Лидеры

Популярный контент
Показан контент с высокой репутацией 11.04.2023 во всех областях
-
Не слушайте этого специалиста. Вам нужны электроники, их и ищите. А на вакансии электронщиков пусть идут электронщики - которых выучили академщики, с самогонщиками3 балла
-
Зачем вымещать собственное раздражение на менеджере по подбору персонала? Запишитесь на прием к руководителю и прямо так, без обидняков, все и выскажите, как ему бизнесом заниматься. 😀2 балла
-
Ну не дебилы ли?!!! \-8Ж Привет коллеге byRAM (((-8Ж1 балл
-
Блин, да в C++ Builder я программирую. И в библиотеках для написания программ под Андроид дух Явы таки имеет место быть, ибо в созданном проекте есть такая строка #include <AndroidApi.JNI.JavaTypes.hpp>1 балл
-
1. Структура должна быть упакована. 2. Размеры int, char и т.д. на разных платформах могут быть разными, поэтому следует применять типы uint8_t, uint16_t и т.д., описанные в stdint.h1 балл
-
Вроде как должно быть очевидно, что UART выдаёт символьный поток входящих данных. Который естественно обрабатывается посимвольно. О чём вам и писали. Обрабатывая его посимвольно, находим границы (начало и конец) ваших лексем. И, найдя их, считаем хеш от тех символов, которые находятся в границах лексем. Когда происходит переход за заднюю границу лексемы (обнаруживается её конец), то тут и производим поиск по таблице накопленного к этому моменту хеша. Всё вышеописанное должно быть априори известно любому более-менее опытному программисту, который когда-либо парсил строки, поступающие из UART. Это потоковая, посимвольная обработка. Без всяких буферов, строк и прочей ненужной шелухи. Быстрая.1 балл
-
Приплыли. Предлагаю сначала разобраться по примерам Вирта и Страуструпа, как выполняется разбор, а потом уже задавать глупые вопросы. Ещё одно подтверждение того, что сначала нужно изучать принципы синтаксического разбора.1 балл
-
Сочувствую Вам Данный факт противоречит с оценкой "лучший программист". Кардинально. Имхо.1 балл
-
1. SMBJ33CA1 балл
-
Корпус, КМК, не SMA. Смотрите суппрессоры в SMB.1 балл
-
Припаяйте три проводка: GND, SWCLK, SWDIO. Это отладочный интерфейс SWD. Вот это я и предлагаю Вам выяснить с помощью отладочного интерфейса. Прикошачить три проводка не так сложно, даже к корпусу с 208 выводами при наличии обычного бинокуляра (крайний случай, лучше под микроскопом). Какого типа APP_BASE? Если это указатель на 32 бита (uint32_t *), то прибавляя к нему 4, Вы получите смещение в 16 байт, а не в 4, как ожидалось. Это не играет роли. Если переход содержит ошибки, то неважно, простое приложение это из одной команды безусловного перехода или сложнейший алгоритм - результат будет один (тот же HardFault).1 балл
-
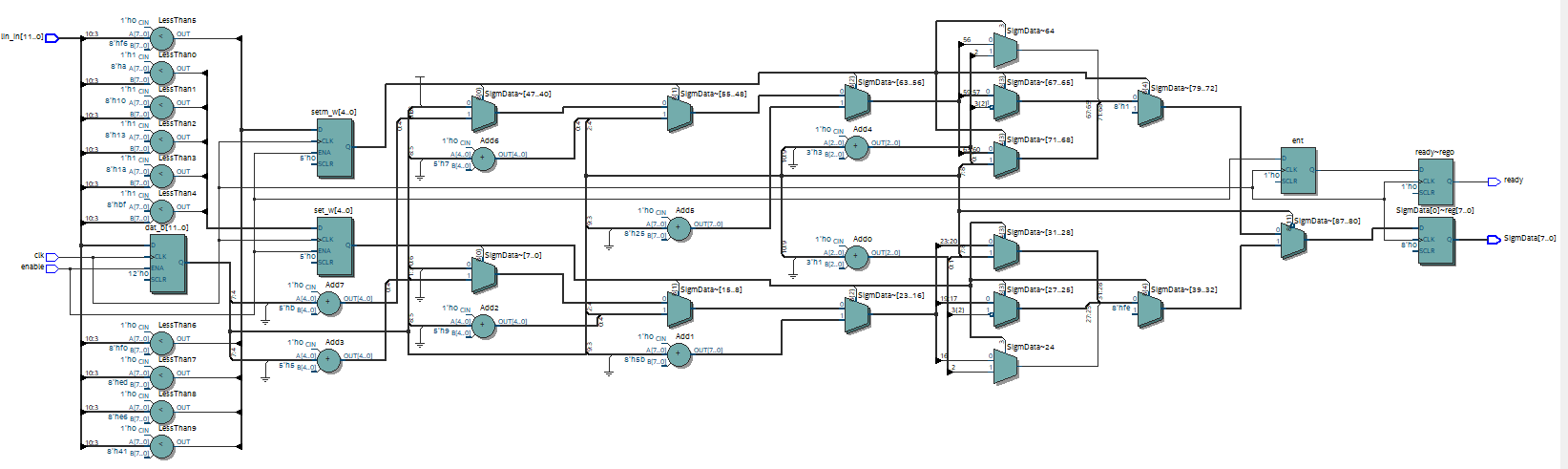
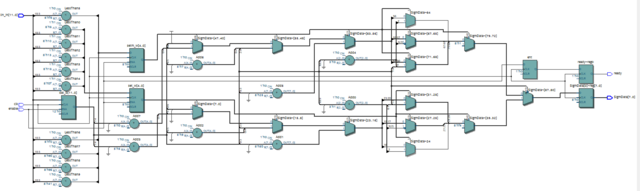
....Тут скорее важна сама идея! Настолько она проста... Я не случайно в тексте писал "Рекомендую уточнить уровень аппроксимации по формуле...", чтобы можно было организовать аппроксимацию точнее (перфекционистам в радость!). Я это делал быстро и довольно грубо, но для чернового варианта вполне сгодится, когда сеть прототипа уже обучена и известны все коэффициенты и разрядности(тут у меня большое допущение) для переноса и сквозного прогона. Итак,- тут важны 3 момента,- 1) сохранить наклон кривой y = 4*x в младших разрядах по оси Х (старшие будут участвовать с сатурации) в районе максимальной крутизны, а все остальные фрагменты уже под сжатие должны браться с наклоном из ряда степени двойки. Благодаря этому я ухожу от умножений; 2) основная трата ресурса ПЛИС на компарирование для построения диапазонов разбиения (под выбор наклона аппроксимирующего линейного фрагмента); 3) сборка рабочего кода на выход производится мультиплексорами из 11 фрагментов линейных прямых с разной постоянной составляющей (это +сумматоры). Кроме нулевой области. Я сверял со значениями формулы сами отсчеты в симуляции. Погрешность допускал +\- 5 тиков в выходном диапазоне +\- 127 (кроме краёв, где уже наступило насыщение и отсчеты особо не интересны) . Самое ответственное место нулевая область, которую я называю "зрачок нейрона". И последнее, не маловажное... Можно построить процесс моделирования самой сети и обучения из расчета именно такой (не идеальной) функции активации, чтобы уйти от академизма в подходе ради экономии ресурса. Ведь таких мест в дизайне по числу нейронов! ...Тем более в самой природе характер нелинейности вряд-ли идеален. Это должно работать! А сэкономленные умножители как раз пригодятся во взвешивании по коэффициентам!
 1 балл
1 балл -
А тем временем, трудолюбивые китайцы наконец-то выпустили вот такое чудо: https://aliexpress.ru/item/1005004148083663.html Закажу, чтобы поиграться. Интересен 2д-ускоритель. После этого камня уже точно никакие STM32 с их калокубами не интересны! Санкции отобрали хлеб У СТМ-щиков и кало-куберов! И у всех лентяев, которые дальше AVR и STM ничего не хотят изучать. Будущее - за китайскими камнями Allwinner! Те, кто успеет это понять - ждёт процветание! Если знать, что реверсить, можно для начала снять дамп всех регистров "Кедра", чтобы выявить отличия и скорректировать алгоритм. Скоре всего, дело сведётся к записи каких-то важных битов.
 1 балл
1 балл -
Ну, проблемы как-то нет, хотят товарищи называть схемотехников, топологов, конструкторов электрониками - пусть называют, не возражаю вообще. Просто заметил, что у такого подхода есть недостаток.-1 балл