


SergeyF
-
Постов
345 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные SergeyF
-
-
ttf и rbf - близнецы. Просто один в двоичном виде, другой в текстовом. Копируйте из текстового редактора ttf кусками, вставляйте в исходник для atmega и редактируйте длину и начальный адрес записи этого блока.
Но это странно. Действительно, как говорит ViKo - лучше написать программу, которая принимает данные по RS-232 и программирует at45db.
-
Моя проблема в том, что надо конфигурировать EP1K50 (Acex 1K), файлы .rbf проекта весят 98кбайт, а пытаюсь конфигурировать Атмегой 32.... Хочу попробовать разбить rbf и по кусочкам заливать его в микросхему памяти (at45db). А потом из памяти уже в ПЛИС.
Просто порезать на куски любого удобного размера. А откуда Вы его будете брать "по кусочкам"? Кто будет программировать ПЗУ?
-
Никак. Это основы науки о тестировании - сам программист не должен тестировать свои программы. :laughing:
Хорошо, тогда как доказать корректность тестбенча, который кто-то разработал? :laughing:
Недавно делал один модуль - в определенный момент я уже мог по входным воздействиям и тактам доказать, что он правильно работает, он уже работал в железе, а написать корректно работающий тестбенч и прогнать его мне удалось в последнюю очередь. Таким образом, если сложность разработки тестбенча превышает сложность разработки тестируемого модуля, а вероятность ошибки при проектировании обоих допустить равной, получается плохо. Это меня и мучает.
-
Простите за оффтоп, но с недавних пор меня мучает один вопрос - как доказать корректность тестбенча, который ты сам разработал?
-
Ха, я же в соседней теме недавно поднимал этот вопрос!!! Видать хорошо я объясняю что мне надо...
А та же фигня для переменных-массивов прокатит?
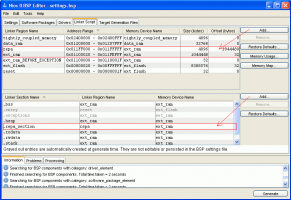
А зачем? Лучше зайти в BSP Editor и там на странице linker script порезать нужный memory device на несколько секций. На рисунке пример - мы отрезали от ext_ram старшие 4096 байт и создали регион памяти с именем repa. Потом ниже в этом регионе создали секцию .repa_section.
А в приложении пишете:
INT8U repa_data[4096] __attribute__ ((section (".repa_section")));
-
GCC прекрасно понимает ассемблерные файлы , имеющие расширения , *.s *.S , поскольку использует , по умолчанию , GNU Assembler из GNU Binutils .
И тут прекрасно понимает. :)
Вам необходимо разобраться как сделать тоже самое для НИОСа . Не забудьте поделиться результатами .Вот ниже пример - берем, создаем Hello MicroC/OS-II, и там куча ассемблерных файлов в порте - можно использовать как пример. Передача параметров в функции рассмотрена в NiosII Processor Reference Handbook, Section II.7 Application Binary Interface.
-
результат примерно тот же. Связи с регистром r2 нету переменной r2 тоже.
Sergey'F подскажите, где это указывать. По настройкам пробежал - не увидел. Или это надо ручками прописывать?
Сам регистр r2 тут ни при чем. Это же переменная. Вообще, у компилятора gcc куча флагов, с которыми его можно вызывать.
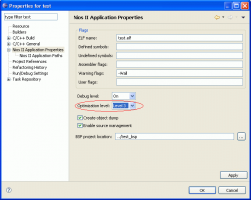
Диалог настройки параметров проекта ниже.
-
На всякий случай спрошу - а оптимизацию, например, -O3, включили? Обычно неплохой код генерирует. И регистры как надо использует, держит в них значения. Кроме того, переменная, которую хочется разместить в регистре, с большой вероятностью окажется в кэше... так что пусть себе обращается к памяти.
-
может знает кто как под альтеру для моделсима библиотеки стандартных элементов скомпилить, понятно что квартус будет это за тебя делать, но после хилых привык как-то отдельно работать с симулятором через скрипты
Не совсем понятен вопрос. Вот это двумя постами выше не подходит?
В ModelSim-Altera Edition библиотеки уже предкомпилированы и перекомпилироваться не должны, а для других не-альтеровских версий ModelSim можно их откомпилировать и использовать откомпилированные версии, используя EDA Simulation Library Compiler.На всякий случай - Tools>Launch EDA Simulation Library Compiler в меню Quartus.
-
На симуляции (сразу после курсора) - в последний разряд sample_out дописано parity (1) хотя должно бы range_2_parity (0)
Вроде логично.
Вопрос - как исправить? Что приходит в голову - дополнительный задержанный на клок sample_strobe_in и по нему делать if во втором always. Т.е. проверку условия counter делать на такт позже его изменения. Правильно ли я думаю? Так ли это принято делать?
Но как тогда сделать чтобы данные (sample_out) не появились позже чем их строб (sample_strobe_out)? Задерживать и его тоже?
Вроде бы все соответствует описанию. Ведь и sample_out, и counter - регистры по приведенному описанию. Соответственно, sample_out изменится на следующем разрешенном такте после перехода counter в 0. Как исправить? Приведенное Вами предложение, если допустимо задержать данные на еще один такт - логичный вариант.
-
По поводу повторного запуска EDA RTL Simluation - все равно получаю ошибку, гласи она следующее:
"error deleting msim_transcript": permission denied
Check the NativeLink log file ....
На счет повторного запуска команды do <имя проекта>_run_msim_rtl_verilog.do - запускается, и моделсим начинает заново компилить все библиотеки, что есть время =/
Правильно, если из-под Квартуса запускать RTL, то надо ModelSim закрыть. А на чем у Вас тратится время? Компилирует он то, что написано в do файле (команда vlog). А при запуске команды vsim он запускает моделирование и подключает все используемые библиотеки. В ModelSim-Altera Edition библиотеки уже предкомпилированы и перекомпилироваться не должны, а для других не-альтеровских версий ModelSim можно их откомпилировать и использовать откомпилированные версии, используя EDA Simulation Library Compiler.
По поводу функционального и временного моделирования - функциональное быстрее, не требует полной компиляции и позволяет изолировать чисто логические ошибки. Разработчики, использующие только возможности Quartus при работе со встроенным симулятором часто полностью компилируют проект, а потом запускают моделирование. По умолчанию запускается временное. Но это не отменяет того, что там, до того, как убрали встроенный симулятор, функциональное тоже было. Такая возможность была. :)
Поэтому здесь два вопроса. Первый - интеграция функционального моделирования в маршрут проектирования. Второй - переход от задания входного воздействия в виде временных диаграмм к созданию тестового окружения, формирующего входные воздействия и каким-то образом обрабатывающего выходные сигналы, на языке.
-
Если честно моделировать не особо хочется, плата пустяковая. А клампинг диод обязательно нужен? По умолчанию квартус включается его выборе стандарта 3,3В.
Мне всегда казалось, при выборе стандарта 3.3/3.0В его вообще не отключить. Не так?
-
любимый редактор <-> моделсим -> квартус -> таймквест -> работа в реальном железе
А что мне делать, если меня редактор Quartus устраивает? :)
Автору темы: для функционального моделирования:
1. Настраиваем testbench.
2. При внесении изменений в проект его не надо полностью перекомпилировать в Quartus - достаточно запустить Start Analysis and Elaboration.
3. Запускаем EDA RTL Simluation.
Для моделирования с задержками:
А чем EDA Gate Level Simulation после полной компиляции не устраивает?
Изучайте технологию моделирования в ModelSim. Тогда поймете, что именно NativeLink складывает в папку simulation и как зупускается моделирование. Небольшая подсказка: если посмотрите транскрипт вывода в ModelSim после запуска из-под Quartus, то в начале там подается команда:
do <имя проекта>_run_msim_rtl_verilog.do
Вот и запустите ее заново после изменения исходного текста модулей и их сохранения (в любом редакторе :)).
встречный вопрос: а нафига? исправлять-то все равно придется в коде. делайте все в моделсиме, потом анализируйте в тайсквесте.Ну а почему бы не сделать gate-level simulation? Понятно, что в большинстве случаев функционального моделирования и статического временного анализа достаточно, но на поздних этапах проектирования делать прогон на gate-level или не делать - это вопрос технологии, применяемой конкретным разработчиком.
А то человек спрашивает, как ему промоделировать, а ему сразу методологию навязывают, в которой это моделирование некошерно. :)
-
Еще вопрос - от чего защищаться собираетесь? В datasheet приведен допустимый процент времени превышения над 3.95В в результате выбросов, чуть не в самом начале характеристик. Это если моделировать будете.
-
который кстати, при формальном подходе, не является списком чуствительности, а является оператором ожидания.
Я бы только уточнил, что он является не оператором ожидания, а объявлением события.
-
alexadmin, des00, извините, а вы не о разных вещах говорите? Я например, под перекосом понимаю разницу во времени прихода сигнала в разные точки устройства. А задержка - это собственно задержка распространения от источника до приемника.
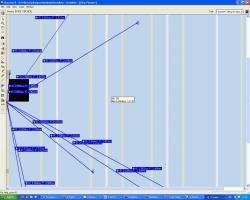
Все-таки деревья тактирования стараются выравнивать по перекосу. То есть, задержка большая, а перекос, даже по разным углам кристалла, будет небольшим. Вот для примера скриншот ChipPlanner для немаленького и медленного Cyclone IV E. Выделены задержки на выходе с clock control block для clock и reset. Схема - просто 8-ми разрядный регистр:
module testskew ( input clk, reset, input [7:0] din, output reg [7:0] count ); always @ (posedge clk or posedge reset) begin if (reset) count <= 0; else count <= din; end endmodule
Пару триггеров я кинул в произвольные места кристалла сам, еще один сделал Fast Input, а другой Fast Output. Остальные 4 разбросал Quartus. Результат - по кристаллу перекос порядка 0.1нс, до триггеров в элементах ввода-вывода задержка просто другая, но тоже выровненная (3нс вместо 2.5нс - в StratixII аналогично, сталкивался уже).
Очень интересно увидеть именно пример перекоса более 1-2нс, а не задержку в глобальной линии тактовых импульсов.
-
А вы знаете какой у нас на работе скандал была когда закупили лицензионный Q10.1, а оказалось там Vector Waveform Editor отсутствует...
Самое смешное, что в месте к Квартусом купили еще (отдельно) модельсим - самую навороченную версию(!). И это для того чтобы работать с MAX7000(!). Но никто им пользоваться (кроме меня B) ) не умеет. Потому что никто не юзает HDL, а про тестбенчи вообще не слышали..
Но лицензия ведь не привязана к версии. Можно работать с той же лицензией на 9.1SP2.
-
DMA в домене приемника, на клоке 80 МГц, между дма и источниками стоит фифо двухклоковое входной - источник, выходной - дма (80мгц). Так вот я пробовал коммутировать клок логическим И от источников на клок входного потока фифо - не катит.
Если хватит памяти, то идеологически правильнее поставить два двухклоковых FIFO с разными входными частотами, а мультиплексировать их выход, который у обоих будет читаться на частоте 80МГц.
Как вариант, так как переключение осуществляется редко, можно попробовать поиграть с переконфигурацией PLL. Т.е. сделать выход, у которого частота и фаза (через множители, выбор входного ТИ и т.д.) будут определяться загруженной конфигурацией.
-
а приемник (SGDMA) на мультиплексированном, а значит задержанном клоке.
А этот DMA в составе системы на кристалле? Не знаю, как Вы пересинхронизируете дальше, т.е. в каком домене находится приемник. Но не лучше ли поставить DMA в домене приемника? Тогда на входе DMA ставится мультиплексор, а перед ним по каждому входу ставится логика перехода между тактовыми импульсами - один блок с 20МГц, другой с 5.18МГц в домен тактового импульса DMA и приемника.
-
ну это я в википедии прочитал. Если открыть англ версию, и ввести Combinational logic , то в скобочках указывается In digital circuit theory, combinational logic (sometimes also referred to as combinatorial logic). Хотелось вот и узнать , почему применяют 2 разных термина для объяснения одного и того же.
Все эти кальки - суть перевода, кем-то и когда-то сделанного и более устоявшейся версии. Да, традиционно более правильный термин - комбинационная логика. Но как на Западе, так и у нас, "безграмотные инженеры", в том числе из компании Mathworks, делающей продукт Matlab, и даже во многих университетах, часто используют термин "combinatorial", а не "combinational" (замечу, что чаще они из области Electrical Engineering). Если человек хорошо знает мат. логику (например, за границей - из области Computer Science), ему это может не понравиться, так как действительно есть "правильная" область под названием "комбинаторная логика". А так как кальки идут и в русском переводе, то и у нас встречаются оба варианта.
Кстати, термин "последовательностная" мне нравится гораздо больше, чем нерусская калька "секвенциальная", но я никогда не возмущаюсь. Как и в случае с триггерами, которые с динамическим/потенциальным управлением - синхронизацией по фронту/по уровню, или автоматы с единичным кодированием/с одной активной единицей и т.д. и т.п.....
Совет - если Вам встретился человек, так сильно настаивающий на корректности терминов, которые по сути являются калькой, не спорьте. Бывает, что для него это важно, бывает, что это просто занудство и самоутверждение. Спорить бессмысленно, как и в других областях, только холивары разводить.
-
Создайте отдельно BSP без приложения, там будет пункт создания BSP c uC/OS-II. Все файлы, включая нужный Вам includes.h, добавятся автоматом. А потом отдельно приложение и привяжите его к этому BSP.
-
может я конечно что и пропустил , но почему число циклов ограничено?
По даташиту - вот только что спрашивали про MAXII. :)
-
LE RAM - это то, на что хочется надеяться, или она собирается на триггерах?
С трудом нахожу отличия от MAXII:
- ушел встроенный регулятор
+ появилась пара крохотных устройств в линейке
+ появились LVDS/RSDS
+ 1000 циклов перезаписи UFM в коммерческом диапазоне и по-прежнему 100 в индустриальном.
В чем идея? Ему честное имя - MAXIIE. :)
-
Что, собственно, и возвращает нас к начальному предложению расписать все в виде таблицы. ч.т.д.Но так пока получается только расчетом нужных таблиц "в лоб" :crying: :
Придется еще все на VHDL переписать. :)Ну вот щаз еще дождусь ответа Leka - и все, оформляю как полугодовой НИР))) :)




Какую структру имеют файлы прошивки формата .RBF?
в Работаем с ПЛИС, области применения, выбор
Опубликовано · Пожаловаться
Это, конечно, полезно :). Но я имел в виду другое. Как обойтись без редактора, умеющего работать с двоичными данными.
Вот кусок .rbf: FF FF 62 FF 36 00 FF (то, что записано в файле в двоичном виде по байтам)
Вот кусок .ttf: 255,255, 98,255, 54, 0,255, (текст)
Но данные одни и те же. Просто из .rbf легко получить .hex или .bin для программирования. А из ttf проще копировать данные для инициализации массивов в C. Вам нужно второе.