Maverick_
-
Постов
3 864 -
Зарегистрирован
Весь контент Maverick_
-
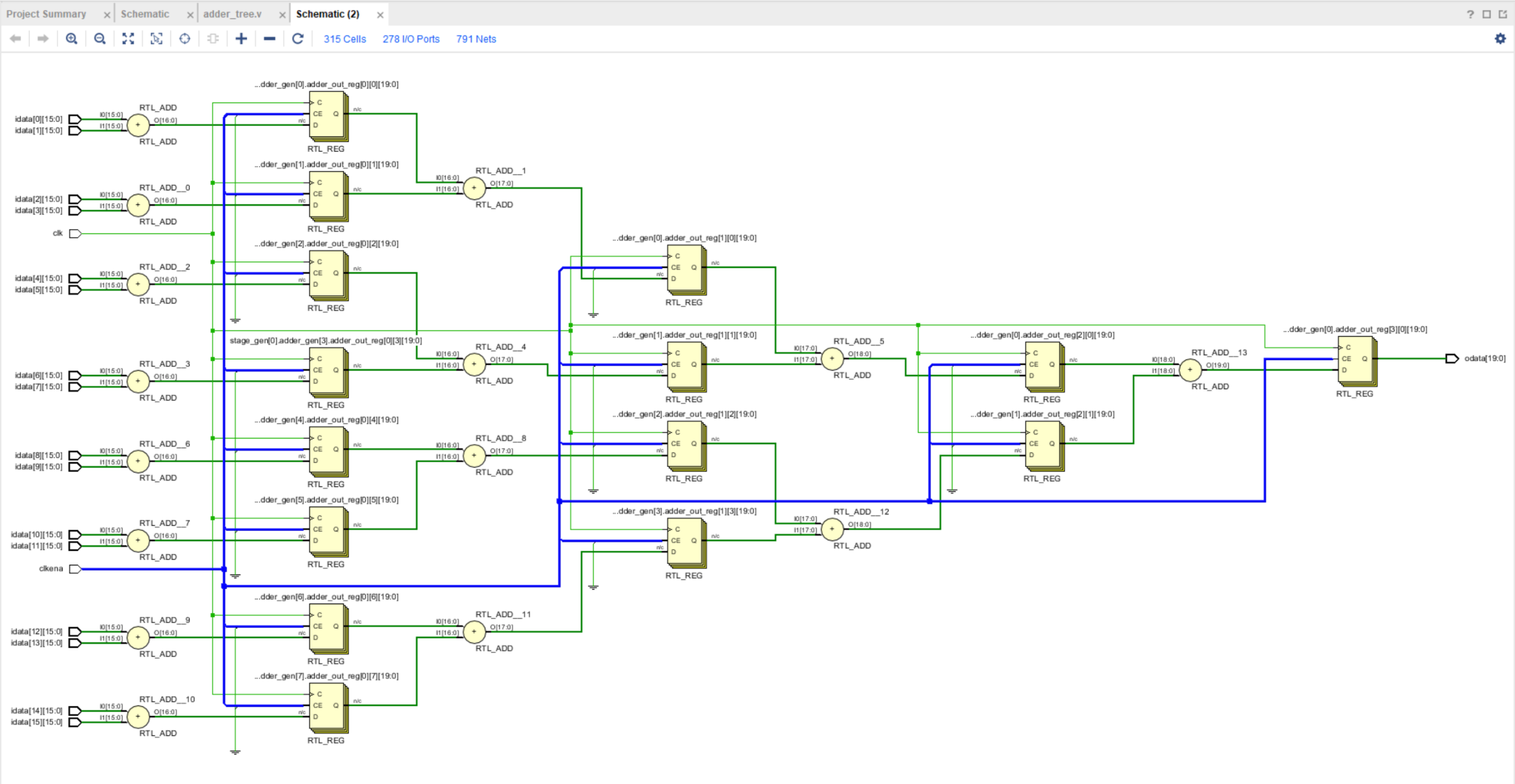
огромное спасибо! и(vivado 2019.1) для module adder_tree # ( parameter int NUM_INPUTS = 16, parameter int DATA_WIDTH = 16, parameter int OUT_DATA_WIDTH = DATA_WIDTH + $clog2(NUM_INPUTS) ) ( input logic clk, input logic clkena, input logic [DATA_WIDTH-1:0] idata [0:NUM_INPUTS-1], output logic [OUT_DATA_WIDTH-1:0] odata ); localparam int NUM_INPUTS_TRUE = 2 ** ($clog2(NUM_INPUTS)); localparam int LP_STAGES = $clog2(NUM_INPUTS); logic [DATA_WIDTH-1:0] in_true [0:NUM_INPUTS_TRUE-1]; logic [OUT_DATA_WIDTH-1:0] adder_out [0:LP_STAGES-1][0:NUM_INPUTS_TRUE/2-1]; //Make zero assignment for unused inputs (in case when NUM_INPUTS ~= power of 2 : genvar inp; generate for (inp=0; inp < NUM_INPUTS_TRUE; inp = inp + 1) begin: inp_assign if(inp < NUM_INPUTS) assign in_true[inp] = idata[inp]; else assign in_true[inp] = '0; end endgenerate genvar stage,adder_num; generate for (stage=0; stage < LP_STAGES; stage = stage + 1) begin: stage_gen localparam int STAGE_IN_W = NUM_INPUTS_TRUE >> stage; localparam int STAGE_OUT_W = STAGE_IN_W/2; localparam int DW_IN = DATA_WIDTH + stage; localparam int DW_OUT = DW_IN + 1; for (adder_num=0; adder_num < STAGE_OUT_W; adder_num = adder_num + 1) begin: adder_gen if(stage == 0) always_ff@(posedge clk) begin if (clkena) begin adder_out[stage][adder_num][DW_OUT-1:0] <= in_true[adder_num*2] + in_true[adder_num*2 + 1]; end end else begin always_ff@(posedge clk) begin if (clkena) begin adder_out[stage][adder_num][DW_OUT-1:0] <= adder_out[stage-1][adder_num*2][DW_IN-1:0] + adder_out[stage-1][adder_num*2 + 1][DW_IN-1:0]; end end end end end endgenerate assign odata = adder_out[LP_STAGES-1][0]; endmodule и в ртл просматровщике

-
Помощь с core atan
Maverick_ ответил Maverick_ тема в Языки проектирования на ПЛИС (FPGA)
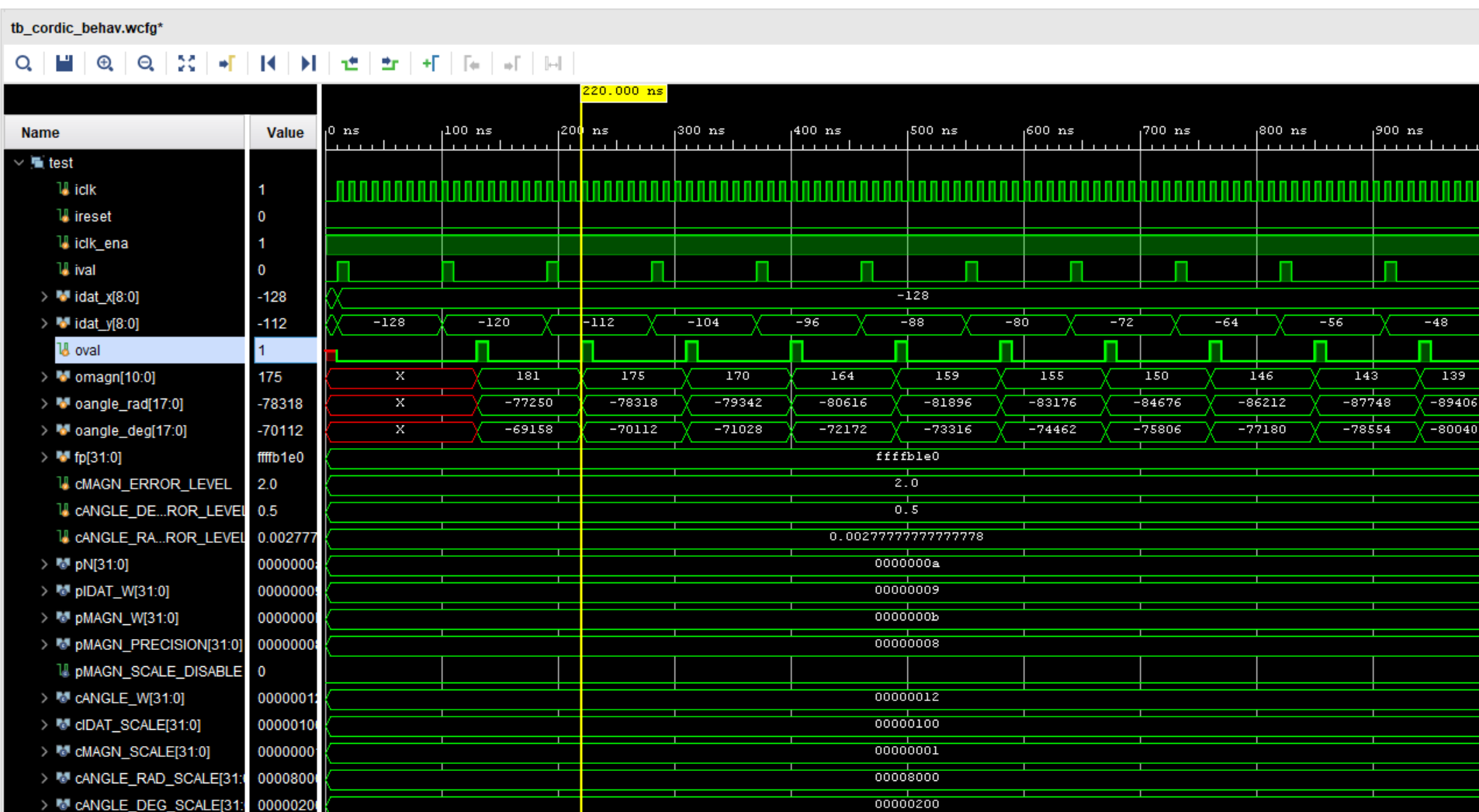
я прочитал readme.txt не сколько раз, но смотрю симуляцию вижу X, Y и результат беру числа с симуляции подставляю в матлаб (использую функцию atan2(Y,X)) - не совпадает не могу понять что я делаю не так Скриншот симуляции: например в матлабе atan2(-120,-128) ans = -2.3884
-
des00 имел ввиду скорее всего что будет Ваша корка SDRAM соедениться с моделью микросхемы. Начнете симуляцию .... Но для начала Вам надо скомпилировать библиотеку корок для симулятора - делается в среде разработки... Потом пути прописать.... например в вивадо