


sonycman
Свой-
Постов
1 951 -
Зарегистрирован
-
Посещение
Весь контент sonycman
-
Доброго времени суток! Использую Cyclone V SoC. Планирую в своей корке использовать простенький DMA для записи обработанных данных в память SDRAM процессора HPS. Интерфейс у корки простой - Avalon MM, далее через мост FPGA->HPS. Затем буду сигналить линию IRQ в качестве флага, что данные записаны в память. Но вот как быть уверенным, что на момент поднятия IRQ данные на самом деле будут лежать в памяти? Насколько я знаю, Qsys Interconnect генерирует промежуточное FIFO, затем Сlock Crossing Bridge и прочую необходимую логику. То есть момент, когда Avalon MM со стороны FPGA->HPS моста принял данные, совсем не говорит о том, что они уже записаны в память. Насколько я понимаю. Как узнать, когда на самом деле данные будут записаны, чтобы процессор мог без проблем их прочитать? Может быть, стоит задействовать сигналы response интерфейса Avalon MM? Это позволит понять, что слэйв на стороне моста принял данные, но вот записал ли он их?...
-
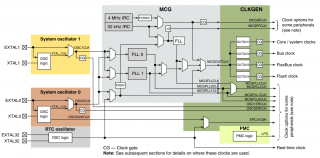
Посмотрите на диаграмму тактирования из мануала: Как видно, для клока ядра существует делитель OUTDIV1, работающий в диапазоне от 1 до 16. К примеру, с PLL вы получили 360 МГц, делите эту частоту на 3 - получаете 120 МГц системный клок.
-
Так ведь майнят их на GPU, а не на CPU. А разве хоть одна FPGA сравнится с GPU?
-
Чем заменить Intel Edison?
sonycman ответил iiv тема в В помощь начинающему
Вот что на одном ядре Cortex-A9 (800 МГц, Cyclone V SoC Baremetal) получилось: integer copy: A(i) -> B(i) icopy: 1 134217728 2.34881 57.1429MFlop/s icopy: 2 67108864 1.76161 76.1905MFlop/s icopy: 4 33554432 0.461374 290.909MFlop/s icopy: 8 16777216 0.356516 376.47MFlop/s icopy: 16 8388608 0.293602 457.142MFlop/s icopy: 32 4194304 0.293602 457.142MFlop/s icopy: 64 2097152 0.293601 457.143MFlop/s icopy: 128 1048576 0.308019 435.745MFlop/s icopy: 256 524288 0.30081 446.188MFlop/s icopy: 512 262144 0.297206 451.598MFlop/s icopy: 1024 131072 0.295404 454.353MFlop/s icopy: 2048 65536 0.294503 455.743MFlop/s icopy: 4096 32768 0.294054 456.439MFlop/s icopy: 8192 16384 0.299379 448.32MFlop/s icopy: 16384 8192 0.518028 259.094MFlop/s icopy: 32768 4096 0.433614 309.533MFlop/s icopy: 65536 2048 0.423497 316.927MFlop/s icopy: 131072 1024 1.57213 85.3734MFlop/s icopy: 262144 512 1.70374 78.7783MFlop/s icopy: 524288 256 1.671 80.3217MFlop/s icopy: 1048576 128 1.61824 82.9406MFlop/s integer axpy: A(i)*Alpha + B(i) -> B(i) iaxpy: 1 33554432 0.754976 88.8887MFlop/s iaxpy: 2 16777216 0.545259 123.077MFlop/s iaxpy: 4 8388608 0.230687 290.909MFlop/s iaxpy: 8 4194304 0.209715 320MFlop/s iaxpy: 16 2097152 0.209715 320MFlop/s iaxpy: 32 1048576 0.209715 320MFlop/s iaxpy: 64 524288 0.209715 320MFlop/s iaxpy: 128 262144 0.210043 319.501MFlop/s iaxpy: 256 131072 0.209879 319.75MFlop/s iaxpy: 512 65536 0.209797 319.875MFlop/s iaxpy: 1024 32768 0.209757 319.936MFlop/s iaxpy: 2048 16384 0.209737 319.967MFlop/s iaxpy: 4096 8192 0.335971 199.746MFlop/s iaxpy: 8192 4096 0.364168 184.28MFlop/s iaxpy: 16384 2048 0.366996 182.86MFlop/s iaxpy: 32768 1024 0.367101 182.808MFlop/s iaxpy: 65536 512 0.694582 96.6176MFlop/s iaxpy: 131072 256 0.86259 77.7993MFlop/s iaxpy: 262144 128 0.885185 75.8134MFlop/s iaxpy: 524288 64 0.896598 74.8483MFlop/s iaxpy: 1048576 32 0.899761 74.5852MFlop/s integer gemm: Alpha*A*B + Beta*C -> C igemm: 1 16777217 0.566232 59.2592MFlop/s igemm: 2 2097153 0.275251 121.905MFlop/s igemm: 4 262145 0.206768 162.281MFlop/s igemm: 8 32769 0.128414 261.307MFlop/s igemm: 16 4097 0.08595 390.49MFlop/s igemm: 32 513 0.067358 499.124MFlop/s igemm: 64 65 0.058329 584.25MFlop/s igemm: 128 9 0.071259 529.74MFlop/s igemm: 256 2 0.114164 587.829MFlop/s igemm: 512 1 0.890407 301.475MFlop/s igemm: 1024 1 8.25183 260.243MFlop/s float axpy: A(i)*Alpha + B(i) -> B(i) faxpy: 1 33554432 0.754976 88.8887MFlop/s faxpy: 2 16777216 0.524288 128MFlop/s faxpy: 4 8388608 0.241172 278.261MFlop/s faxpy: 8 4194304 0.220201 304.762MFlop/s faxpy: 16 2097152 0.220201 304.762MFlop/s faxpy: 32 1048576 0.220201 304.762MFlop/s faxpy: 64 524288 0.220201 304.762MFlop/s faxpy: 128 262144 0.220528 304.31MFlop/s faxpy: 256 131072 0.220365 304.535MFlop/s faxpy: 512 65536 0.220283 304.648MFlop/s faxpy: 1024 32768 0.220242 304.705MFlop/s faxpy: 2048 16384 0.220223 304.731MFlop/s faxpy: 4096 8192 0.342565 195.901MFlop/s faxpy: 8192 4096 0.365098 183.811MFlop/s faxpy: 16384 2048 0.367064 182.826MFlop/s faxpy: 32768 1024 0.367172 182.772MFlop/s faxpy: 65536 512 0.698279 96.1061MFlop/s faxpy: 131072 256 0.865678 77.5217MFlop/s faxpy: 262144 128 0.887534 75.6127MFlop/s faxpy: 524288 64 0.898818 74.6635MFlop/s faxpy: 1048576 32 0.901088 74.4754MFlop/s float gemm: Alpha*A*B + Beta*C -> C fgemm: 1 16777217 0.534774 62.7451MFlop/s fgemm: 2 2097153 0.251659 133.333MFlop/s fgemm: 4 262145 0.182846 183.513MFlop/s fgemm: 8 32769 0.145617 230.436MFlop/s fgemm: 16 4097 0.124048 270.562MFlop/s fgemm: 32 513 0.114452 293.747MFlop/s fgemm: 64 65 0.113251 300.913MFlop/s fgemm: 128 9 0.143249 263.518MFlop/s fgemm: 256 2 0.234565 286.099MFlop/s fgemm: 512 1 1.29243 207.698MFlop/s fgemm: 1024 1 11.4308 187.869MFlop/s double axpy: A(i)*Alpha + B(i) -> B(i) daxpy: 1 33554432 0.587203 114.286MFlop/s daxpy: 2 16777216 0.54526 123.077MFlop/s daxpy: 4 8388608 0.482345 139.13MFlop/s daxpy: 8 4194304 0.482345 139.13MFlop/s daxpy: 16 2097152 0.482345 139.13MFlop/s daxpy: 32 1048576 0.482345 139.13MFlop/s daxpy: 64 524288 0.482345 139.13MFlop/s daxpy: 128 262144 0.484311 138.566MFlop/s daxpy: 256 131072 0.483328 138.847MFlop/s daxpy: 512 65536 0.482837 138.989MFlop/s daxpy: 1024 32768 0.482591 139.06MFlop/s daxpy: 2048 16384 0.71855 93.3948MFlop/s daxpy: 4096 8192 0.748127 89.7025MFlop/s daxpy: 8192 4096 0.756389 88.7227MFlop/s daxpy: 16384 2048 0.756724 88.6834MFlop/s daxpy: 32768 1024 1.36238 49.2584MFlop/s daxpy: 65536 512 1.74453 38.4682MFlop/s daxpy: 131072 256 1.7909 37.4722MFlop/s daxpy: 262144 128 1.79451 37.3967MFlop/s daxpy: 524288 64 1.79465 37.3937MFlop/s daxpy: 1048576 32 1.79501 37.3864MFlop/s double gemm: Alpha*A*B + Beta*C -> C dgemm: 1 16777217 0.503317 66.6666MFlop/s dgemm: 2 2097153 0.263455 127.363MFlop/s dgemm: 4 262145 0.201197 166.775MFlop/s dgemm: 8 32769 0.163722 204.954MFlop/s dgemm: 16 4097 0.144506 232.258MFlop/s dgemm: 32 513 0.135318 248.452MFlop/s dgemm: 64 65 0.143856 236.895MFlop/s dgemm: 128 9 0.163413 231.002MFlop/s dgemm: 256 2 0.345664 194.145MFlop/s dgemm: 512 1 2.47972 108.252MFlop/s dgemm: 1024 1 20.7655 103.416MFlop/s BLAS библиотеку не ставил, она только под x86, насколько я понял? -
Чем заменить Intel Edison?
sonycman ответил iiv тема в В помощь начинающему
Могу прогнать какой нибудь код на одном ядре. Можете дать наводку на нужный? -
Чем заменить Intel Edison?
sonycman ответил iiv тема в В помощь начинающему
Интересно было бы узнать, почему два ядра Cortex-a9 на 800 МГц уступают двум x86 на 500МГц? -
VGA контролер
sonycman ответил andriy199616 тема в Языки проектирования на ПЛИС (FPGA)
Nack для того, чтобы слейв освободил шину и не мешал, когда мастер будет выставлять стоп или повторный старт. -
А как? Копировать надо из FIFO контроллера SD, к которому тоже доступ должен быть строго выровнен по 32 битам. С произвольным смещением данные забрать нельзя.
-
Сделал пока так, что DMA работает с выровненным промежуточным буфером в некешируемой области памяти, а я процессором копирую данные на нужный выровненный\невыровненный адрес. Можно, наверное, для промежуточного буфера использовать часть OnChip памяти, чтобы копирование через memcpy было эффективнее. Интересно, разве так трудно было сделать, чтобы DMA работало с невыровненными адресами? Всего-то использовать сигналы byte enable и, наверное, сдвиговый регистр. Может потом попробую свой модуль для этого написать...
-
PS: по последнему посту поправочка - скорость UART должна быть 115200 бод, а не 9600.
-
Да, просто поставить галочку в bsp-editor напротив опции SERIAL_SUPPORT. Потом подключаетесь к порту UART0 со стандартными настройками 9600 8n1 и все.
-
Приветствую. Я использую немного другой синтаксис для mkimage : mkimage -A arm -T standalone -C none -a 0x100000 -e 0 -n "baremetal image" -d app_binary.bin app.img Попробуйте. Использую компилятор ARM, файл линкера такой: SDRAM 0x00100000 0x40000000 { VECTORS +0 { * (VECTORS, +FIRST) } APP_CODE +0 { * (+RO, +RW, +ZI) } ; Application heap and stack ARM_LIB_STACKHEAP +0 ALIGN 16 EMPTY 0x4000; Application heap and stack { } } OCRAM 0xFFFF0000 0xFFFFF000 { TLB +0 ALIGN 16384 UNINIT 0x4000 { *(tlb_table) } } Область OCRAM используется для расположения таблицы MMU, всё остальное - в DDR SDRAM. Смещение в 64 байта не делаю, нафиг не нужно оказалось. Вообще, неплохо для начала использовать дебаггер, в нём видно будет весь процесс. А в слепую тяжеловато ковыряться. Прелоадер какую информацию по UART выдаёт? Лог загрузки (в случае MPL загрузчика) обычно такой: INIT: MPL build: May 7 2017 20:11:53 INIT: Initializing board. INIT: MPU clock = 800 MHz INIT: DDR clock = 400 MHz INIT: Initializing successful. MPL: SDRAM Size is 1048576KB. MPL: Booting from FAT. FAT: Mounting FAT. FAT: Read image [app.img] header. FAT: Read remaining image data. FAT: Image loaded to memory. FAT: Read FPGA [fpga.img] header. FAT: Read remaining FPGA data. FAT: FPGA loaded to memory. MPL: FPGA configured. MPL: Launching next stage.
-
1. Вероятно, да. 2. Память доступна только поблочно, то есть открываем блок (страницу памяти) - читаем/пишем только в пределах этого блока. Если адрес достигает верхней границы - он обнуляется на начало блока. 3.Вероятно - разрядность микросхемы памяти. Вы бы лучше работали сразу с оригиналом даташита, на английском языке. Сами видите, какая получается мешанина из разных терминов, когда одно и то же слово переводится по-разному.
-
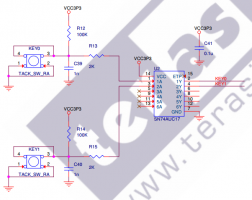
Сам так и делаю - сдвиговый регистр в ПЛИС, но тут интересует сама идея Терасик - воткнуть триггер шмидта без ФНЧ на входе - и уверять, что такой сигнал можно использовать в качестве тактового... Вроде грамотные платы у них получаются, но этот момент меня расстраивает :(
-
Извиняюсь за офтоп, но раз уж про это заговорили... Вот схема антидребезга от Терасик: Просто воткнули триггер шмидта, практически нет никакого фильтра на его входе. Насколько это эффективно в плане антидребезга? Когда механические контакты могут дребезжать в течении нескольких миллисекунд?
-
SD Card Controller DMA
sonycman опубликовал тема в Системы на ПЛИС - System on a Programmable Chip (SoPC)
Приветствую! Ковыряюсь с файловой системой на карте памяти, думаю задействовать DMA контроллера SD/MMC. Но вот требование к выравниванию памяти до 32-ух бит портит всю картину. Для файловой системы невозможно обеспечить выравнивание адреса буфера чтения/записи, соответственно DMA невозможно будет использовать в случае таких адресов. Может быть, тогда завести промежуточный выровненный буфер, с которым будет работать DMA, а потом копировать из/в него данные по месту назначения? Но тогда в чем цимес такого DMA, когда все равно приходится работать "ручками"? :cranky: -
Тоже думаю, что проблема просто в переполнении ФИФО аппаратного приёмника. Потому, что винда тупо не успевает выгребать данные. Но тогда надо проверить, флаг переполнения должен быть установлен. Может, стоит попробовать адаптер COM->USB, там аппаратная буферизация может быть лучше, и ошибок не будет?
-
А на логике собрать небольшой ROM нельзя, разве?
-
И причём здесь вообще инверсия приоритетов? При освобождении мьютекса приоритет в любом случае возвращается к исходному - низкому - и ресурс должен быть захвачен более высокоприоритетным процессом. У автора просто где-то ошибка в организации вызовов ОС, раз планировщик вызывается только в прерывании таймера.
-
Это Control and Status Register. Читайте сначала доки на компонент флэш памяти MAX 10 User Flash Memory User Guide (ug-m10-ufm-16.0.pdf). Потом - на Avalon MM. Доки - это ваше все. И уже потом спрашивайте на форуме, что не понятно.
-
Авалон MM - очень простой интерфейс, даже начинающий без труда его должен понять. Так что вникайте. В этом компоненте два таких интерфейса - один простой, видимо, для команд, второй посложнее, с поддержкой пакетной передачи - для данных. ЗЫ: с verilog решили не иметь дела, а только архаичный vhdl?
-
Тогда 10М08 является мастером, который генерирует клоки I2S, а 1270 - слэйв, отдающий по этим клокам данные. Имея базовый клок 49 МГц, логично дальше работать по нему - нормальная синхронная схема. Если же им принципиально не пользоваться - его надо как то восстанавливать. Ваша схема с ФИФО должна работать без проблем (хоть и с приличным джиттером), только со стороны чтения частота должна быть гарантированно выше записывающей стороны.
-
Вы дали взаимоисключающий ответ. Ещё раз, пожалуйста. Имеется плата с ПЛИС 1270, с которой идёт мастер I2S интерфейс, где относительно MAX10 все сигналы (BCK, LRCK и DATA) - входы. С той же платы идёт клок 49 МГц, на базе которого, как вы говорите, работает I2S 1270 (через делители). Тогда получается, что интерфейсный входящий клок BCK синхронен клоку генератора 49 МГц.
-
А входящий клок на 49 МГц синхронен клоку BCK интерфейса I2S? Иными словами - это клок, на базе которого работает I2S 1270?
-
А для чего, вы можете объяснить? Пока что, насколько я понимаю ситуацию, можно делать либо: 1. Прямая трансляция сигналов со входа I2S сразу на выход на DAC. Безо всяких промежуточных буферов\памяти\фифо. Это если не требуется никакая обработка потока. 2. FIFO на входе, как у вас, ждём, пока накопится достаточное количество слов, вычитываем сразу все - обрабатываем - записываем в другое FIFO, на выходе. Интерфейс I2S на входе и выходе тактируется строго от одного аудио мастер клока. Обработка работает на бОльшей частоте, чем интерфейс. 3. DMA - слова со входа I2S сразу пишутся в нужное место в памяти для дальнейшей обработки. На выходе другое DMA. По констрейнам - надо, наверное, задать set_input_delay для сигналов LRCK и DATA относительно их BCK для входного I2S. И на выходе на ЦАП - set_output_delay аналогично для LRCK и DATA относительно их BCK. ЗЫ: так а клок BCK на входе I2S является входным сигналом относительно ПЛИС, или выходным? Вы же указывали ранее, что "максимальная частота bit clock 24 мГц, но он уже идет в обратную сторону, от 10M08... к EPM1270..."

