Beby
-
Постов
659 -
Зарегистрирован
-
Посещение
-
Победитель дней
1
Весь контент Beby
-
Синхронизатор
Beby ответил AlphaMil тема в Работаем с ПЛИС, области применения, выбор
Это хорошо, что от одного генератора. Теперь остаётся уточнить, как Вы получали эти частоты: при помощи DLL ? Хорошо бы схемку (ну или HDL описание) глянуть этого места. Если всё сделать правильно, то и метастабильности не будет - а значит, всё будет тривиально (как функционально моделируется - так и работает,.. если, конечно all constraints are met). Т.к. схематика/описания схемы генерирующей clock 100М и 50М от автора не последовало, то предположу, что он сделал это место "правильно". Тогда для пересаживания импульса, длинной от 1 до 2 периодов CLK_100M на частоту 50М (получится импульс длинной в один период), достаточно такой схемы: ISE разведёт сигнал A с ограничениями как для 100М, и обратная связь (цепь Event_50M) со второго триггера на первый тоже будет разведена с ограничением как для 100М. Цепь Event_50M ко всем остальным синхронным элементам домена Clk_50M будет разведена с ограничениями как для 50М. Ну вот, как-то так примитивно всё получается,.. если схема генерирующая clock’и сделана правильно.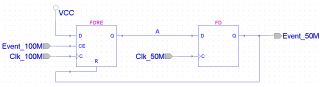
-
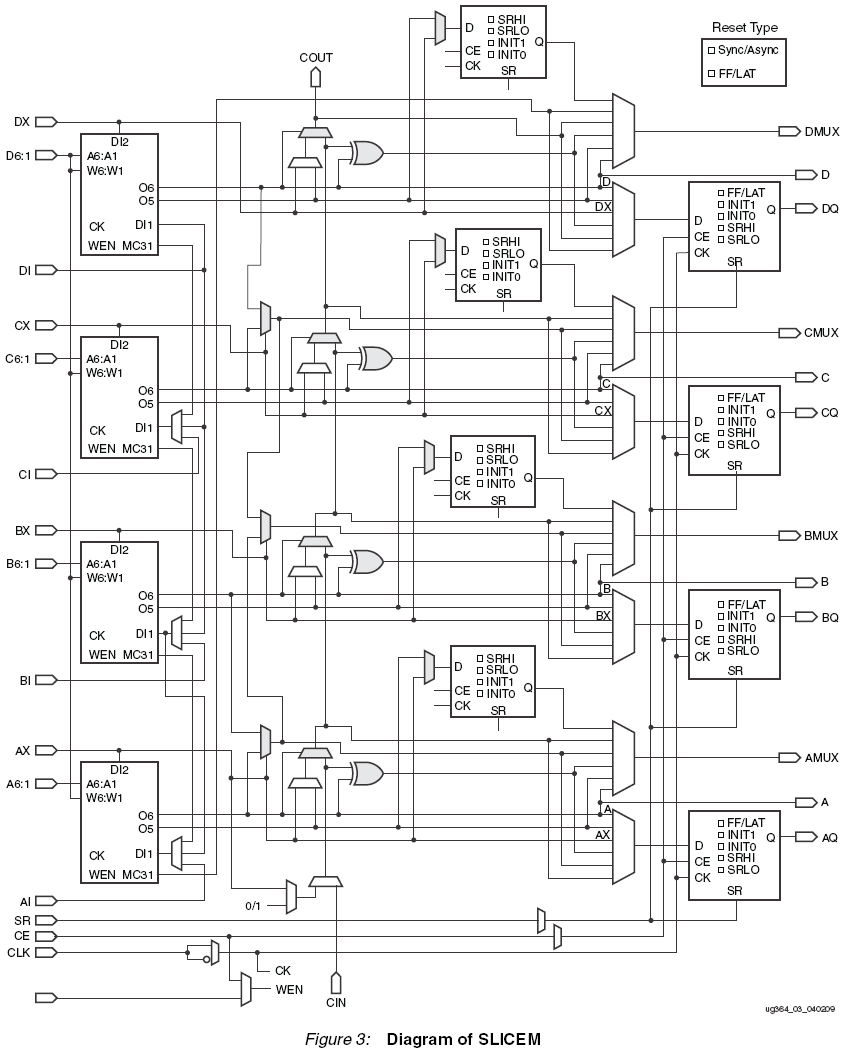
Может для первой задачи Вам больше подойдёт Spartan-6 - если хватит ёмкости, то оно должно выйти заметно дешевле, что Virtex-2/5/6, да и Spartan-6 должен быть более шустрым, чем Virtex-2. Для второй задачки может оказаться интересным Virtex-5/6SX - у них значительно больше RAM (и block, и dsitributed) и DSP на LUT+FF, чем у аналогичных Virtex-5/6LX. Картинка приведена неправильная. Xilinx Slice состоит из много чего – там не только LUT. V6(x7) Slice’ы бывают 2 видов: SliceM и SliceL. SliceL – это SliceM в котором используются удешевлённые LUT6 (без возможности работы в режимах Shift Register и Distributed RAM). В S6 встречается еще более удешевлённый Slice – SliceX (от которого в x7 благоразумно отказались) - это SliceL без цепочек быстрого переноса. Но, при любом раскладе, для понимания структуры V6 Slice надо рассматривать целиком, а не какой-то огрызок показывать: Вот тут уже видно, что LUT6 – это более хитрая штука, чем то, что изображено на альтеровском рисунке. У всех SliceM LUT6 есть еще по 4 входа, которые «забыли» альтеровцы (2 DataIn, WE, WCLK) , а у нижних трёх LUT еще +6 входов (адрес записи данных, используемый в режиме Dual Port RAM) – итого от 10 до 16 входов на один SliceM LUT6 ! А Вы нам про какую-то «многофункциональность» говорите. Да, эти режимы не часто используются (поэтому и появились удешевлённые SliceL) – но как без этих режимов становится тоскливо ! Также надо иметь в виду, что у каждой V6 LE (LUT6+2FF) - по 3 выхода, которые можно использовать одновременно.
-
Просмотр результатов синтеза
Beby ответил klop тема в Среды разработки - обсуждаем САПРы
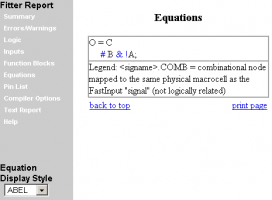
Отвечать удобней в обратном порядке, хе-хе. 3. В Xilinx ISE: Fitter - только у CPLD, у FPGA - MAP / P&R. 2. Нижеприведённый пример добытый в ISE 10.1.03, из кода library IEEE; use IEEE.Std_Logic_1164.all; Library UNISIM; use UNISIM.vcomponents.all; entity CLK is port ( A: in std_logic; B: in std_logic; C: in std_logic; O: out std_logic ); end entity; architecture Arc of CLK is begin O <= (not(a) and B) or C; end architecture; 1. Запустаем Fitter Report и бредём в раздел equation, а далее выбираем вид: Abel, VHDL или Verilog. .. Ну вот Вы его и увидели в отчёте fitter'а... а дальше-то что ??