_pv
-
Постов
4 363 -
Зарегистрирован
-
Посещение
-
Победитель дней
16
Весь контент _pv
-
const char hex[] = "0123456789ABCDEF"; str[0] = hex[(TWSR>>4) & 0x0F]; str[1] = hex[(TWSR ) & 0x0F];
-
Как имея в этом же юните компиляции код других функций, как правило не особо связанных (они ведь изначально в разных файлах не просто так оказались) можно ими увеличить быстродействие чего-то? Экономия инструкции call на встраивании функци, или знание что какие-то аргументы константные (-flto это поди учитывает), это будут те самые упомянутные 5%, ценой размера. Оптимизации DSP всё-таки немного про другое, эффективное использование кучи шин/алу чтобы друг другу не мешали, там действительно легко можно наговнокодить, что производительность на порядок упадёт от максимально возможной. Но наличие кода левых функций тут никак не поможет с оптимизацией по скорости. Запихивание всё в один файл с #include "scr1.c" #include "scr2.c" #include "scr3.c" ..., разве что с системой сборки может помочь, gcc all.c и всё, а не эти ваши дурацкие мэйкфайлы
-
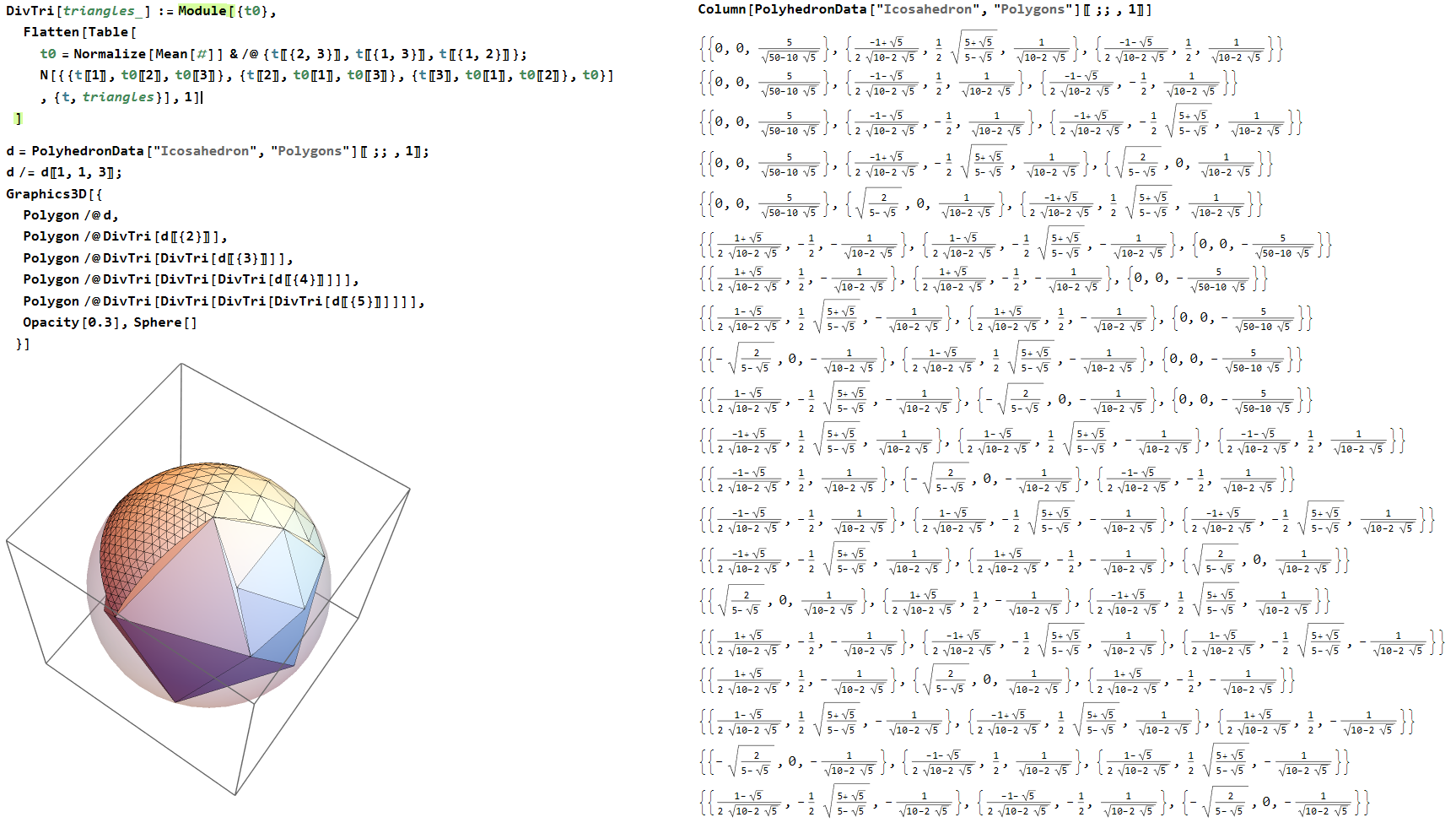
Геокупол
_pv ответил ollimir тема в Математика и Физика
Количество правильных многогранников, которые можно на сферу натянуть, с абсолютно одинаковыми (особенно треугольными) правильными гранями, можно пересчитать по пальцам одной руки (не особо аккуратного фрезеровщика), и граней там не сильно много получается. а c минимизацией количества различных типов треугольников для равномерного заполнения треугольниками сферы восьмиклассник может и не справиться. У единичного правильного икосаэдра можно делить каждую его треугольную грань на 4 треугольника, взяв середины сторон и отнормировав на единичную сферу, рекурсивно, пока не надоест. Треугольники правда получаются не совсем одинаковые, но вроде можно округлить до всего двух типов: по углам равнобедренные, по центру - равносторонний. Так, чтобы у них в пределах пары процентов длины ребер не сходились с идеалом.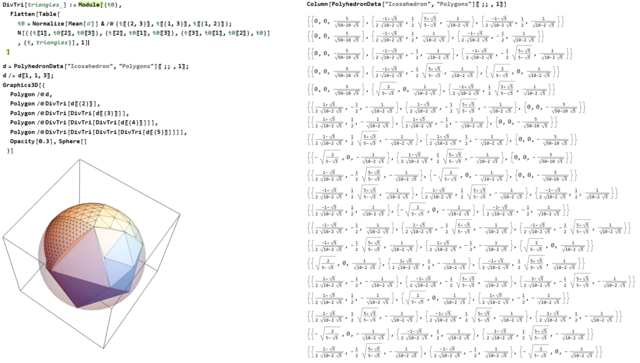
-
DC LPF
_pv ответил C2000 тема в Алгоритмы ЦОС (DSP)
простое скользящее среднее с длиной равной периоду вполне занулит, но выброс от первого полупериода всё равно будет, а своим более "медленным" фильтром (по сравнению со скользящим средним по периоду) вы этот выброс просто ещё дополнительно размазали, уменьшив амплитуду, но растянув по времени. причём интеграл от этого выброса будет неизменным и равным интегралу от первого полупериода, и делая фильтр всё более низкочастотным его амплитуду можно уменьшить только за счёт растягивания по времени.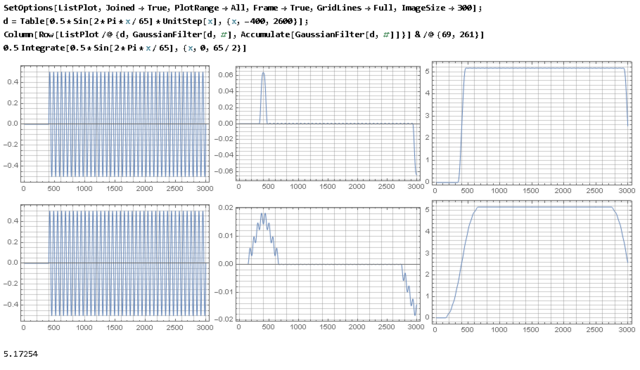
-
ну как наступите несколько раз на грабли что размеры int и long могут произвольно меняться в зависимости от архитектуры процессора и даже от компилятора. так сразу stdint.h станет понятнее и привычнее. стандарт вроде гарантирует только что размер char <= short <= int <= long, поэтому иногда встречаются и 16-ти битные char и 16-ти битные int.
-
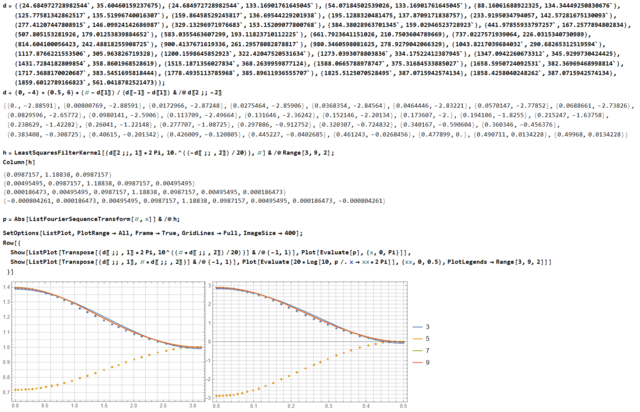
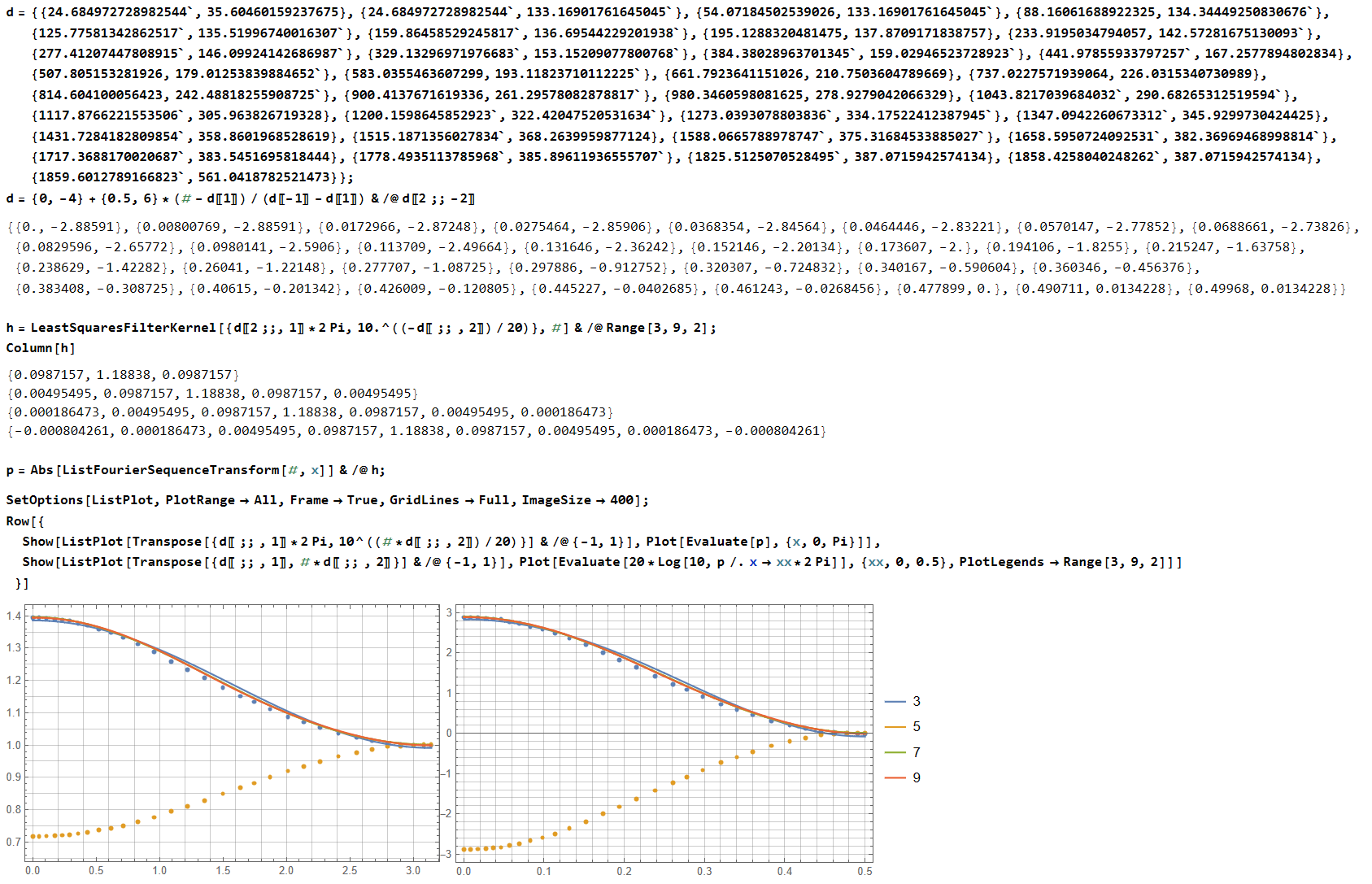
Коррекция АЧХ
_pv ответил C2000 тема в Алгоритмы ЦОС (DSP)
Mathematica, LeastSquaresFilterKernel рандомно натыкал мышкой в картинку графика чтобы точки получить, h - FIR коэффициенты для длины 3, 5, 7, 9, если с нормированием частоты нигде не ошибся.