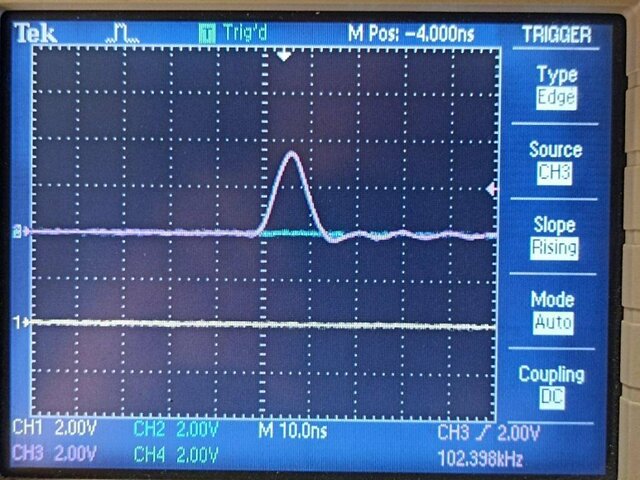
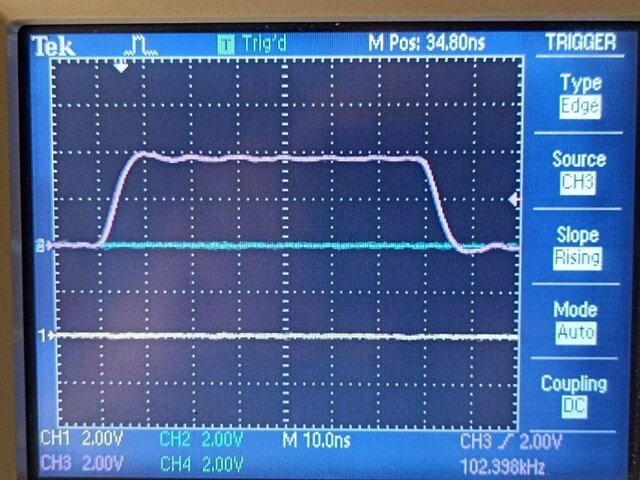
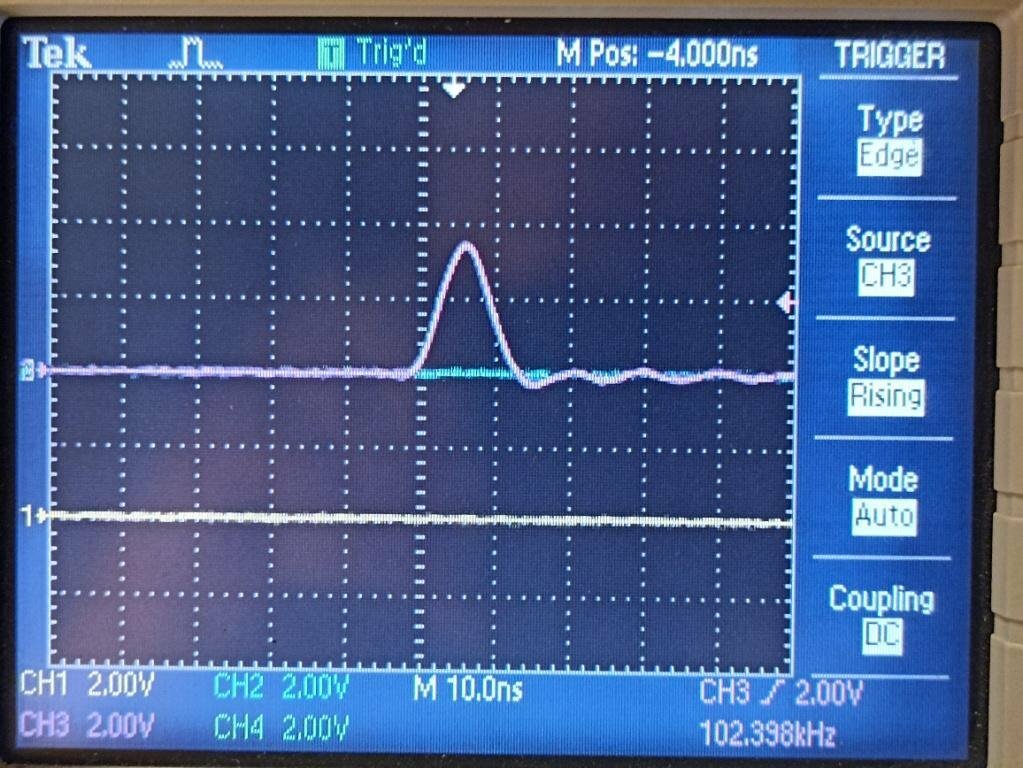
Нашел ошибку у себя: задал частоту процессора вдвое меньше (144 против 288).
Но результаты исследования были очень полезны! Я поигрался с памятью, с оптимизацией и вот что получилось.
Попробовал поиграться с взятием из памяти - получилось улучшить. Пример (R0 = 0x20001A7C, R2 = 0x20001A80, R4 = 0x20001A84):
LDR R1, [R0]
ADD R1, #0
STR R1, [R0]
LDR R3, [R2]
ADD R3, #0
STR R3, [R2]
LDR R5, [R4]
ADD R5, #0
STR R5, [R4]
выполняется 49 нс (14 тактов), а последовательность
LDR R1, [R0]
LDR R3, [R2]
LDR R5, [R4]
ADD R1, #0
STR R1, [R0]
ADD R3, #0
STR R3, [R2]
ADD R5, #0
STR R5, [R4]
выполняется 42 нс (12 тактов).
(Да, я мерил своим любимым GPIO, но все сходится). В принципе, разница невелика, но есть.
Да, AT действительно работает быстрее STM. Поэтому, если речь идет об оптимизации, то лучше, если будет длительная вычислительная цепочка.
Т.е. взял значения - и долго-долго обрабатываешь, потом кладешь.
Но, если говорить о целочисленных вычислениях, то взять значения особо-то и некуда - регистров всего 12. Иное дело обстоит с регистрами FPU - их 32.
Но AT работает быстрее! Так, я запустил весь алгоритм (без оптимизации!), и получилось, что эффективность возросла где-то на 30-40 % (собственно, пропорционально тактовой частоте - 288/216 МГц).
Выводы.
1. AT на Cortex-M4 работает быстрее во всех отношениях, чем STM на Cortex-M7.
2. Оптимизация при целочисленных вычислениях не имеет смысла - мало регистров, да и процесс, как правило, один.
3. Оптимизация при "плавучных" вычислениях даст превосходный результат, т.к. есть 32 FPU регистра.
4. Если программа, требующая быстрой работы (0WS), до 512 кБ, то не надо кэшировать ее, создавать системы управления памятью - она сама грузится в SRAM и работает быстро.
5. Цена где-то в 2-3 раза ниже у китайца.
Резюме: выбираю китайца AT32F437, всё закладываю под него. Но делаю так, чтобы можно было запаять STM32F745.
Всем спасибо!



")