


SergeyF
-
Постов
345 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные SergeyF
-
-
Если я не снес в гневе Q10, посмотрю, так как это очень интересно.
Либо они накосячили в синтезе (это уже перебор), либо скорректировали временные модели (что довольно странно для вполне зрелого семейства).
-
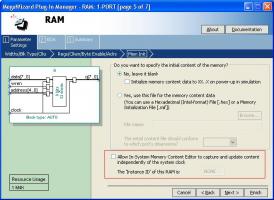
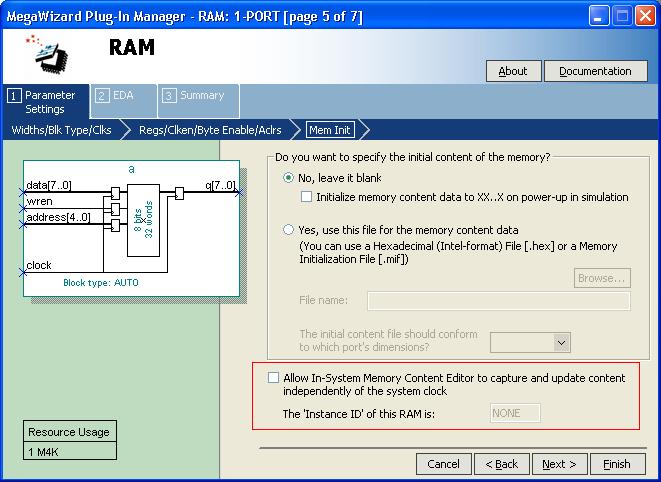
Вот здесь. Естественно, если у памяти все порты уже задействованы, то читать ее не получится.
-
У меня за мои суммарные час попыток на С8 выжать 125 МГц так и не удалось. :)
Вот проект :). Компилировался в 9.1 без SP.
-
Задача далеко за рамками обычного промышленного синтеза.
Без учета архитектуры ячейки и интерконнекта получить результаты немногим лучше 100MHz трудно.
Ну это уже не смешно. Извините, Вы то, что я выше написал, читали?
Повторюсь:
QII 9.1, Таймквест, медленная модель, 85С. На любом Cyclone III градации 6 и 7, что я пробовал, укладывается в 125МГц. Код с разбрасыванием 8 бит из 64 по входам дерева сумматоров приводить не буду - это тривиально. Он ненамного быстрее того, что я привел. Самое быстрое, что я получил на нем - 159МГц.
Это не значит, что нельзя сделать лучше - просто дальше нет интереса идти. И никаких LogicLock, архитектурно зависимых примитивов и т.д.. Чем и хороша Altera по сравнению с некоторыми другими производителями. :)
По поводу идей:
Четырехвходовые LUT на первом уровне как раз очень подходят. В отличие от предлагаемых Вами трехвходовых, они уменьшают глубину дерева сумматоров на один уровень и сами обрабатывают 4 бита в один слой логики, без переносов, которые, хоть и быстрые, но вносят задержку. Замечу, что синтезатор все синтезирует как написано без всяких примитивов - на первом уровне под каждую группу из 4 бит по 3 LUT, а далее складываем 16 (в случае с разбросом 8 бит - 14) таких сумм на 4 уровнях сумматоров. Кстати, если не разбрасывать, он очень четко делает первый уровень в нормальном режиме, а все следующие с цепями переноса.
-
Так Вы проверяете на C6, а автор просил на С8. :)
Вроде как сначала были неопровергнутые сомнения, что получится и на быстрой градации. :) На 6 и 7 градации получается. На EP3C5 даже на 8 градации модификация с разбросом 8 бит из 64-х по входам переноса в дереве сумматоров укладывается в 125МГц. Можно и дальше поколдовать с архитектурой и попробовать выжать на больших микросхемах. Но разница в стоимости между 7 и 8 градацией меня в данном случае не мотивирует. :)
Могу лишь добавить в ответ на сомнения автора темы, что если Таймквест говорит, что в худшем случае на максимальной температуре будет работать, то работать будет и полуторакратный запас по частоте совсем ни к чему.
-
Судя по Вашим оценкам экспертов, если и будет на 125МГц работать, то с натягом, сильным, и ресурсов это как-то много займет. А мне как-то не нравится, когда с натягом работает. Я спокоен только когда 1,5 кратный запас
 .
.Вам же дали ссылки. Первая ссылка немного о другом, там поиск лидирующей единицы, а вторая как раз в тему. Там много вариантов.
alexPec, уважаемый des00 был как всегда точен, тем было несколько, ищутся легко, вот пара на вскидку:Я из интереса проделал аналогичный эксперимент с CycloneIII. На медленной модели при 85С получилась частота 143,5МГц. По-моему, достаточный запас. И сама схема занимает всего 119 логических элементов (не учитывая входные регистры, без которых не посчитать тактовую частоту).
module cnt64(clk,rst,din,cnt); input clk,rst; input [63:0] din; output reg [6:0] cnt; reg [63:0] dreg; reg [6:0] comb_cnt; wire [2:0] s[15:0]; reg [3:0] s0[7:0]; reg [4:0] s1[3:0]; reg [5:0] s2[1:0]; //ones in four bits function [2:0] cnt8; input [3:0] din; integer i; begin cnt8=0; for(i=0; i<=3; i=i+1) if (din[i]) cnt8=cnt8+1; end endfunction //registers always @(posedge clk or negedge rst) begin if (!rst) begin cnt<=0; dreg<=0; end else begin cnt<=comb_cnt; dreg<=din; end end //adder tree always @(*) begin //first level s0[0]=s[0]+s[1]; s0[1]=s[2]+s[3]; s0[2]=s[4]+s[5]; s0[3]=s[6]+s[7]; s0[4]=s[8]+s[9]; s0[5]=s[10]+s[11]; s0[6]=s[12]+s[13]; s0[7]=s[14]+s[15]; //second level s1[0]=s0[0]+s0[1]; s1[1]=s0[2]+s0[3]; s1[2]=s0[4]+s0[5]; s1[3]=s0[6]+s0[7]; //third level s2[0]=s1[0]+s1[1]; s2[1]=s1[2]+s1[3]; //fourth level comb_cnt=s2[0]+s2[1]; end //preadders genvar j; generate for(j=0; j<=15; j=j+1) begin : os assign s[j]=cnt8(dreg[j*4+:4]); end endgenerate endmodule
P.S. При включении Fitter effort = Standard получается 156МГц, а при задействовании входных переносов в дереве сумматоров (как предложено в указанной выше теме) и избавления, таким образом, от одного сумматора первого уровня, комбинаторика получается еще на 7 элементов меньше и частота поднимается до 159МГц. Можно и дальше оптимизировать и искать варианты, но требования и так выполняются с запасом.
-
Мне в свое время больше всего понравился Г.Стренг, Линейная алгебра и ее применения. Djvu находится легко.
-
Как будет верно?
Для однобитной переменной, конечно, без разницы, как. IMHO, ptr1=~ptr1 как-то понятнее, так как в случае с if Вы присваиваете однобитной переменной 32-х разрядное целое число. Оно обрезается до 1 бита. В обоих случаях получается 0-1-0-.... Я при беглом просмотре кода подумал, что и ptr1, и ptr2 многоразрядные. Там, естественно, получается по разному. Кстати, в плане читаемости не стоило так называть два указателя с разной разрядностью и объявлять их в разных местах.
Замечу, что если оно не работает как надо, то проблема не в том, на каких ресурсах реализуется память, а в том, что манипуляция адресами происходит как-то неправильно. Прогоните в симуляции процесс записи - все сразу станет видно.
Как определить способ реализации памяти?Посмотреть отчет компилятора или в навигаторе проекта в иерархии.
Вы делаете два буфера, которые пишете/читаете пинг-понгом. Один, насколько понимаю, выводите на шину системы на кристалле как avalon slave. Вам правильно посоветовали запустить мегавизард и настроить RAM, dual-port. В данном модуле останется только адресация и создание экземпляра модуля памяти.
Но так как сейчас у Вас описана асинхронная память, а в StratixII это сделать не получится, то логику управления адресами придется переработать на чтение/запись памяти с синхронными входами.
-
По крайней мере, результат работы в обоих случаях одинаков.
В смысле результат одинаков? Без модификации ptr1 и с ней? И он правильный? И объем проекта тоже одинаков? Буфера ложатся в блочную память или реализуются в регистрах?
По ptr1 - да, перепутал с ptr2. :rolleyes:
Если я хочу что-то положить в блочную память, я делаю мастером модуль памяти. :)
-
Сорри, пример оказался рабочим.
Жестко Вы с буферами. Они же не влезут сами в блоки памяти. А по времени компиляции, думается, он в первом случае выкидывал весь Ваш декодер (так как указатель не менялся) и компилировал проект системы на кристалле, а во втором старательно рассовывал ~30 тысяч триггеров по кристаллу в дополнение к этому.
И еще я на всякий случай хотел уточнить. Вот это:
//ptr1 <= ~ptr1;
//if (ptr1==1) ptr1<=0; else ptr1<=1;
Это же разные вещи...
-
Стоит для начала разобраться с примерами на основе NiosII. На всякий случай уточню - а как Вы без процессора собираетесь TCP/IP стек поднимать? Или у Вас в системе уже процессорное ядро есть?
-
а 4в1 это два, а не три слоя %) Хотя некоторые синтезаторы считают по другому %)
Интересно, это у каких синтезаторов все так плохо?
А 32 в 1 - это пять слоев! А по-проще - никак?А если каждый N объединить с входным сигналом, а потом всех их объединить по И с применением цепей каскадирования (а в Циклоне их, кажется, уже нет :( ) - то будет 2 (два) слоя.
Ну в какой-то степени настройка Restructure Multiplexers дает возможность поиграть с ними. Но не радикально. А в цепи каскадирования в FLEX/ACEX, помнится, задержка была порядка задержки на одном элементе, так что это ничего не даст. :) Поможет ALM в Stratix, там как раз 4 в 1 вроде бы в один ALM влезает. :)
-
Вообще-то это играет роль. Не вдаваясь в то, как работает PLL, скажу, что Quartus это контролирует при моделировании. Посмотрите повнимательнее. В Вашем же проекте при подаче 50МГц начиная примерно со 100нс на выходе появляется нормальный сигнал 100МГц. До этого - X.
-
Надо подать в тестовом векторе 50МГц а не как сейчас.
-
Ну вот опять :) Вот тема про нахождение старшего значащего бита. IMHO, простой путь добиться разумного соотношения быстродействия/объема - факторизовать схему на модули, аналогичные приведенному топикстартером.
А мультиплексоры в базисе ПЛИС это все же не самая эффективная с точки зрения быстродействия функция (т.е. стремиться выделить мультиплексоры при описании схемы - не всегда лучший путь при ручной оптимизации). Грубо говоря - 2 в 1 - и вот уже один слой логики в ПЛИС с четырехвходовой таблицей перекодировки.
-
во-во, уже 2 темы точно было, про LVDS и про PLL, сильно различаются документы. посмотрел последний даташит - там от раздела 1 страница осталась, типа "квартус сам за всем следит, в нем и копайтесь"
Точно, а в документации на Квартус в главе 5 приводят примеры и пишут : For more detailed information about each I/O rule, refer to the appropriate device handbook. :smile3046:
-
Если используете CIII, то в описании сказано, что нужно для стандартов 3,0V и 3,3V иметь одну разделительную площадку между DCLK и прочими I/O для минимизации шумов (корпус QFP). Quartus всегда проверяет это ограничение.
Кстати, интересно. Это в какой версии документации и Quartus?
Я просмотрел документацию на CycloneIII и в конце раздела 6 I/O Features в списке изменений нашел только одно упоминание от 2008 года о внесении в документацию раздела DCLK Pad Placement Guidelines. В текущей версии этого раздела таких ограничений нет.
Попробовал - в корпусе TQFP144 первый попавшийся проект лег нормально как с входом, так и с выходом на ножке 11, как в стандарте 2.5В, так и 3.3В в этом банке. Это в QII 9.1.
-
"Error: Cannot place I/O pin sdram_dq[8] with I/O standard 3.3-V LVTTL in pin location 11 -- possible switch coupling with I/O pin epcs_dclk in pin location 12."
можно это как-нибудь обойти? epcs_dclk используется только при конфигурации.
Может, подойдет настройка для снятия ограничения на расположение рядом с дифф. линиями - I/O Maximum Toggle Rate? Поставить 0 МГц.
-
Дааа.... более сырой версии QII я не припомню. Про установку я не говорю, заливка рабочей области логотипом - это мелочи, придирка эстета. То, что русские комментарии вообще не дает вводить - может, это и правильно. :)
Открыл проект в NiosII SBT for Eclipse - при компиляции пошли ошибки запуска процессов, которые были и раньше под Windows 7.
Решил перегенерировать/перекомпилировать проект аппаратуры - SOPC Builder ругнулся на устаревший тип компонента PLL. Удалил (зря, теперь его в списке компонент нет, даже устаревших, без манипуляций ручками не вернуть). Поставил компонент Avalon ALTPLL - при генерации вылетают предупреждения по поводу несоответствия портов модуля TCL описанию, после генерации тащит на верхний уровень системы порты clkena, о которых его никто не просил...
Дальше не пошел. Жду SP1. Ужас.
-
-
Очередной раз нуждаюсь в помощи! Мне нужно создать асинхронную ПМК (память микрокоманд), так что бы пришел адрес - вышла нужная микроинструкция, пишу на VHDL, работаю в Quartus. Знаю что в MegaWizard есть синхронные памяти, но они мну не подходят. и с исходниками тяжело разбираться. Есть *.hex файлы, я не знаю как их подключать и производить чтение, помогите пожалуйста разобраться, дайте пример или ссылку на литературу, что бы почитать, я сам не нашел. За ранее благодарю!!!
Разумнее адаптировать структуру микропрограммного устройства под архитектуру ПЛИС. Сделайте регистр адреса на встроенных в блок памяти триггерах, а выход памяти в асинхронном режиме. Будет асинхронная ПМК. Для этого запускаем мастер ROM, 1-port, настраиваем соответствующим образом регистры и указываем файл инициализации .hex.
Пока все делается в учебных целях. И задача поставлена сделать асинхронную память.Я бы сказал, что эти изыскания надо проводить, не говоря слов Quartus, ПЛИС и т.д.., если бы не возможность сделать асинхронную память на MLAB в Стратиксах, начиная со второго.
И не подходит это для учебных проектов! Чтобы было нагляднее: если студенту-двигателисту дадут учебный проект, в котором бензиновый двигатель будет заправляться дизельным топливом - это будет правильно методически?
P.S. Поправка : начиная со Stratix III, а не Stratix II
-
да-да. "вычислительная" действительно лишнее слово, но термин "управляющая система" обычно употребляют для управления каким-либо физ.объектами (станками самолётами), а более важно, что есть некоторое качество обслуживания - вот например сетевой коммутатор вряд ли будет ассоциироваться с термином "управляющая система", хотя они фактически братья близнецы с управляющей системой в плане организации процессов.
В целом согласен, но в контексте статьи термины автоматически привязываются к конкретной предметной области. Кстати, с коммутатором термин "вычислительная" как раз не очень хорошо увязывается. Может быть, стоит уточнить, но каким-то другим термином, например, "цифровая".
-
понятно объяснился?
Ну тогда логично. Как вариант - система потоковой обработки данных и управляющая система, без слова "вычислительная". Всплывает еще термин "reactive system", но у него тоже нет достойного перевода - "реагирующая система" звучит плохо.
-
Может быть, сделать достаточно общепринятую кальку - система с управлением последовательностью команд/с управлением потоком данных?
Вроде бы так так обычно переводится dataflow/control flow.
Это не совсем точно, но "управляющая вычислительная система" - тоже не совсем точно, так как по сути в описании и в исходном термине на английском речь идет об "управляемой вычислительной системе". То, что она, как правило, одновременно является с точки зрения функции и управляющей, не следует из перевода.
Шины разной разрядности
в Языки проектирования на ПЛИС (FPGA)
Опубликовано · Пожаловаться
Можно так:
wire [31:0] q;
assign q[31:18] = data1[13:0];
...
Или так:
reg [31:0] q;
always @(*)
begin
q[31:18] = data1[13:0];
...
end
Еще проще так:
wire [31:0] q;
assign q={data1,addr,data2};
Или так:
reg [31:0] q;
always @(*) q={data1,addr,data2};
Мультиплексировать оператором case.