nice_vladi
-
Постов
383 -
Зарегистрирован
-
Посещение
Весь контент nice_vladi
-
wavelet IDWT/DWT Simulink
nice_vladi опубликовал тема в Алгоритмы ЦОС (DSP)
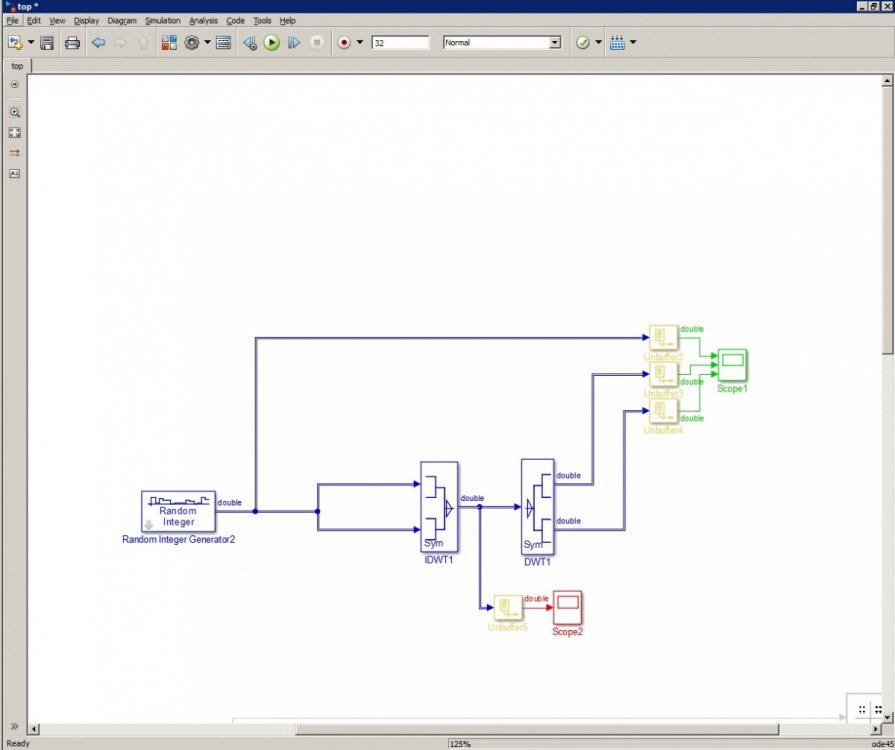
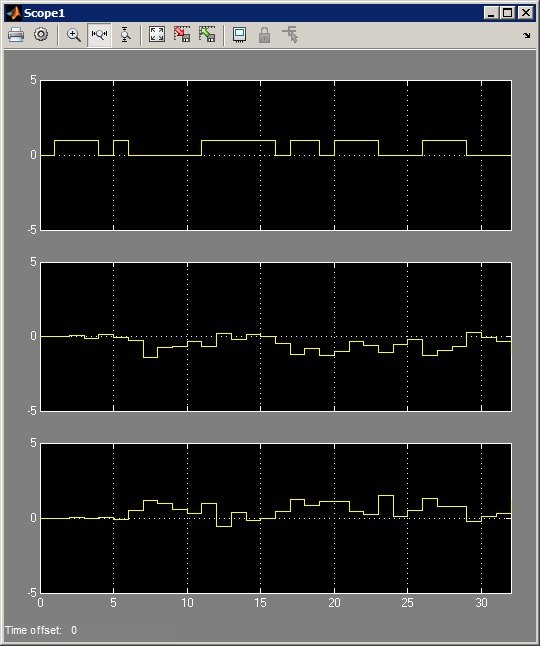
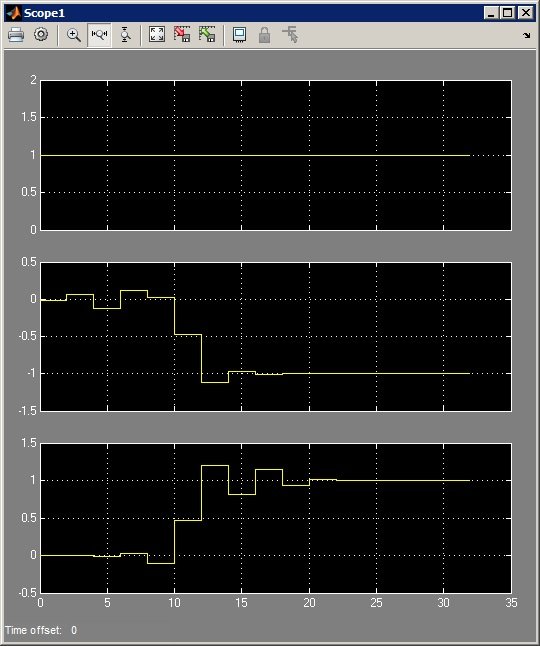
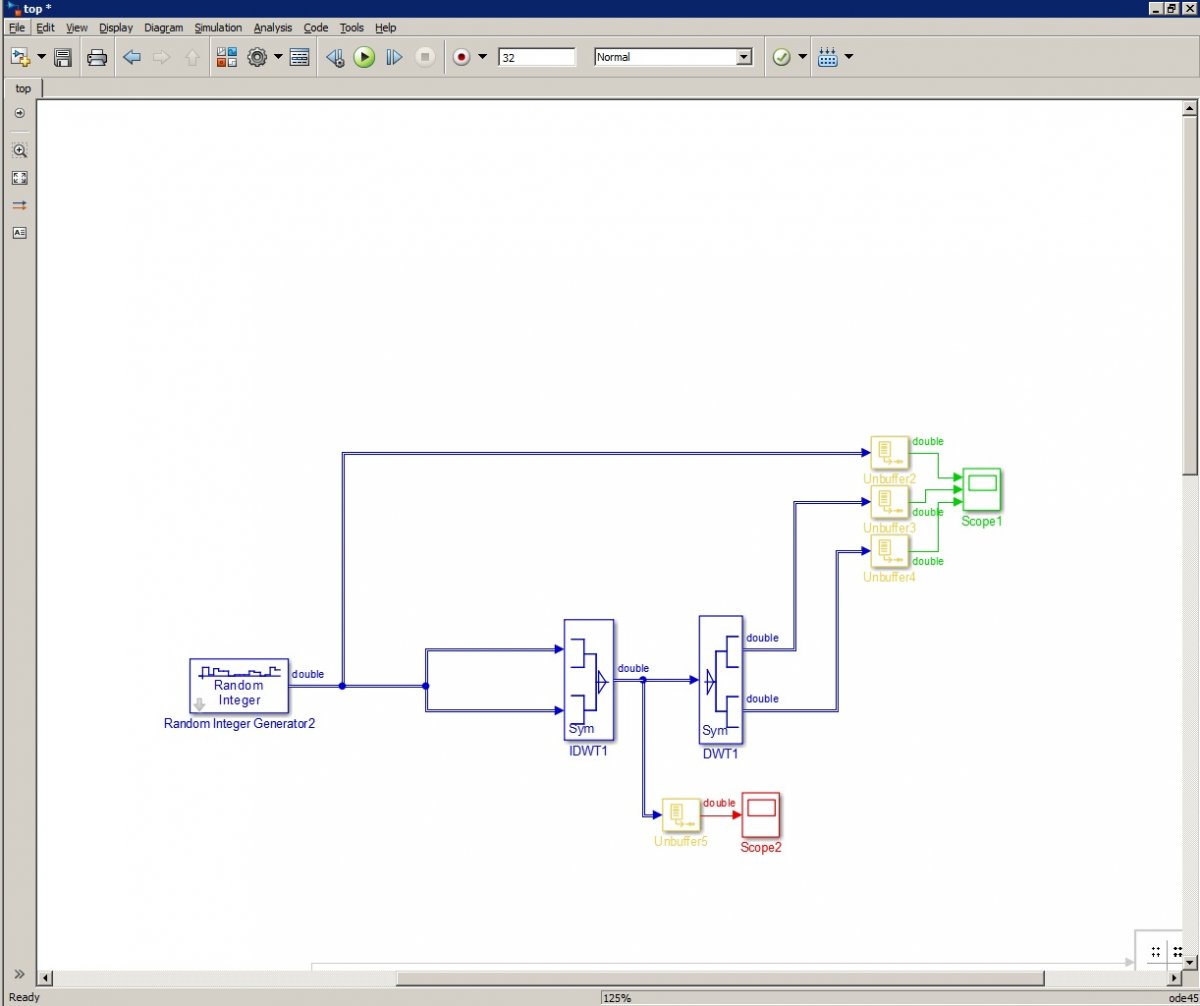
Всем привет, В Simulink собрал схему вейвлет-преобразования. Но есть нюанс: она не работает =) Значения на выходе связки idwt-dwt не соответствуют тому, что подается на вход. Базис: добеши 6го порядка. Сама схема: Графики: Входные данные + два оба выхода DWT: Со снижением базиса вейвлет-преобразования выходные данные становятся более похожими на исходный сигнал. Но почему с базисами бОльшей длины (4-6-8) все ломается? По теории же это преобразование обратимо и не должно зависит от базиса? При подачи константы на вход видно, что после выхода фильтров в режим (20 отсчетов) результат преобразования соответствует входным данным (константе = 1). Тогда почему в первом случае, после 20 отсчетов значения на выходе не соответствуют значениям на входе? Знающие, подскажите, пожалуйста, что я делаю не так? Почему значения по выходу не соответствуют значениям по входу?