nice_vladi
-
Постов
383 -
Зарегистрирован
-
Посещение
1 Подписчик

Информация о nice_vladi
-
Звание
Местный
")
Посетители профиля
4 989 просмотров профиля


-
Вот это: https://github.com/hukenovs/tcl_for_fpga/blob/master/src/modify_top_info.tcl можно Можно использовать за референс, там как раз перебор параметров идет.
-
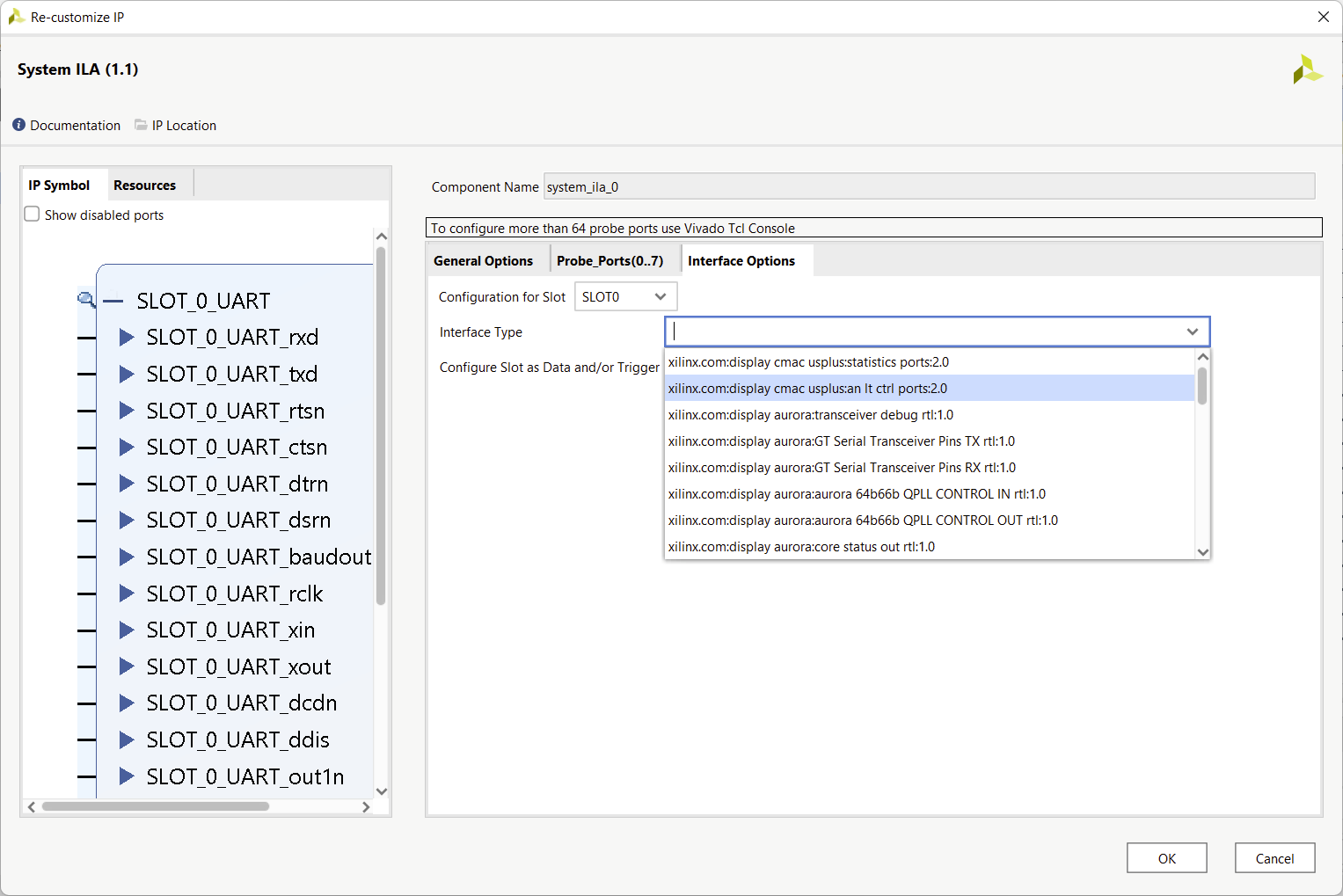
RTFM, я думаю: https://docs.xilinx.com/v/u/en-US/pg261-system-ila Ну и само ядро можно потыкать. Например, у меня выбор вот такой: Достаточно богатый выбор, я бы сказал) Жаль, что только для BD работает. Хотя, думаю, можно извратиться и сгенерированное ядро подключить куда-то в RTL.