dxp
Свой-
Постов
4 564 -
Зарегистрирован
-
Посещение
-
Победитель дней
14
Весь контент dxp
-
Альтернативы уже озвучили. Это либо кульный раннер, либо второй макс. Добавлю только, что по потреблению есть такой нюанс: в статике раннер кушает несравненно меньше второго макса, который суть FPGA. Но вот с ростом частоты потребление у раннера растет значительно быстрее, чем у макс2. И по эффективности кода макс2 может оказаться предпочтительнее - там и триггеров богаче, и ресурсы разводки обширнее. И по цене на объеме ячеек под полтыщи раннер (как и первые максы) выглядит не очень привлекательно. Т.ч. выбор очень сильно зависит от 1) объема проекта; 2) реальной тактовой. При небольших значениях этих параметров рулит раннер, при увеличении - макс2.
-
Симуляция в QuartusII и ISE 7.1
dxp ответил _VM тема в Среды разработки - обсуждаем САПРы
Только надо иметь в виду, что Ривьера - это чистый симулятор. Как Моделсим. Т.е. там нету никаких средств для запуска синтезаторов и прочих тулзов. И даже понятие проекта там совсем другое, более простое. Просто коллекция файлов, которая компиляется в библиотеку. И редактор там победнее будет, нежели в Активе. Т.ч. Вас тут может ожидать разочарование. С другой стороны, есть редакторы не хуже Активовского - тот же SlickEdit. А Синплифай запускать отдельно совсем несложно. И даже вполне удобно у него в версиях 8.х сделано окошко с сообщениями - сортировки, группировки, фильтры, цветовая раскраска. И главное преимущество, имхо, у Ривьеры - это скорость как моделирования, так и отображения waveform'ов - на здоровенных Актив заметно подтормаживает, в то время как Ривьера вообще без тормозов. И более широкая поддержка языков - даже СистемВерилог как-то умеет (а Актив 6.3 нет). В общем, следующий проект буду плотно на Ривьере лабать - мне и в Активе-то только симулятор и был нужен. А Ривьера как раз именно симулятор. Почти полный аналог Моделсима (только интерфейс у нее не такой угрюмый :) ). -
Помоделировать-то можно. Только условностей много. Регистров мало, скорости другие. И потом объемы в максах совсем не те, чтобы возникали большие проблемы с моделированием - ПЛИСки-то мелкие. Сам лично с максами почти не работал - не показались. Сразу засел на FPGA (тогда это были FLEX8000).
-
Дык вот и я думаю, что какая разница для регистра, как получен адрес - путем полной загрузки литералов или путем модификации указателя. Но ведь факт! А к обычным объектам все нормально, никаких проблем. Отслеживает именно обращения в ту область памяти. Можно, конечно, обмануть - сделать функцию в другом файле и передавать туда указатель на структуру и параметры. Тут уж он никак не сообразит. :) Но гложет сомнение, что что-то не понимаю, что какой-то нюанс есть. В доке не нашел инчего, вот и спрашиваю. А то, что на асме у них так и так попадается, так может это и ошибка - люди же писали. А примеры - на то и примеры, что ответсвенности за них никакой нет, поэтому особо никто там не приглядывался, работает как-нибудь, и ладно. Может, думаю, в саппорт написать. Только если он у них там весь индусский (как у Альтеры), то скорее всего будет тухло. То ли дело у IAR'а саппорт... :)
-
Когда ПЗУха его ("перемычки", типа, которая задает) изнасилуется, верификация проходить не будет. Либо он стираться до конца не будет, либо прошиваться. Кстати, тут может пройти такой вариант - если не стирается до конца, делать несколько стираний - за несколько он может "дотереться". :) Аналогично и с зашивкой. Но это уже посторонний вариант - микруха если сдохла, надо менять.
-
Обнаружил интересную вещь. К примеру, пишу код, инициализирующий какое-нить периферийное устройство или DMA. Там регистры, относящиеся к устройству, лежат рядышком. Из чего, вроде бы, следует, что компилятор при последовательных обращениях должен оптимизировать код - не загружать при каждом обращении полный адрес. Т.е. однажды загрузил базовый адрес и ко всем остальным переменным (регистрам) обращаться со смещением. Экономия кода (да и по скорости выигрыш), как грицца, кардинальный. На деле выходит не так: допустим, есть пять присваиваний значений в регистры MDMA, и все пять раз при каждом присваивании грузится полный адрес, т.е. дополнительные две команды каждая по 32 бита. И так, и сяк, не дается - все равно генерит этот громздкий код. (Оптимизация включена максимальная по скорости.) Ладно, думаю, обману. Создал тип структуры, соответствующей фрейму памяти, где эти регистры расположены. Далее в коде создаю указатель на такую структуру, присваиваю ему насильно базовый адрес блока регистров. Ну, думаю, теперь никуда не денется - явно код прямо написан с загрузкой адреса в указатель и обращением к членам структуры (со смещением, то есть). Но не тут-то было. Код после компиляции ровно такой же: компилятор "не поленился" вычислить абсолютные адреса в каждом случае и честно их прописывать в укзатель с последующим обращением непосредственно по адресу назначения. Вот, думаю, засада! Что же это за оптимизирующий компилятор такой?! Тупит жестоко... Но чувствую, что что-то здесь не то - в первом случае еще можно списать на тупость, но во втором-то он намеренно делает эту "деоптимизацию". Взял попробовал создать объект этой структуры в обчной памяти - все ништяк, оптимизирует, как положено: базовый адрес и далее вперед по смещениям. А вот когда лезешь в область MMRs, не канает. Ведь просек же и адрес, и код сгенерил соответствующий. Вопрос: я чего-то не понимаю, может где-то сказано, что надо всегда грузить в регистр-указатель полный адрес и только потом обращаться? Не заметил никаких ограничений на способ доступа к MMRs. Вполне понимаю, что там не все так просто, что из-за конвейера там всякие побочные эффекты могут лезть, что надо при этом всякие csync'и и ssync'и юзать. Но про способ адресации ничего не нашел. Объясните непонятку, кто знает.
-
У нас был случай, когда от множества перепрошивок сдох макс7000. Проявлялось это в том, что он перестал прошиваться - на верификации лажался. Дальше уже не проверяли - кому интересно. :(
-
LC генератор
dxp ответил ivainc1789 тема в Вопросы аналоговой техники
Эта схема очень сильно похожа (настолько сильно, что ею и является :) ) на сверхрегенеративный каскад. У этого каскада вся работа идет на пороге генерации. Сделано это специально - такие штуки используют для дешевых радиопримемопередатчиков. Имхо, в качестве ГУН она не слишком хороша. Когда-то делал ГУН на основе схемы генератора Колпитца. Вполне успешно. Схема описана в ХиХ. -
Riviera
dxp ответил Vadim тема в Среды разработки - обсуждаем САПРы
Хе, а у нас студенты тоже участвуют в разработке вполне серьезных девайсов. И что, про это тоже можно сказать, что, дескать, у них там девайсы студенты разрабатывают? Все когда-то чему-то учатся. И лучше всего это делать не на гипотетических проектах, а на реальных. И конечный результат, как всегда, определяется качеством процесса управления. Какую-то работу могут выполнять и студенты, главное, чтобы за этим процессом был контроль (отслеживание и коррекция) со стороны более старших, опытных и ответственных товарисчей. Сам факт участия в работе кого бы то ни было ни о чем не говорит. Дык самое время попробывать. Тем более, что времени это много не занимает, а результат может оказаться стОящим того. -
EPCSx в ST'ном исполнении стОит нынче чуть более четырех баксов. При использовании с Циклоном можно ее шить через Циклон же, т.е. используя его JTAG, что есть очень удобно - один разъем и на загрузку, и на отладку, и на программирование конфигуратора.
-
рекомендации по использованию FreeRTOS
dxp ответил sergik_vrn тема в FreeRTOS
Основной смысл кооперативной ОС - экономия ресурсов (когда их нет или когда их мало и не хватает для реализации целевой функциональности). Если ресурсов хватает, вытесняющая ОС - самое оно. Какой смысл иметь их обе сразу лично мне не понятно. Объясните, пожалуйста? Не могли бы Вы дать точную ссылку? -
EPCSx предполагает Active Serial режим, т.е. тактирование ей надо снаружи. А ACEX, насколько помню, может только Passive - т.е. в тех самых EPCx внутри еще и тактовый генератор есть. Есть вариант на атмеловских AT17C512 и старше - в них есть генератор. Правда, они не особенно дешевые, но может Вас устроит. Еще народ извращался путем применения пассивого конфигуратора с подачей клока снаружи. Вроде работало. P.S. Лучше всего, конечно, переползать на более новые и приятные микрухи - Циклоны, к примеру. Если, конечно, это возможно. :)
-
Riviera
dxp ответил Vadim тема в Среды разработки - обсуждаем САПРы
Я начал с моделсима. Все бы ничего, да невозможно нормально просматривать сигналы в waveform. При нажатии стрелочек (найти следующее/предыдущее значение сигнала) моделсим "думает" в течение вплоть до десятка секунд (это на моем конкретном проекте - более-менее полной статистики его поведения у меня нет - предполагаю что по мере усложнения моих проектов время будет увеличиваться) И не дай бог нажать стрелочку, если следующего изменения сигнала нет - он просто зависает. Перешел на Aldec. Там в этом плане все пристойно. Сейчас мечусь между алдеком и моделсимом, склоняясь к алдеку. <{POST_SNAPBACK}> Кста, в Ривьере (опять же по сравнению с Активом) зум на здоровенных (длинных) диаграммах происходит вообще без торомозов. Что есть большой плюс. -
Riviera
dxp ответил Vadim тема в Среды разработки - обсуждаем САПРы
У меня правда Verilog, а у Вас, видно, VHDL. Может там какие-то нюансы есть с заданием типов и целых, с этим не работал, подсказать ничего не могу. -
Riviera
dxp ответил Vadim тема в Среды разработки - обсуждаем САПРы
Это откуда такие сведения? Ваше заявление на фоне заявлений самого Альдека про характеристики данного продукта и его позиционирование выглядят как минимум странно. От себя замечу, что моделирование в Ривьере происходит значительно быстрее, чем в самом Active-HDL'е. Его тоже студенты пишут? Ривьера (в сравнении с Активом) выглядит всяко как более продвинутый продукт - она и быстрее, и организация базы данных с результатами моделирования у нее более продумана, и всякие SystemVerilog'и поддерживает (а Актив, почему-то, нет). Интерфейс у нее более расчитан на скрипты и макросы, т.е. на бОльшую автоматизацию (хотя в Активе тоже это есть, но там многое кликаньем мышкой можно делать, что привлекательно для начинающих). Т.е. меньше рюшечек, больше мощи. -
рекомендации по использованию FreeRTOS
dxp ответил sergik_vrn тема в FreeRTOS
А чего про нее знать. Она вся закрытая из себя, к сорцам добраться крайне трудно. По характеристикам (дему брал) оценивал в сравнении с uC/OS-II - пошустрее она немного (embOS) и футпринт, вроде, чуть поменьше. Уже подробностей не помню, давно было. -
А, понял - Вы имеете в виду, что вешается это на отдельный банк адресного пространства? У черного фина немножко другие сигналы и терминология, соответственно, отличается. Насколько понял, идея такая: внешнее устройство происит у проца шину, проц предоставляет, после этого по этой шине рулим флешкой как нужно. В общем, это, имхо, в смысле организации аппаратной части не очень отличается по идеологии от программирования флеши через ейный JTAG. С одной стороны, конечно, гибкости побольше и флешь с JTAG'ом не нужна. С другой стороны все-таки допольнительная микруха и разъем. Хоцца все же без дополнительных аппаратных элементов, только через штатный JTAG проца (девайс малогараритный и есть ограничения по потреблению, поэтому все лишнее тут небесплатно) и штатным эмулятором, который все равно есть... Лана, понятно, бум думать, пробовать дальше. :)
-
рекомендации по использованию FreeRTOS
dxp ответил sergik_vrn тема в FreeRTOS
Удобно иногда для буферов сообщений того же Ethernet. Понятно, что можно обойтись, но просто удобно, не приходится очередные велосипеды изобретать. А не будет ли для буферов сообщений удобнее очереди использовать? Многозадачность добровольного типа, не вытесняющая, она же кооператив. <{POST_SNAPBACK}> Как это? Вытесняющия и кооперативная ОС в одном флаконе? Одновременно работают? Что-то не понимаю как это и, самое главное, зачем? -
рекомендации по использованию FreeRTOS
dxp ответил sergik_vrn тема в FreeRTOS
А для каких применений Вам нужны счетные семафоры? Я понял, Вам их не хватает. А зачем она? От нее, имхо, только неоднозначность в работе. В каком кооперативе? -
Riviera
dxp ответил Vadim тема в Среды разработки - обсуждаем САПРы
У меня эта же версия. Вот окошко. Все есть. Только range никакого нет - integer всегда 32 бита.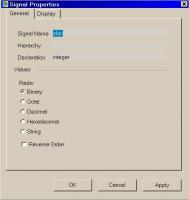
-
Прошу прощения за тупость, но не понял, что такое "один из MS"? Имелось в виду, что просто на шину разъем параллельный ставится?
-
Riviera
dxp ответил Vadim тема в Среды разработки - обсуждаем САПРы
Странно. Вот только что попробовал, все нормально - и целые, и хексы, и бинарные, и октальные, и стринги, все доступно. Какая Ривьера? -
У линуксоидов может и нет. Но я не линуксоид, и у меня есть. Все это выливается в дополнительное устройство. У меня уже есть айс. Получается, что его мало и надо городить для частной задачи еще что-то. Спасибо, этот путь понятен, он не очень привлекает. Уж проще тогда поставить флешь с JTAG'ом, которая в ките стоит, и шить ее через LPT, как советовали. Через ейный FlashLink. Но и этот путь не очень нравится - дополнительные устройства. Кста, даже в предложенном случае не все радужно - флеши-то они разные бывают, поэтому программатор получится неуниверсальным... Ладно, короче, понятно все... Спасибо всем за советы и участие. :a14:
-
Про это в курсе. Только это не то, чего хочется. Прошивка флеши - достаточно редкая, почти разовая операция. Городить для нее отдельный интефейс как-то некузяво, тем более, что один интерфейс уже и так есть.
-
Этот более прямой способ требует отдельного аппаратного интерфейса к флешке. Чего не хочется. Написать прогу, которая будет шить флешку, не сложно. Главная проблема, откуда эта прога будет брать само содержание загрузочного образа? Вот коллеги просто складывают этот образ во внешнюю память по определенному адресу. А во FlashProgrammer'e он как-то берет его по JTAG'у. Но ведь протокол обмена через JTAG закрыт. Как быть? Если связан, то вполне способ. А если нет? Еще пришла в голову мысль использовать средства автоматизации VDSP. Там ведь можно написать скрипт, который может производить разнообразные действия. К примеру, грузить прошивку программатора, потом загружать блок данных из внешнего файла (загрузочного образа) во внутреннюю память - эдак кил 16 можно легко записать, потом программатор зашивает этот блок во флешь и ждет следующего (по брейкпоинту, например) и т.д. пока все не зашьет. В общем, это пока идея, надо все проверять... Удивляет, что при таком обилии процессоров и устройств на них, такая неотъемлемая вещь каждого проекта, как загрузка флеши, до сих пор не формализована - чтобы каждый новый пользователь не ломал себе голову над этой, в общем-то, технологической проблемой. А то каждый извращается, во что горазд. :(