jojo
-
Постов
572 -
Зарегистрирован
-
Посещение
Весь контент jojo
-
xst: сумматоры и LUT6
jojo ответил Victor тема в Среды разработки - обсуждаем САПРы
Вроде получается, в LUT6 упакованы LUT3 и LUT4. Virtex-6 с настройками проекта по умолчанию.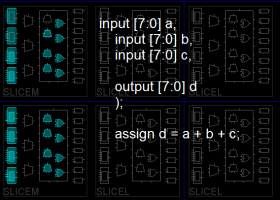
-
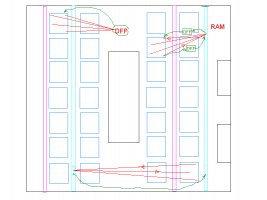
Нужно сопоставлять отчёт анализатора задержек (Timequest др.) и вид проблемного пути на кристалле (FloorPlan Editor и т.п.). Проблемный триггер или блок памяти может быть расположен в "левом" месте на кристалле, вдали от разумного, желаемого положения. Поскольку таких элементов может быть много, их положение можно оптом законстрейнить. Ресурсы ПЛИС расположены немонотонно, например, узкими колонками, простым констрейном размещения дело может не обойтись. В этом случае добавляем в конвейер пустые регистры, которые по алгоритму вроде не нужны, но задержку сокращают. Покажите, если можете, аналогичную картинку своего проекта с подсвечиванием сбойных путей.
-
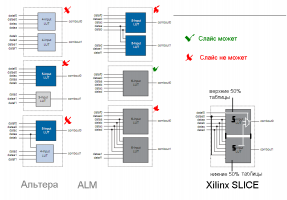
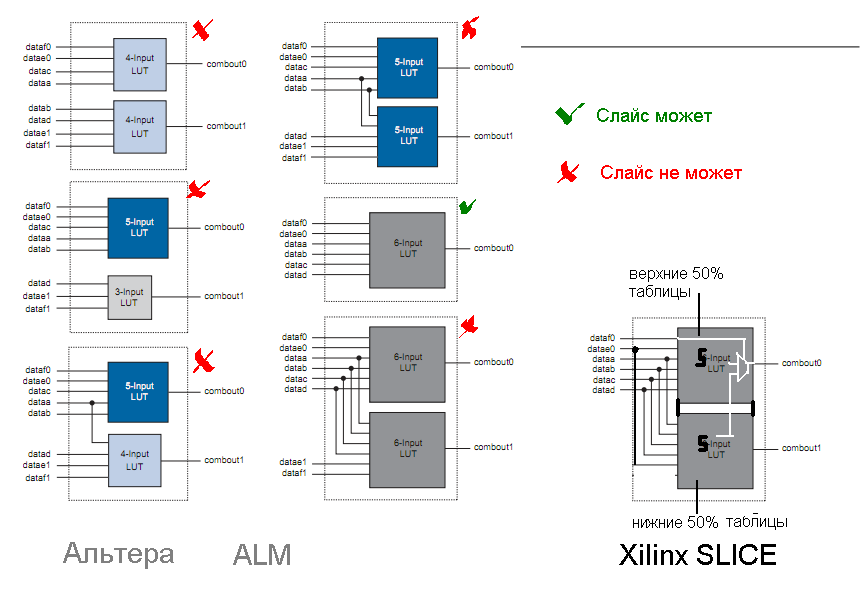
А вроде ALM-то многофунциональнее будет, чем современный SLICE? Stratix III со скидками ещё как-то мог конкурировать с Virtex-5. У Stratix IV была какая-то дикая розничная цена, так что оптовую даже узнавать не хотелось.