pavlovconst
-
Постов
140 -
Зарегистрирован
-
Посещение
-
Победитель дней
2
Весь контент pavlovconst
-
Есть несколько вариантов реализации вашей системы - Системный (общий для всех устройств) клок. Передача данных и прием на этом клоке. Хорошо, если этот вариант заработает на 90MHz. - Source-synchronous тактирование, клок сопровождает данные. DDR буфера на передаче и на приеме. Думаю, максимум 90MHz внутренний клок, 180Mbps или около того на лейн. Реализовать такое относительно легко. - Source-synchronous тактирование, SERDES c кратностью от 4 до 10, передаем внутренний медленный клок. Потребуется умножать внутренний клок и на передатчике, и на приемнике, нужны PLL. Видимо, вы так не сможете сделать. - То же, что и предыдущий пункт, только с данными передаем быстрый клок. Приемник делит этот клок на логике, чтобы защелкивать данные с десериализатора. По даташиту обещают до 1200Mbps, по факту - будет трудоемко получить даже 400Mbps. Много подводных камней, связанных с пророческим названием выбранной ПЛИСки.
-
В моем случае, на скоростях более 600Mbps с приемника сыпется исключительно мусор. Никакие настройки не помогают, а попробовал я много всего, можете глянуть. Плата Tang Nano 25K, линия передачи в виде перемычки разъеме (плюс согласующие резисторы). Документация у них жиденькая, как таковых рекомендаций нет. Хотя, где-то я находил рекомендацию запитывать банк с LVDS линиями именно от 2.5V. В надежде на улучшение, я заколхозил плату, но ... ничего не изменилось 🤣 @iiv Ещё, обратите внимание на количество доступных PLL - их, вроде бы, две. А приемников у вас - 7 штук. Надо заранее подумать, на каком клоке вы будете принимать данные
-
Расшифрую немного. Сейчас вы видите в отчете что-то, чего сами не задумывали в дизайне. Значит, IDE собирает какой-то другой проект, НЕ ВАШ. И собирает его неправильно. Вам нужно детально проанализировать каждую строчку репорта - посмотреть код, посмотреть схему, проверить тактирование всех участвующих сигналов. Если IDE говорит, что есть пересечение клоков - то так оно и есть. По крайней мере, в "её" проекте. Вопрос только "где?" и "как это исправить?". В одной и предыдущих ваших тем на форуме мы уже обсуждали этот момент. С помощью констрейнов можно легко заглушить все нарушения. Но вам-то, наверное, не отчеты нужны, а работающий дизайн. Поэтому, скорее всего, каждая красная строчка отчета потребует некоторых доработок по коду. Где-то нужно будет добавить синхронизаторы, а где-то - констрейны. Каждый случай потребуется разбирать отдельно, и на форуме это сделать сложно. Почитайте книжки, которые я прикрепил, это самая лучшая литература по теме.
-
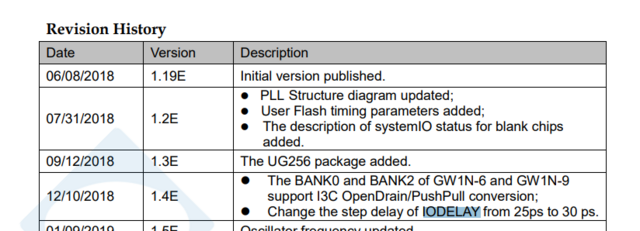
Привет! Я немного опоздал, но все же дополню 😃 В даташите на GW1N нашел такую запись Видимо, 25ps было задокументировано изначально, затем документация была поправлена, а модели - нет. Почему написали новые значения? Я предположу, потому что задержки IODELAY некалиброваннные (в отличие от Xilinx-а) и в разных PVT условиях могут отличаться. Возможно, перестраховались и вписали самый плохой случай...