выглядит вот так: Теперь выглядит неплохо: Так что в принципе вопрос можно считать решённым.
-
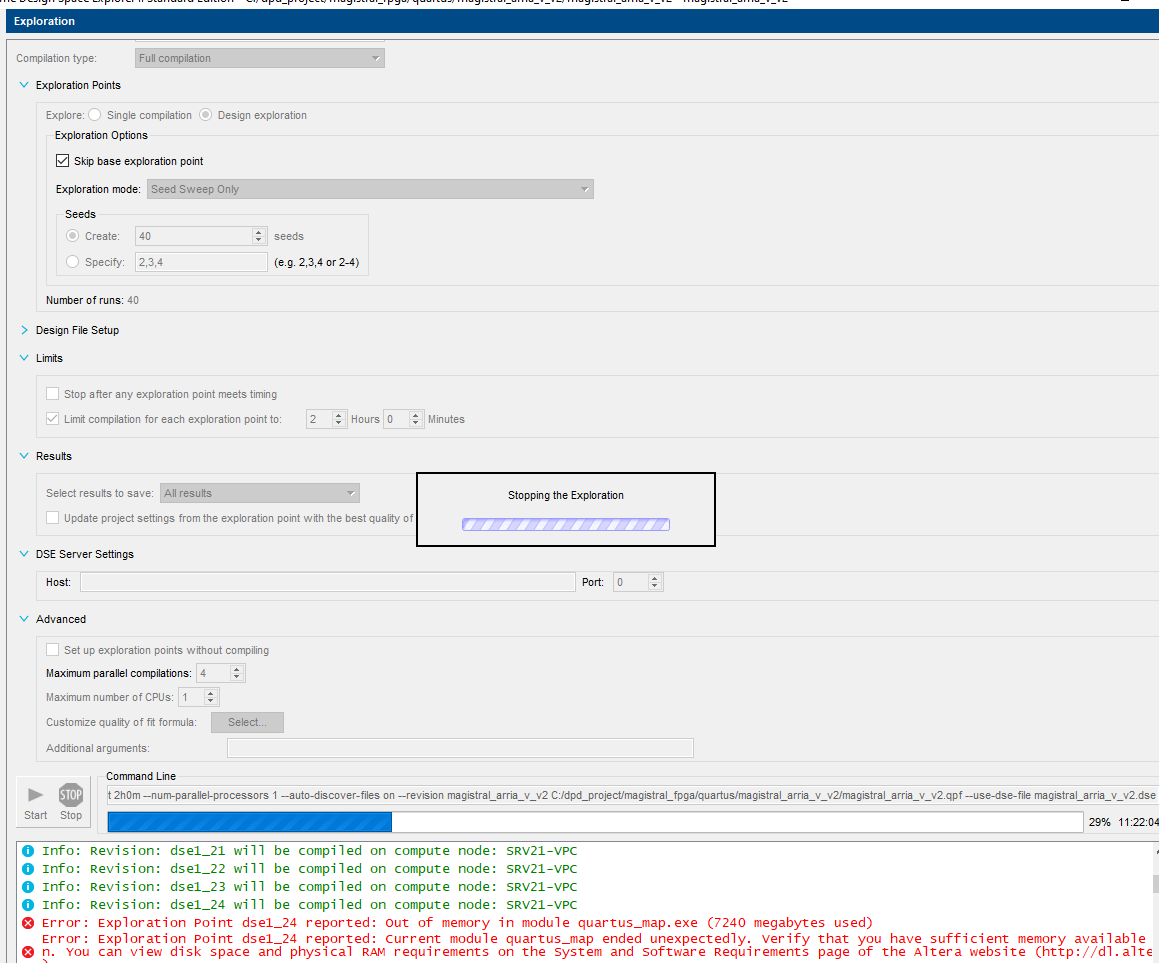
Design Space Explorer
Krys ответил Serega Doc тема в Среды разработки - обсуждаем САПРы
Подниму бородатую тему. Полез в сабж решать проблему со слаками. Да, в сабже она решилась. Но как я могу перетащить в свой основной проект (для разводки чисто в квартусе, без использования каждый раз сабжа) те настройки, что были сделаны для exploration point с лучшим результатом? Я попробовал тупо скопировать файл проекта *.qsf, дам видно, что только seed отличается. Развёл этим файлом проекта - никуда не делись слаки. Значит данная exploration point имеет и другие настройки, кроме seed, которые отличаются от моего основного проекта, но где их выколупать - я не знаю. Также есть жалоба на кривоватость работы...