


ilkz
-
Постов
132 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные ilkz
-
-
Прошу прощения, да, на входе компонента были мультиплексоры.
Добавил задержки, триггеры, но моделирование все равно показывает ерудну:
module sw_phy ( input reset, input clk, input [3:0] channel, input set, input get, output sw_d_io, output sw_d_oe, output sw_d_dir, output sw_d_clk ); localparam SET_MASK = 4'b1100; localparam GET_MASK = 4'b1010; wire sys_clk; wire locked; wire sys_reset = !locked; sys_pll sys_pll ( .inclk0 (clk), .c0 (sys_clk), .locked (locked) ); reg [3:0] txbuf; reg tx_oe; reg mask_sel; reg [1:0] bit_cnt; reg d_hi, d_lo, ddout_oe; always @(posedge sys_clk, posedge sys_reset) begin if(sys_reset) begin #1; txbuf <= 0; tx_oe <= 0; mask_sel <= 0; bit_cnt <= 0; d_hi <= 0; d_lo <= 0; ddout_oe <= 0; end else begin if(set) #1 mask_sel <= 1; if(set | get) begin #1; txbuf <= channel; bit_cnt <= 0; tx_oe <= 1; end if(tx_oe) begin if(bit_cnt < 3) #1 bit_cnt <= bit_cnt + 1; else begin #1; tx_oe <= 0; txbuf <= 0; bit_cnt <= 0; mask_sel <= 0; end end #1; d_hi <= tx_oe ? txbuf[bit_cnt] : 1'b0; d_lo <= mask_sel ? SET_MASK[bit_cnt] : GET_MASK[bit_cnt]; ddout_oe <= tx_oe; end end ddr_outblock ddr_out ( .outclock (sys_clk), .oe (ddout_oe), .datain_h (d_hi), .datain_l (d_lo), .dataout (sw_d_io) ); assign sw_d_clk = sys_clk; endmodule
-
А если я переписал DDR-регистр самостоятельно, то как можно компилятору указать, чтобы он засовывал оба триггера (pos-edged и neg-edged) в один pin?
-
Опубликовано · Изменено пользователем des00
используйте codebox для оформления больших частей кода (с) модератор · ПожаловатьсяДа, вся схема синхронная. Приведу код:
module sw_phy ( input reset, input clk, input [3:0] channel, input set, input get, output sw_d_io, output sw_d_oe, output sw_d_dir, output sw_d_clk ); localparam SET_MASK = 4'b1100; localparam GET_MASK = 4'b1010; wire sys_clk; wire locked; wire sys_reset = !locked; sys_pll sys_pll ( .inclk0 (clk), .c0 (sys_clk), .locked (locked) ); reg [3:0] txbuf; reg tx_oe; reg mask_sel; reg [1:0] bit_cnt; always @(posedge sys_clk, posedge sys_reset) begin if(sys_reset) begin txbuf <= 0; tx_oe <= 0; mask_sel <= 0; bit_cnt <= 0; end else begin if(set) mask_sel <= 1; if(set | get) begin txbuf <= channel; bit_cnt <= 0; tx_oe <= 1; end if(tx_oe) begin if(bit_cnt < 3) bit_cnt <= bit_cnt + 1; else begin tx_oe <= 0; txbuf <= 0; bit_cnt <= 0; mask_sel <= 0; end end end end ddr_outblock ddr_out ( .oe (tx_oe), .outclock (sys_clk), .datain_h (tx_oe ? txbuf[bit_cnt] : 1'b0), .datain_l (mask_sel ? SET_MASK[bit_cnt] : GET_MASK[bit_cnt]), .dataout (sw_d_io) ); assign sw_d_clk = sys_clk; endmodule
-
Опубликовано · Изменено пользователем ilkz · Пожаловаться
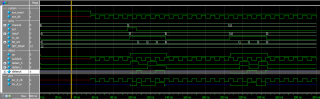
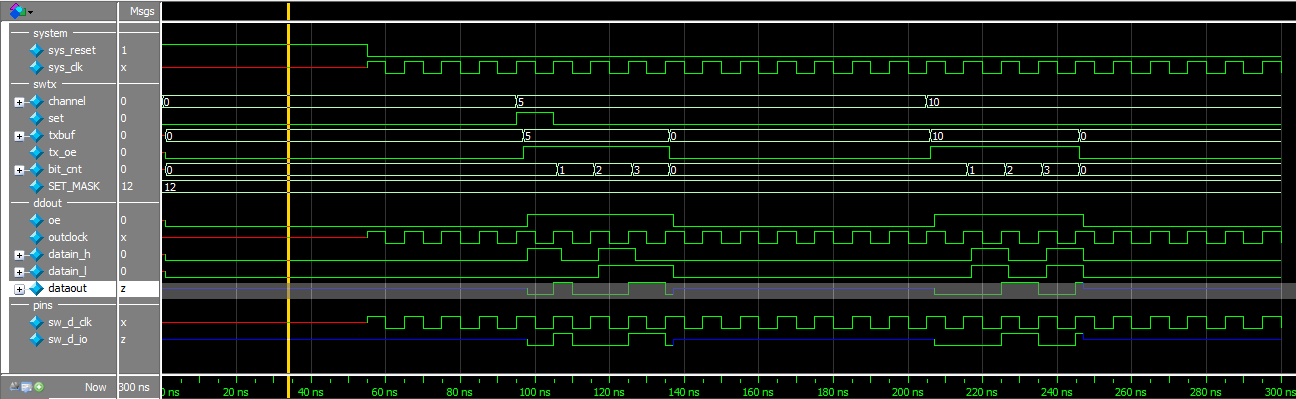
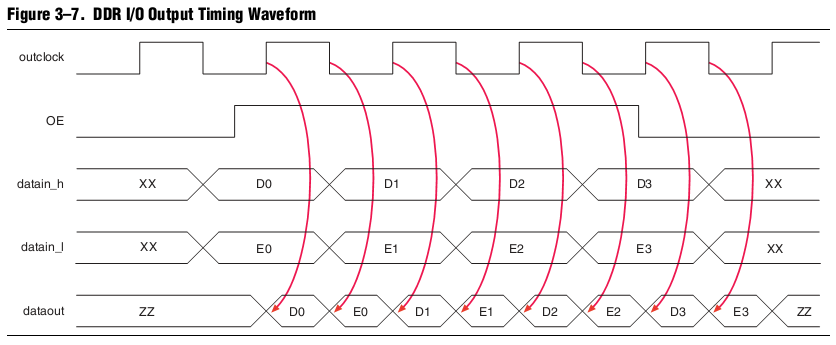
А почему симуляция (функциональная) компонента ALTDDIO в режиме выхода (OUT) не соответствует времянкам из даташита (ug_altddio, страница 22)?
Результат симуляции:
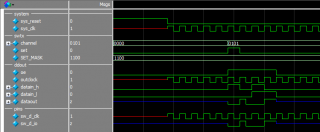
Группы ddout - ноги компонента.
На вход _h компонента побитно выставляются биты шины channel, на вход _l побитно выставляются биты слова SET_MASK (и там и там - начиная с нулевого бита).
Времянка от Альтеры:
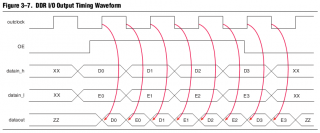
-
Подключите библиотеки, как верно сказал Kuzmi4
vsim -L altera_mf -L lpm -L sgate ... и так далее
-
Опубликовано · Изменено пользователем ilkz · Пожаловаться
Разобрался.
prepare.sh (сначала конвертируем .sof в .flash (образ ПЛИС будет на флэшке лежать начиная с адреса 0x00640000 (см. мап флэшки в гайде на плату, стр.41-42)), потом конвертируем .elf в аналогичный .flash, где уже указываем смещение на cfi_flash и вектор сброса в адресации SOPC-системы):
#!/bin/bash sof2flash --input="../output/board.sof" --output="board_hw.flash" --offset=0x00640000 --pfl --optionbit=0x00018000 --programmingmode=PS elf2flash --base=0x08000000 --end=0x0BFFFFFF reset=0x08020000 --input="../software/board/board.elf" --output="board_sw.flash" --boot=$SOPC_KIT_NIOS2/components/altera_nios2/boot_loader_cfi.srec
program.sh (и программируем сначала ПЛИС, потом Nios):
#!/bin/bash nios2-flash-programmer --base=0x08000000 board_hw.flash nios2-flash-programmer --base=0x08000000 board_sw.flash
-
Опубликовано · Изменено пользователем ilkz · Пожаловаться
На руках имеется девборда с Arria II GX, сделал для нее небольшой проект с ниосом и осью.
Не получается залить проект на флэшку таким образом, чтобы при включении плата грузилась моим проектом и стартовал процессор с осью.
В других семействах как-то проще все было - имелась прошивка-мост к флэшке, через которую заливался сконвертированный заранее pof.
А тут не получается...
Научите как грамотно сконвертировать и зашить, не оставляя при этом на плате никаких заводских образов?
sof2flash вроде бы прошивает, но ПЛИС не загружается - не загорается conf_done, вечно горит error.
UPD: прошу прощения за дублирование темы - форум глючил.
-
Озвучьте вилку з/п, а также название столь секретного НИИ.
-
Опубликовано · Изменено пользователем ilkz · Пожаловаться
ФГУП - он и в Африке ФГУП. Неважно какой.
То что вы предлагаете - от 70 т.р. чистыми. Иначе - студенты.
Далее адресовано всем подобным организациям:
Зарплаты низкие, командировки частые (зависит от конкретного ФГУП), помощи нет (имеется в виду помощь в жилье, кредитах, ипотеках, серьезных премиях).
Можно прийти поработать студентам/начинающим, набраться опыта - самое то. Состоявшиеся специалисты не придут до тех пор, пока не будет конкурентного предложения.
-
Ага. Прощай трансграничная оптимизация - здравствуй лишний объем и снижение Fmax.
Я просто предположил :) Обычно же стыки крупных модулей делают такими, чтобы они (модули) были друг от друга максимально отвязаны (например, это два модуля, работающих в двух разных тактовых доменах). Отсюда и возникла такая мысль.
-
Опубликовано · Изменено пользователем ilkz · Пожаловаться
... и невозможность делать это автоматически.Мне кажется, для определения партиции можно использовать сами модули. Модуль - партиция. Ну либо несколько модулей, вложенных в один (а часто так и бывает) - тоже, по сути, партиция.
Кстати, лично я не особо доверяю инкрементальной компиляции, т.к. она, бывает, глючит - компилятор иногда не может что-то с чем-то свести и все времянки либо логика летят к черту )) Такое уже не раз было. Помогает снос incremental_db.
-
Насколько мне известно, графическая память гораздо быстрее обычной. Соответственно, что мешало бы выгружать в GPU небольшие (относительно) партиции, компилировать их, а уже само "сведение" партиций делать на центральном процессоре ПК? Эдакий "конвеер партиций".
-
Опубликовано · Изменено пользователем ilkz · Пожаловаться
Хао, други!
Осенило тут вопросом - а можно ли использовать для ускорения фиттинговых вычислений CUDA? Честно говоря, не очень понятно почему Альтера (на ее примере, т.к. работаю только с ней) к этому не пришла. Мне кажется, фиттеровские алгоритмы идеально лягут на куду... Или это уже как-то реализовано и я такой непросвященный?
Давайте порассуждаем на эту тему.
Помогу начать.
Вот смотрите. По сути, ПЛИС - это очень большая и сложная сетка (граф, но не Дракула :)). Возьмем некий сферический фиттер в вакууме. По сути, его задача - отобразить синтезированную ранее логику на эту сетку таким образом, чтобы результат удовлетворял заданным ограничениям.
Я не знаю достоверно как работает фиттер - могу лишь сидеть и фантазировать, но думаю что трассировку этой сетки он выполняет не путем тупого перебора всех возможных ее комбинаций, и не пытается уложить в сетку сразу всю логику сразу, а делает все по-частям. И я так понимаю, все нынешние фиттеры делают это последовательно - сначала одну кучку логики, потом другую, потом еще одну и т.д., после чего уже работают на уровне этих разведенных "кучек".
Так вот - что мешает фиттеру укладывать одновременно несколько кучек? На тот же GPU это бы легло очень продуктивно, мне кажется... А там и до сетевого кластерного фиттера недалеко. Правда, сегодня фиттеры до сих пор не могут нормально использовать даже несколько ядер внутри обычного ЦП (лично у меня альтеровский фиттер Processors Usage не поднимал еще ни разу выше 1.2 - и это при наличии 4-х ядер.)
-
Опубликовано · Изменено пользователем ilkz · Пожаловаться
Комплексный в моем понимании - это сигнал вида S = Re + Im или S = COS + SIN. Таким образом, синус - это обычный чирп, а косинус - тот же чирп, но с другой начальной фазой (90 градусов).
У меня же случай непрерывного времени. Как вы посчитаете задержку для непрерывного времени? К тому же, задержка должна варьироваться в зависимости от частоты.
-
Как сделать поворот фазы в аналоговой модели (непрерывное время)?
Хочу сделать комплексный Chirp (т.е., чтобы с него шло две квадратуры - sin и cos). Для этого беру обычный Chirp (он генерит синус), а дальше не понимаю как - Phase/Freq offset, Phase Shift не дают должного результата...
Сделал так:
взял обычный Chirp, скопировал его в новую библиотеку, залез в него (Look Under Mask) и добавил сумматор с начальным значением фазы перед синусом. Работает.
-
примеры о чем говорят - приатачены
Ага, эти материалы я тоже изучил. Позже, когда будет время, соберу подборку найденных материалов и выложу сюда.
-
Опубликовано · Изменено пользователем ilkz · Пожаловаться
Ура наконец-то стало понятно что и как тут происходит :)
Мною же нарисованная диаграмма ответила на мои же вопросы, так что вопросы с 1 по 8 из этого поста снимаются с повестки обсуждения. Также снимаются вопросы из предыдущего поста.
Думаю что приложенная выше диаграмма будет полезной новичкам для понимания методологии анализа и задания в TimeQuest временных ограничений по выходу.
На данный момент есть такой вопрос: если TQ говорит, что на Slow-моделях все хорошо, а на Fast-модели появляются красные слэки, то как сними бороться? Интересует именно системный подход. Правильно ли я понимаю, что для этого нужно смотреть на логику проекта и искать узкие места в ней, или же в ряде случаев можно как-то исхитриться более остроумными констрейнами? Повторюсь, что интересует объективный подход к решению такого рода проблем.
И еще один вопрос к широкому кругу разработчиков: используете ли вы при временном анализе различные температурные и скоростные модели? Задаете ли вы при анализе параметры "внешней среды" для ПЛИС (Board Trace Model-параметры, параметры воздушного окружения и т.п. условия внешней среды)? Насколько оправдана возня с этими тонкостями?
П.С.: предлагаю использовать эту тему как некий справочник-вопросник по TimeQuest (модераторы могут вычистить ее по своему усмотрению).
-
Опубликовано · Изменено пользователем ilkz · Пожаловаться
Итак, продолжаю изучение.
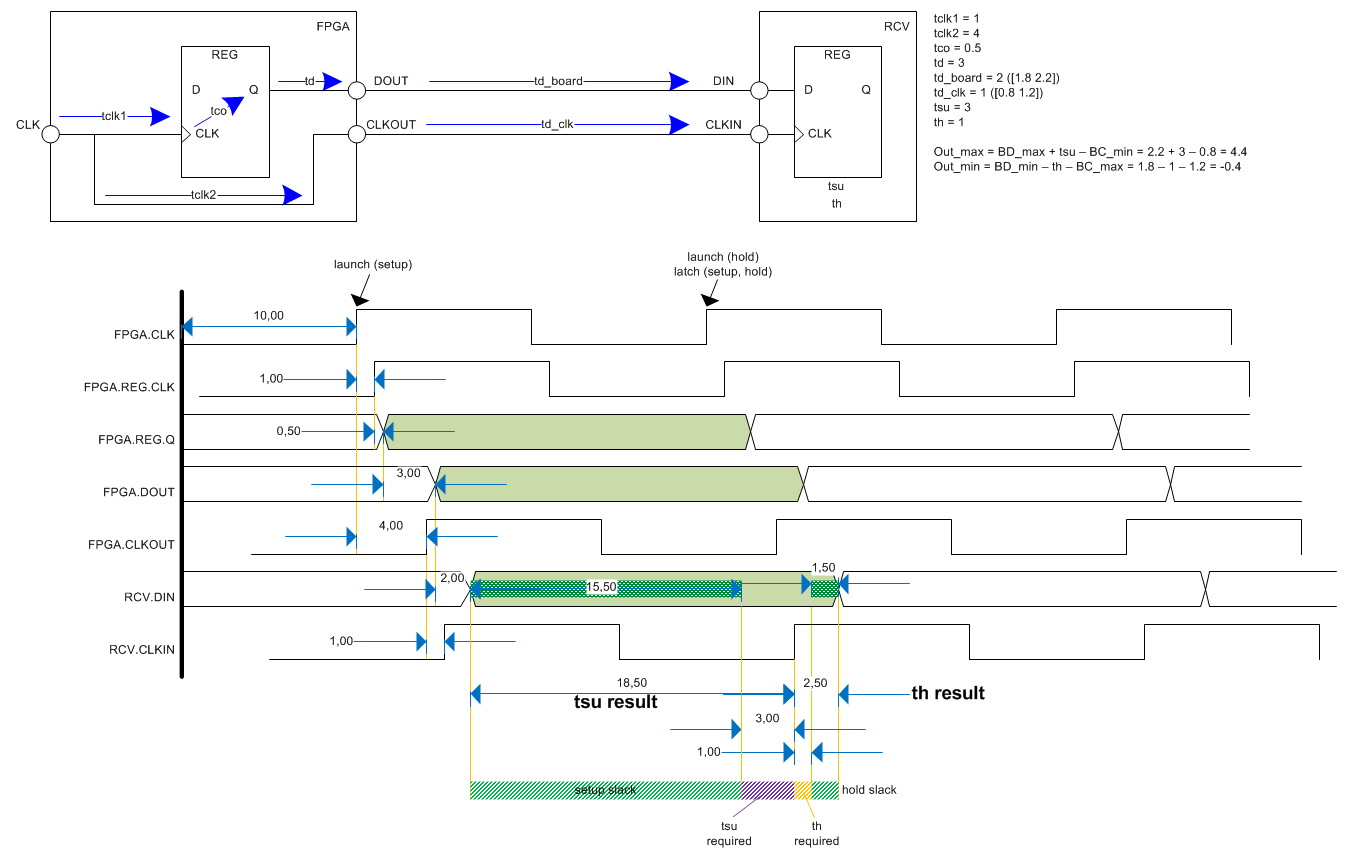
Кропотливо разрисовал для себя все времянки по выходу (все цифры взяты от фонаря). Делюсь ими с народом:
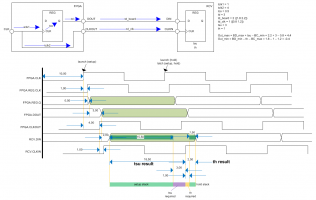
Поправьте меня, если я не прав: TQ проводит анализ по фронтам, обозначенным Launch и Latch (при анализе на сетап и холд).
Вроде как все становится достаточно понятно, однако мне до сих пор осталось непонятным - где именно на этой диаграмме будут сидеть величины, задаваемые set_output_delay max и min соответственно (т.е., для данного примера 4.4 и -0.4 соответственно)?
И еще один момент неясен: если положить что задержек на плате нет, то в выражении set_output_delay останутся только "чистые" значения tsu и th. По идее, в таком случае фиттер должен все разложить так, чтобы на соответствующих обконстрейненных ногах ПЛИС выдерживалась времянка со значениями tsu и th. Однако, этого не происходит и по симулятору задержки на выходах не соответствуют заданным tsu и th... Почему так?
-
Опубликовано · Изменено пользователем ilkz · Пожаловаться
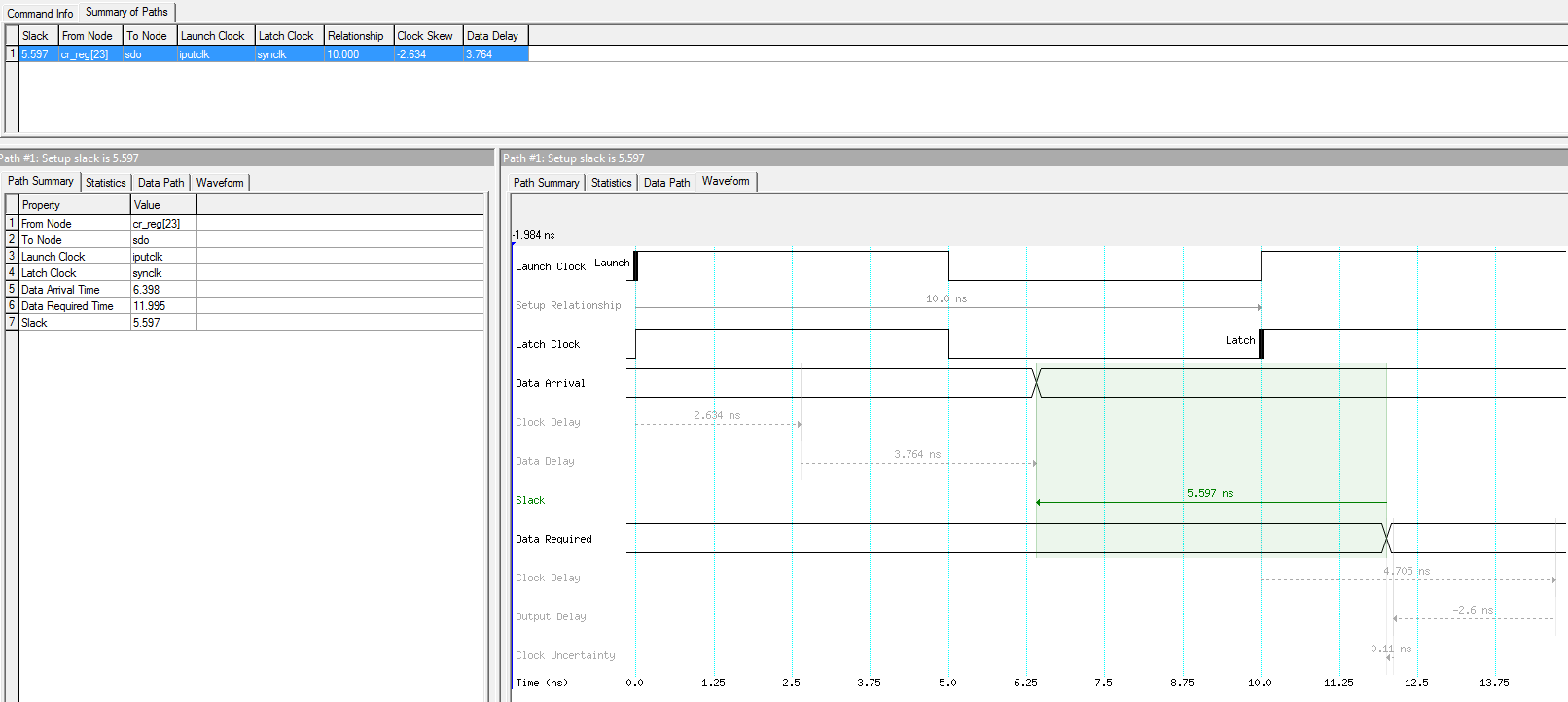
Я вообще перестаю понимать весь этот ужас....
Решил упростить задачу, повысив тактовую до 100 МГц (чтобы не возиться с хитрой логикой, мультициклами и т.п.).
Вот такой SDC:
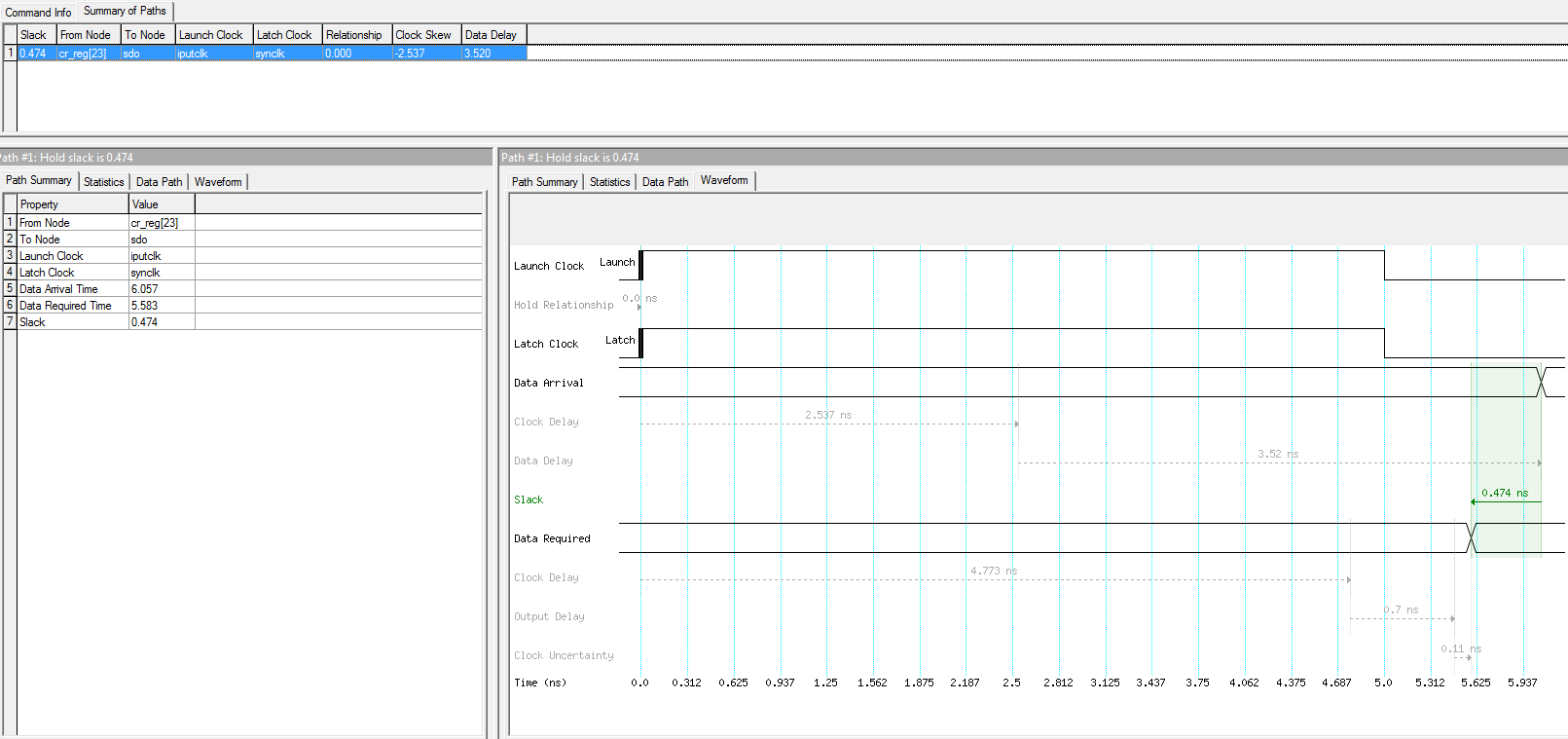
# board set board_data_min 1.5 set board_data_max 2 set board_clk_min 1.4 set board_clk_max 1.7 set tsu 2 set th 0.5 derive_clock_uncertainty create_clock -period 10 -name {iputclk} -add [get_ports {iclk}] create_generated_clock -name {synclk} -source [get_ports {iclk}] [get_ports {sclk}] set_output_delay -max [expr $board_data_max + $tsu - $board_clk_min] -clock [get_clocks {synclk}] [get_ports {sdo}] set_output_delay -min [expr $board_data_min - $th - $board_clk_max] -clock [get_clocks {synclk}] [get_ports {sdo}]Вот что рисует TQ:
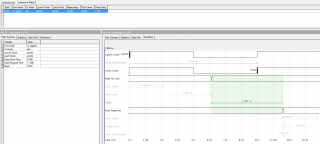
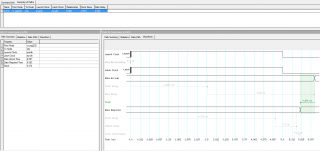
Объясните, пожалуйста, почему:
1. Latch Clock на диаграммах отображается по-разному (где-то он - следующий клок, а где-то равен Launch clock'у - это что, разный клок или отсчет идет от разных его моментов)?
2. Clock Delay (вторая его линия, которая под data required) на двух диаграммах имеет разное значение? Это что - разный клок? Это же один клок, идущий на один пин по одной линии. Он должен иметь одинаковое значение. А на диаграммах они разные (4.705ns и 4.773ns).
3. На диаграмме сетапа output_maximum_delay отложена в минус? (-2.6ns)
4. На диаграмме холда output_minimum_delay отложена в плюс? (0.7ns)
5. Как вообще ПРАВИЛЬНО читать эти диаграммы? От доков, картинок и диаграмм уже в глазах рябит, но чем больше пытаюсь вникнуть - тем более все становится непонятным...........
6. Я верно понял основной принцип вычисления out_max и out_min delay'ев - они должны быть такими, чтобы с учетом задержки на длинах линий на пинах таргет-чипа была ЕГО времянка по Tsu и Th?
7. Для чего задавать задержки (например, board-задержки) двумя значениями, ведь дорожки имеют фиксированную длину и не меняются в процессе работы? %)
8. Правильно ли я понимаю, что out_max_delay, по сути, дает время сетапа на таргет-чипе, а out_min_delay - время холда?
Я хочу докопаться до самого конца и все это понять, но блин информации столько, что писец просто - мозг рвет (а все выше заданные вопросы как-то обходятся стороной в литературе). %)
Думаю, эти вопросы будут полезными и новичкам.
-
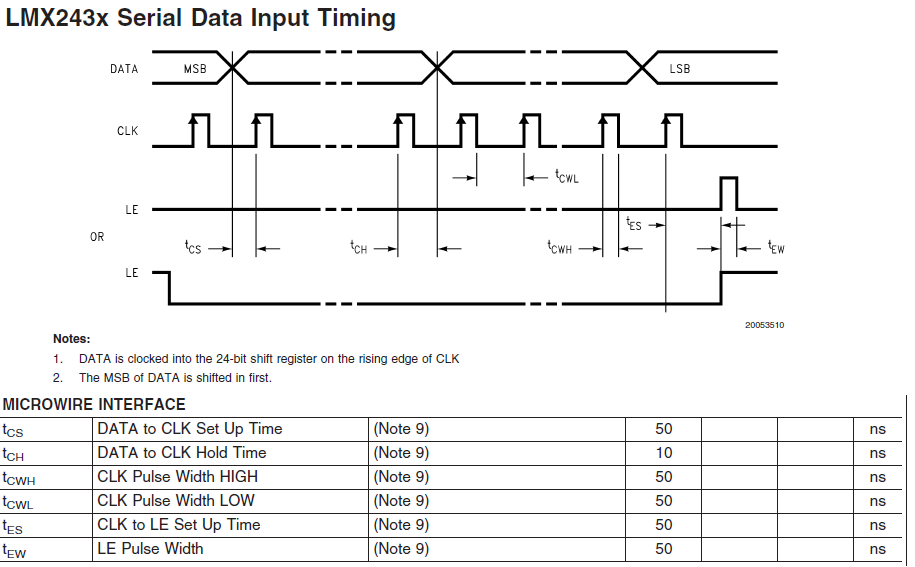
не совсем, tsu у вас по даташиту 50нс, а не 90 sm.gif но это не так важно.
Цифру 90нс я получил исходя их того, что 10нс (минимум) отдано на холд, 50нс - на сетап, но т.к. кроме холда и сетапа более ничего нет, то эти 50нс можно спокойно растянуть до 90нс.
ЗЫ. Проще поднять тактовую в ПЛИС в 2 раза и сделать все на этом клоке, разместив в IO буферах триггеры sm.gifПопробуем потом :)
На рисунке, действительно, инвертированный относительно SDC клок.Не понял - на рисунке из даташита клок нарисован инверсно? Т.е., в реале он будет инвертирован? Тогда вообще ничего не понятно, ведь передний фронт будет попадать на фронт смены данных...
Выкладываю полностью проект.
SDC написан как рекомендовали, выходной регистр сидит в Fast-Output.
В принципе, должно работать, т.к. фронт такта сидит в центре данных, что удовлетворяет требованиям.
Однако, таймквест по-прежнему ругается (теперь уже на сетап). Ну не должно же так быть :)
-
Опубликовано · Изменено пользователем ilkz · Пожаловаться
В данный момент под рукой нет квартуса, поэтому прикладываю исходник и информацию об интерфейсе из даташита.
Если все переписать по цифрам из даташита, то у меня получилась картинка из первого поста (вопрос к des00: а что, собственного, странного в этом интерфейсе?).
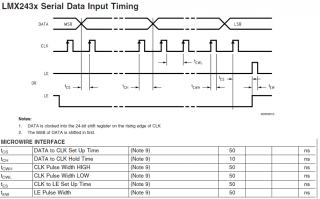
`include "timescale.v" module iface ( input iclk, input reset, input [23:0] cr, input load_cr, output reg load_done, output odata, output oclk, output oen ); reg [23:0] cr_reg; reg enable; reg [4:0] bit_cnt; always @(posedge iclk, posedge reset) begin if(reset) begin cr_reg <= 0; load_done <= 0; enable <= 0; bit_cnt <= 23; end else begin if(load_cr) begin cr_reg <= cr; enable <= 1; end if(enable) begin if(bit_cnt == 0) load_done <= 1; else bit_cnt <= bit_cnt - 1; end else load_done <= 0; if(load_done) enable <= 0; if(enable) cr_reg <= {cr_reg[22:0], 1'b0}; end end assign oclk = enable & ~iclk; assign odata = cr_reg[23]; endmoduleSDC-файл - из первого поста, чип - EP3C16.
-
Начинаю паниковать, потому что ни черта не понятно. Читаю "TQ для чайников", сопутствующие альтеровские доки. Вроде в их примерах все примерно ясно, но как доходит дело до моего кода - то полный тупик. Научите, пожалуйста, как правильно написать констрейны на простенький интерфейс.
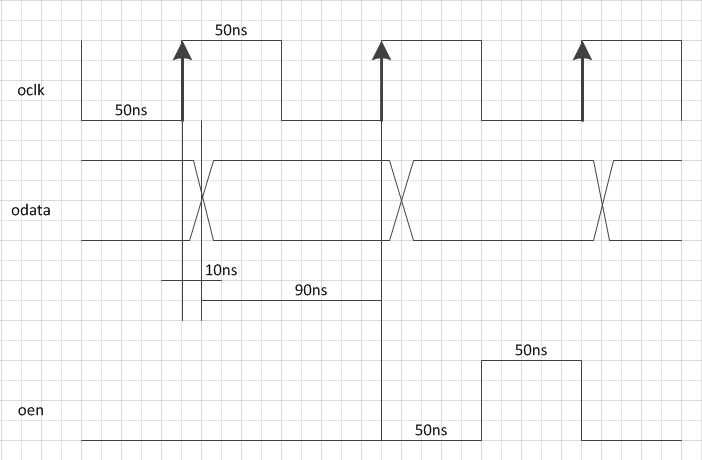
Итак, есть такой интерфейс вот с такой времянкой:
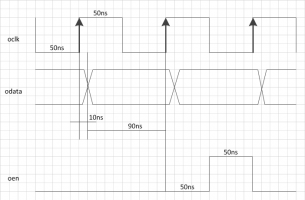
А вот как я его описываю в sdc:
# iclk - это входной пин ПЛИС, на который приходит клок для этого интерфейса set_time_format -unit ns -decimal_places 3 derive_clock_uncertainty create_clock -period 10MHz -name {iclk} [get_ports {iclk}] create_generated_clock -name {oclk} -source [get_ports {iclk}] [get_ports {oclk}] set_output_delay -clock [get_clocks {oclk}] -max 90 [get_ports {odata}] set_output_delay -clock [get_clocks {oclk}] -min -10 [get_ports {odata}]В ответ на это TQ кажет мне отрицательный слэк по холду аж в -8.587нс. Как, блин, это все правильно описать?
Пин oen пока не трогал.
-
Опубликовано · Изменено пользователем des00
использование нецензурных выражений (с) модератор · ПожаловатьсяЗдравствуйте!
Первый вопрос:
Ну вот, например, есть тестбенч, в котором много очень длинных одинаковых иерархических путей (кусочек кода):
if(dut.controller.generated_channel[n].Channel.data_fifo.wrreq) $display("%10t [EVENT] [%0d] received packet# %0d (A=%0h, B=%0h, C=%0d)", $time, n, dut.controller.generated_channel[n].Channel.data_fifo.data[32 +: 8], dut.controller.generated_channel[n].Channel.data_fifo.data[0 +: 16], dut.controller.generated_channel[n].Channel.data_fifo.data[16 +: 16], dut.controller.generated_channel[n].Channel.data_fifo.data[40 +: 20] );Так вот, хотелось бы написать какой-нибудь алиас, чтобы потом не копипастить этот ужас из множества одинаковых путей и имен:
alias fifo = dut.controller.generated_channel[n].Channel.data_fifo; if(fifo.wrreq) $display("%10t [EVENT] [%0d] received packet# %0d (A=%0h, B=%0h, C=%0d)", $time, n, fifo.data[32 +: 8], fifo.data[0 +: 16], fifo.data[16 +: 16], fifo.data[40 +: 20] );Возможно подобное в вериложике?
Второй вопрос:
Есть имплементация модуля мультиплексора каналов:
ChannelMux ChannelMux ( .clk (ip_clk), .reset (reset), .can_read_channel (can_read_channel_fifo), .ch0 (channel_out[0]), .ch1 (channel_out[1]), .ch2 (channel_out[2]), .ch3 (channel_out[3]), .ch4 (channel_out[4]), .ch5 (channel_out[5]), .ch6 (channel_out[6]), .ch7 (channel_out[7]), .ch_rdreq (ch_rdreq), .rd_fifo ({rd_rcv_fifo_request,rd_rcv_fifo_request_reg}==2'b10), .can_read (can_read_common_fifo), .out (nios_pkt), .fifo_usedw (fifo_usedw), .fifo_wrfull (fifo_full), .fifo_wrempty (fifo_empty) );Выше этого модуля используется большой generate-блок, которым я генерю необходимое мне количество инстансов каналов. Хотелось бы сделать как-нибудь так, чтобы количество входов мультиплексора ChannelMux.chN соответствовало количеству используемых канальных модулей. То есть, если я использую 3 канала вместо 8-ми, то хотелось бы, чтобы на этапе компиляции делалось так:
ChannelMux ChannelMux ( .clk (ip_clk), .reset (reset), .can_read_channel (can_read_channel_fifo), .ch0 (channel_out[0]), .ch1 (channel_out[1]), .ch2 (channel_out[2]), .ch_rdreq (ch_rdreq), .rd_fifo ({rd_rcv_fifo_request,rd_rcv_fifo_request_reg}==2'b10), .can_read (can_read_common_fifo), .out (nios_pkt), .fifo_usedw (fifo_usedw), .fifo_wrfull (fifo_full), .fifo_wrempty (fifo_empty) );Возможно такое? Может быть как-то пошаманить с толстой шиной, на которую будут мапиться каналы (а ширина шины будет как-то соответственно меняться)?
Спасибо!
П.С.: не System-Verilog. Его пока не знаю ))
-
Ruslan, большое спасибо за подробный ответ! То, что нужно. Википедию и ссылки с нее читал.
В ТЗ требования к CRC никак не прописаны, более того, протоколы также никак не определены, так что тут я волен делать что душе угодно. Есть только скорость передачи данных по каналу.
Насчет вырожденных пакетов - передаются значения с АЦП, так что там может сидеть что угодно - как все нули, так все и единицы, поэтому в моем случае это, думаю, неактуально...

Двухпортовая DDR2-память
в Работаем с ПЛИС, области применения, выбор
Опубликовано · Пожаловаться
Добрый день.
Не то чтобы требуется - скорее для собственного интереса:
1. Есть генератор данных, который складывает их в большое фифо.
2. К фифо с другой стороны подключена NIOS-система, которая, когда ей надо, это фифо читает и дальше отсылает данные в сеть.
3. Видится вероятная в будущем проблема: если поток генерируемых данных сильно увеличится, а NIOS будет по каким-то причинам долго занят, то фифо может переполняться и, следовательно, будут потери данных, что не очень-то приемлемо.
4. В NIOS задействована DDR2-память (CIII dev kit), которая сейчас как-то используется (в основном для предварительной буферизации прочитанных из фифо данных перед отправкой в сеть).
5. А теперь вопрос: возможно ли построить архитектуру таким образом, чтобы из DDR2-памяти получилась двухпортовая память? При этом хотелось бы, чтобы генератор мог писать в этот DDR2-буфер напрямую, а NIOS мог этот буфер когда ему надо читать (возможно, одновременно с записью).
Как я это вижу сейчас:
1. DDR2-ядро выводится за пределы QSys-системы.
2. Для Qsys-системы пишется прокладка-интерфейс к арбитру.
3. Пишется прокладка для генератора к арбитру.
4. Пишется арбитр, который будет как-то разруливать совместный доступ - кто когда пишет и читает в DDR2-память (используя маленькие буферочки на случаи коллизий).
5. В совсем отдаленном будущем хотелось бы вообще избавиться от NIOS и софта, оставив только хардварную цепочку [генератор]--[DDR2-буфер]--[сеть (UDP)].
То есть конечная цель - сделать двухпортовый DDR2-буфер.
Насколько будет адекватной такая архитектура? Или я упоролся в своих фантазиях? :)