


repstosw
-
Постов
2 650 -
Зарегистрирован
-
Победитель дней
2
Сообщения, опубликованные repstosw
-
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
Ещё один недостаток IAR.
При портировании библиотек libjpeg и libspeexdsp и сборки общего проекта, линковщик выдаёт ошибку: не определены функции:
__close, remove, __lseek, __read, __open
Хотя я нигде их не использую. И вызываю библиотечные функции (из libjpeg, libspeexdsp), которые не работают с файловым вводом-выводом.
Тем не менее, линковщик считает, что они нужны. Почему ?
Как в IAR включить вырезание всех неиспользуемых функций? В GCC это делается легко.
Пробовал включать семихостинги всякие(в Ире), в итоге, программа заваливалась в Abort.
Всё кончилось тем, что я написал свою затычку для IAR:
//File I/O gag int __open(const char *filename,int access,unsigned mode) { return -1; } int __close(int fd) { return -1; } int __read(int fd,void *buf,unsigned count) { return -1; } long __lseek(int handle,long offset,int origin) { return -1; } int remove(const char *fname) { return -1; }И программа перестала валиться в Abort.
В GCC не нужно писать никаких заглушек.
И всё-же, как более элегантнее и правильнее разрулить эту ситуацию?
-
1 hour ago, mantech said:
А там галочка Use VFP\NEON была включена?
Обязательно
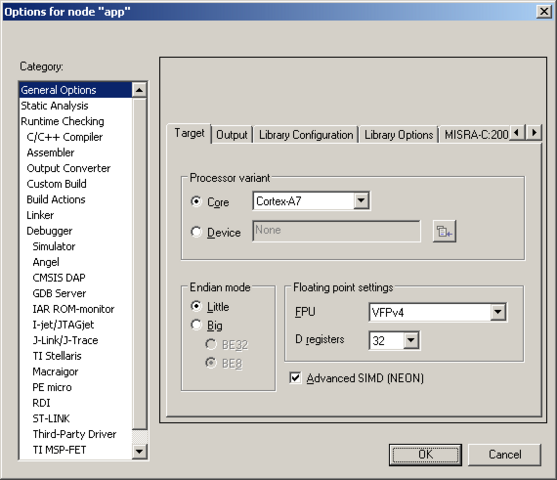
-
Уменьшил размерность элементов массивов вдвое (был int, стал short). Скорости возросли (T113-s3)
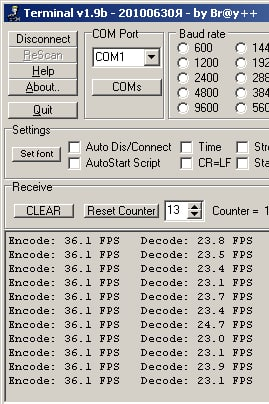
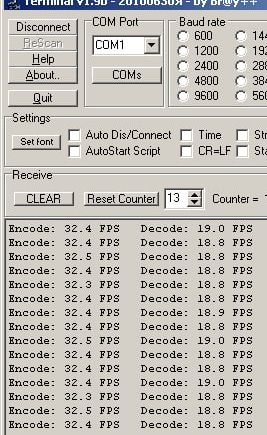
А вот в IAR результат хуже (любая из оптимизаций - Balanced, Speed, Size):
Обновлённый бенч-марк: rs2.zip
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
14 hours ago, jcxz said:для IAR частенько "balanced" оптимизация генерит более быстрый код, чем "speed". А иногда идаже и "size" оптимизация даёт более быстрый код.
Так как компилятор, выполняя оптимизацию, не учитывает размеров кеша.
Я проверил эти утверждения.
Увы, после установки Balanced или Size скорость выполнения программы стала ещё меньше.
Обновлённый бенчмарк: rs2.zip
Слева - GCC 11, справа - IAR 7.60 (процессор allwinner T113-s3 На штатной частоте):
-
29 minutes ago, x893 said:
Какие настройки оптимизации ?
IAR:
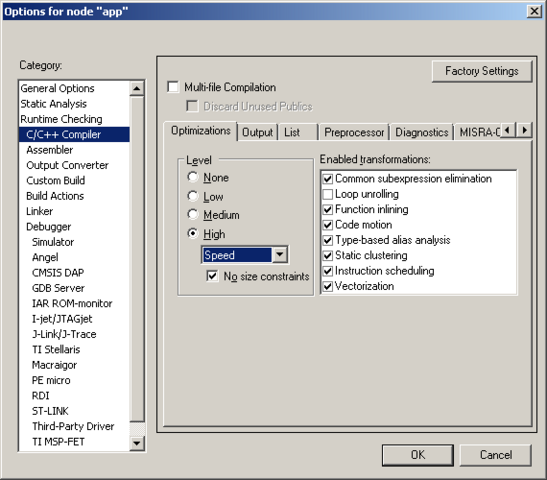
GCC:
-Ofast -mfloat-abi=hard -mfpu=vfpv4 -mfpu=neon -fomit-frame-pointer -ftree-vectorize -fno-math-errno
-
8 minutes ago, mantech said:
Ну дак там и сама процессорная логика намного больше инструкций за такт выполняет, и шины быстрее, неговоря уже о частоте ЦП в 3 раза выше...
на ПК последний вариант кода тоже дал прирост скорости 🙂
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
1 hour ago, mantech said:Вполне возможно, компилятор на ПК оптимизирует под SSE инструкции, в АРМе вполне такого нет... Нужно пробовать без оптимизации и там и там..
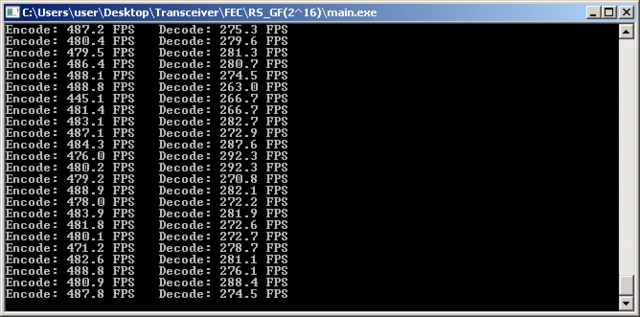
Удалось оптимизировать ещё сильнее - FPS на декодирование вырос почти в 2 раза.

На ПК кэш несколько МБ. Массивы полностью туда ложатся и никакой подгрузки нет. В этом плане всякие мелкоконтроллеры уделываются x86/x64.
GenaSPB испытал код на A53 (allwinner A64) - результат лучше в 1,5 раза при той же частоте.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
1 hour ago, razrab83 said:IAR 8.5, stm32f*, пишу код в *.с файле
IAR - это грёбаный трэш.
Столкнулся с тем, что оптимизация в IAR - ***. В GCC результат лучше.
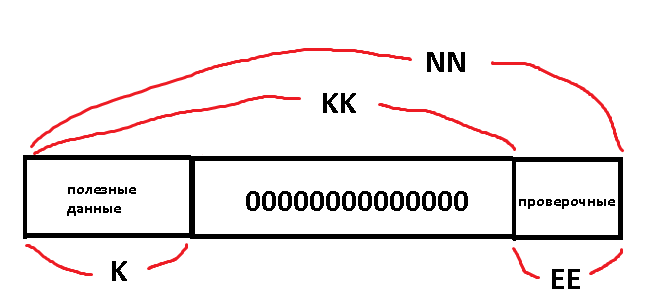
Результаты замера ниже - кодек Рида-Соломона : на 4096 слов + 256 проверочные. Слева - IAR, справа - GCC.
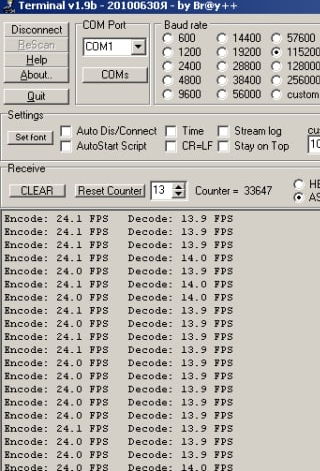
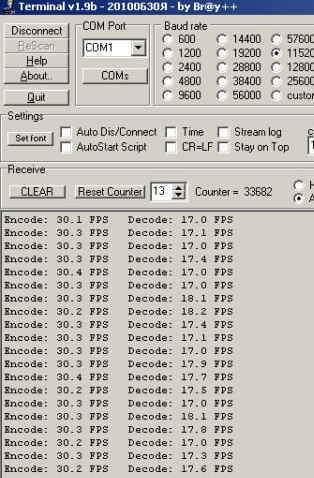
Воркбенч - погонять: rs.zip
-
Кто-нибудь сталкивался с проблемой кэш-флуда (cache flood) на T113-s3 или других ядрах?
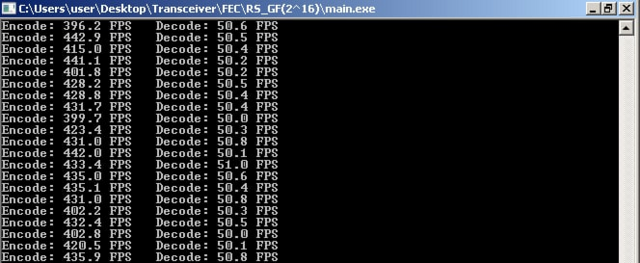
Есть кодер и декодер Рида-Соломона в пространстве GF(2^16). Усечённый и оптимизированный. Полезная нагрузка - данные 4096 слов. Проверочные данные - 256 слов.
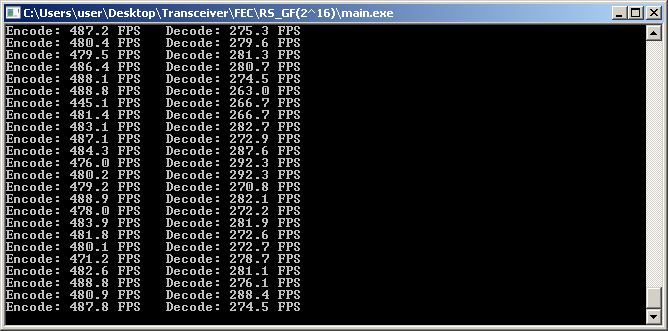
На ПК с частотой ядра 3 ГГц (архитектура x64) кодирование идёт на 300+ FPS, декодирование до 50 FPS.
Запускаю на T113-s3, и вижу: 30 FPS кодирование и всего 8 FPS декодирование.
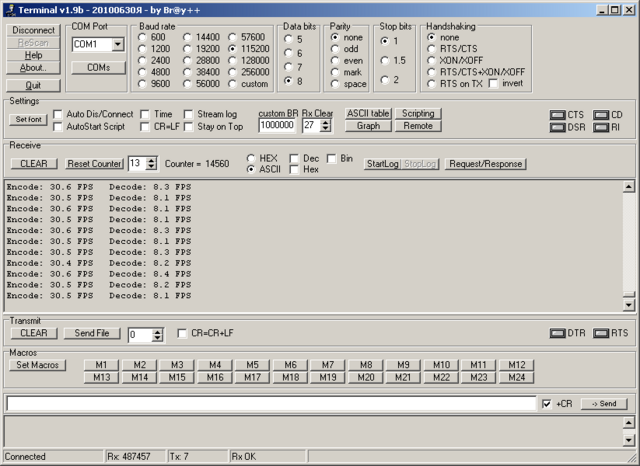
Код прилагаю: rs.zip
Связано ли такое замедление с тем, что массивы не попадают целиком в кэш данных и происходит загрязнение кэша хаотичными выборками?
В алгоритме два вложенных цикла - один на 4096 длругой на 256 итераций, во внутренних циклах идет обращение к элементам массива, номер которого - есть другой элемент массива.
Вложенная индексация до 2 - 3.
Плюс остаток от деления на 65535 (не путать с 65536 !)
Каковы шансы ускорить декодирование?
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
1 hour ago, repstosw said:Пробовал выкинуть этот цикл (декодирование при этом неверное) - скорость повышается до 50 FPS.
Оптимизировал эту гадость до такого уровня:
for (j = deg_lambda; j > 0; j--) if (reg[j] != A0) { reg[j]+=j*(KK-K); reg[j]=modnn2(reg[j]); }Внешний цикл для нулей (с переменной i) ушёл.
Теперь скорость около 50 FPS.
Корень зла в частых вызовах функции modnn. Теперь она вызывается в KK-K раз меньше, когда нулевые элементы.
В целом код Ченя выглядит так:
/* * Find roots of the error+erasure locator polynomial. By Chien * Search */ COPY(®[1],&lambda[1],NN-KK); count = 0; /* Number of roots of lambda(x) */ for (i = NN-1; i >= KK; i--) //Parity { q = 1; for (j = deg_lambda; j > 0; j--) if (reg[j] != A0) { reg[j]=modnn(reg[j]+j); //modnn q ^= Alpha_to[reg[j]] ; } if (!q) { /* store root (index-form) and error location number */ root[count] =NN-i; loc[count] = i; //позиции ошибочных байт count++; } } for (j = deg_lambda; j > 0; j--) //Zero data if (reg[j] != A0) { reg[j]+=j*(KK-K); reg[j]=modnn2(reg[j]); } for (i = K-1; i >= 0 ; i--) //Data { q = 1; for (j = deg_lambda; j > 0; j--) if (reg[j] != A0) { reg[j]=modnn(reg[j]+j); //modnn q ^= Alpha_to[reg[j]] ; } if (!q) { /* store root (index-form) and error location number */ root[count] =NN-i; loc[count] = i; //позиции ошибочных байт count++; } } -
5 hours ago, des00 said:
Речь не про то как мы делим, речь про представление данных в той реализации алгоритма кодирования что вы нашли. Разные авторы представляют данные по разному, кто-то делает хвост-голова, кто-то голова-хвост. Но в теории кодирования коды усекаются с головы(первых символов что кладутся в канал).
ЗЫ. Строки 359-399 показывают как пропустить часть Ченя, при усеченных кодах, для полинома локаторов и полинома значений ошибок. Но, нужно помнить, что при усечении еще может потребоваться коррекция начального значения коэффициента масштабирования ошибки. Это можно посмотреть в строках 405-427. Зависит она от первого корня генераторного полинома, расстояния между корнями и от реализации алгоритма берлекампа. Но вам проще. Надо при отладке записать те константы что будут, а потом просто начать алгоритм с нужного шага.
Мне тяжело понять ваш код и сопоставить его со своим, чтобы выработать действия к коррективам.
Я записывал массив reg[ ] для случая нулевых байт каждый кадр, и несмотря на то что нули, значения reg[ ] всегда разные.
Пока получилось разбить на 3 цикла, цикл в середине - как раз соотносится к нулевым байтам. Получилось 35 FPS.
Пробовал выкинуть этот цикл (декодирование при этом неверное) - скорость повышается до 50 FPS.
/* Convert lambda to index form and compute deg(lambda(x)) */ deg_lambda = 0; for(i=0; i<NN-KK+1; i++) { lambda[i] = Index_of[lambda[i]]; if(lambda[i] != A0) deg_lambda = i; } /* * Find roots of the error+erasure locator polynomial. By Chien * Search */ COPY(®[1],&lambda[1],NN-KK); count = 0; /* Number of roots of lambda(x) */ for (i = NN-1; i >= KK; i--) //Parity { q = 1; for (j = deg_lambda; j > 0; j--) if (reg[j] != A0) { reg[j]=modnn(reg[j]+j); //modnn q ^= Alpha_to[reg[j]] ; } if (!q) { /* store root (index-form) and error location number */ root[count] =NN-i; loc[count] = i; //позиции ошибочных байт count++; } } for (i = KK-1; i >= K ; i--) //Zero { for (j = deg_lambda; j > 0; j--) if (reg[j] != A0) { reg[j]=modnn2(reg[j]+j); //modnn } } for (i = K-1; i >= 0 ; i--) //Data { q = 1; for (j = deg_lambda; j > 0; j--) if (reg[j] != A0) { reg[j]=modnn(reg[j]+j); //modnn q ^= Alpha_to[reg[j]] ; } if (!q) { /* store root (index-form) and error location number */ root[count] =NN-i; loc[count] = i; //позиции ошибочных байт count++; } } printf("\n Final error positions:\t"); for (i = 0; i < count; i++) printf("%d ", loc[i]); printf("\n"); if (deg_lambda != count) { /* * deg(lambda) unequal to number of roots => uncorrectable * error detected */ return -1; }
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
13 hours ago, des00 said:В отбрасываемых, при передаче нулевых символов, априори ошибок быть не может поэтому и считать их не нужно. Можно пропустить их рассчет, но нужно учесть значение локатора корня, которое должно быть на шаге, перед актуальным словом данных. Это значение фиксированно для конкретного RS кода (длина кода, количество проверочных символов, количество отбрасываемых символов).
Не удаётся полностью избежать вычислений в алгоритме Ченя для нулей. Алгоритм требует переменных с предыдущего состояния.
Массив reg[ ] в коде. Не удаётся разлепить. Пока найдены условия, при которых ошибка не генерируется (нули) - переменная q:
//if(((NN-i)>K-1)&&((NN-i)<KK)) //[0..K-1] ... [KK..NN-1] /* * Find roots of the error+erasure locator polynomial. By Chien * Search */ COPY(®[1],&lambda[1],NN-KK); count = 0; /* Number of roots of lambda(x) */ for (i = 1; i <= NN ; i++) { if(((NN-i)>K-1)&&((NN-i)<KK)) //[0..K-1] ... [KK..NN-1] { for (j = deg_lambda; j > 0; j--) if (reg[j] != A0) { reg[j]=reg[j]+j; if(reg[j]>=65535)reg[j]-=65535; //modnn } } else { q = 1; for (j = deg_lambda; j > 0; j--) if (reg[j] != A0) { reg[j]=reg[j]+j; if(reg[j]>=65535)reg[j]-=65535; //modnn q ^= Alpha_to[reg[j]] ; } if (!q) { /* store root (index-form) and error location number */ root[count] = i; loc[count] = NN - i; //позиции ошибочных байт count++; } } }
14 hours ago, des00 said:Это фича конкретно той реализации которую вы нашли, видимо вот так авторам было удобно)
Это не зависит от реализации. Деление идёт со старших разрядов полинома и завершается делением младших, пока не получится остаток от деления. Поэтому для правильного кодирования старшие разряды должны быть нулевыми.
Никто не начинает деление с младших разрядов делимого. И вроде это даже невозможно
-
59 minutes ago, des00 said:
Можно еще процедуру чены сделать быстрее, но надо будет заранее вычислить несколько констант.
Какие?
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
1 hour ago, des00 said:Ну так сделайте, я же написал как. у вас пределы цикла стоят не правильно, потому и не работает.
Повторюсь: кодирование RS это деление на полином. Деление нуля (то самое заполнение нулями что вы делаете), не меняет результат. Если нули стоят в начале кодового слова, то можно их просто пропустить, подав сразу данные (начальное состояние частного должно быть одинаковое во всех случаях). На этом и основано укорочение кодов.
Были перепутаны хвост и грива у полинома который делится (исходные данные).
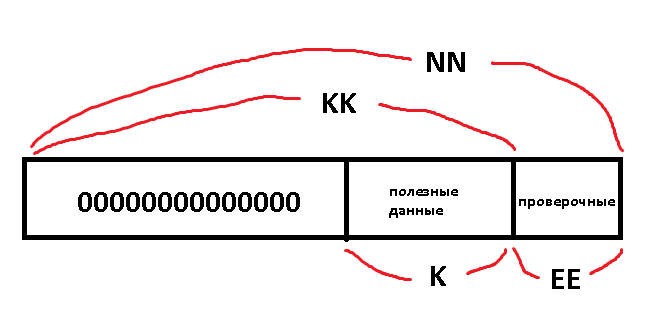
Теперь кодирование работает на 400+ FPS, при этом проверочные символы те же самые, что и без укорочения (что верно).
Чтобы кодирование с укорочением работало, нужно полезные данные ставить слева, а не перед проверочными:
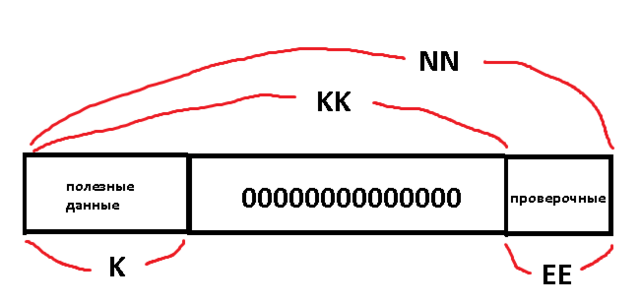
Зато теперь с укороченным декодированием проблема - цикл в алгоритме Ченя не хочет укорачиваться (при этом длинное декодирование - работает):
/* * Find roots of the error+erasure locator polynomial. By Chien * Search */ COPY(®[1],&lambda[1],NN-KK); count = 0; /* Number of roots of lambda(x) */ for (i = 1; i <= NN ; i++) { q = 1; for (j = deg_lambda; j > 0; j--) if (reg[j] != A0) { reg[j] = modnn(reg[j] + j); q ^= Alpha_to[reg[j]]; } if (!q) { /* store root (index-form) and error location number */ root[count] = i; loc[count] = NN - i; count++; } }Мало того, в декодере в остальных циклах приходится прерывать итерации из середины (как раз где нули):
if((j>K-1)&&(j<KK))continue; //[0..K-1] ... [KK..NN-1] -
Опубликовано · Изменено пользователем repstosw · Пожаловаться
1 hour ago, des00 said:не вижу у вас в коде укорачивания кода в кодере с головы)
Я же писал, что укоротить кодирование не вышло.
1 hour ago, des00 said:кодер RS это же деление потока на полином. Если делить нули, то состояние регистра обратной связи не меняется. Вот и идите по этому пути, представив вашу структуру данных.
Обратная связь меняется. Она зависит от bb[NN - KK - 1], который меняется в любом случае.
Так просто не получится, как это сдалал в декодировании, укоротив циклы.
Немного ускорил кодирование до 28 FPS. За счёт более быстрой реализации функции (точнее - инлайна) остатка от деления на 65535:
static inline gf modnn(int x) { x = (x >> 16) + (x & 0xFFFF); /* sum base 2**16 digits */ if (x < 65535) return x ; if (x < (2 * 65535)) return x - 65535 ; return x - (2 * 65535); }Пробовал задавать таблично - в итоге скорость проседала до 14 FPS.
И всё-же как оптимизировать алгоритм кодирования?
-
12 hours ago, des00 said:
ну вообще RS обычно с головы укорачивают. Так экономнее кодировать и считать синдромы. Ну и зная укорочение можно немного сократить процедуру ченя.
Удалось ускорить работу декодера путём укорочения цыклов.
Было:
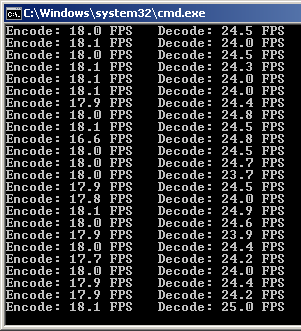
Стало:
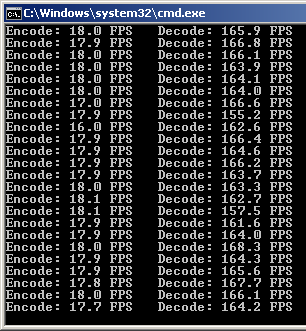
Данные разместил близко к проверочным символам.
NN - общая длина кода (65536 символов 16-бит)
EE - длина кода проверки (256 символов 16-бит)
KK - общая длина полезного сообщения (с нулями в начале, NN-EE)
K - интересующая длина полезного сообщения (без нулей, 4096 символов 16-бит)
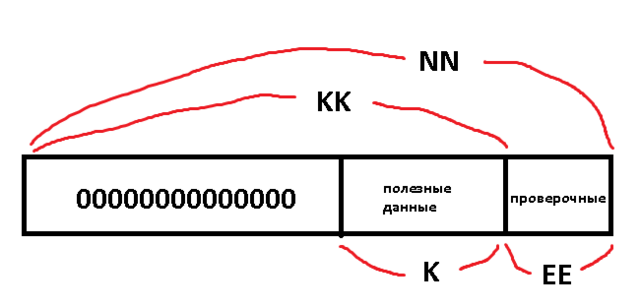
Не получается укоротить цикл в процедуре кодирования сообщения - при декодировании возникает ошибка.
Выкладываю проект целиком (исходники, сборка, готовый модуль) для тестирования на ПК, просьба помочь с кодером:
Для замера времени используется rdtsc (x64). Частота ядра 3 ГГц.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
Использую программное кодирование-декодирование Рида-Соломона.
Вначале взял RS GF(2^8), разбил пакет на части, сделал перемежение, затем закодировал, потом передал. Затем принял, раскодировал, де-перемежил, скорректировал ошибки. Всё работает, коды действительно облегчают условия приёма. Я не знаю где находятся ошибки (стирания), поэтому число исправляемых ошибок в 2 раза меньше числа символов проверки.
Меня не устраивает разбитие пакета на части, так как это накладывает ограничения по исправлению ошибок.
Затем взял RS GF(2^16). Надобность в перемежении отпала, так как длина пакета меньше, чем 65535 байт (2^16 -1). Здесь получается много нулевых байт, потому что размер пакета намного меньше, чем 65535. К тому же ещё и 2-байтные слова.Нулевые байты, естественно, не передаю. В приёмнике их дописываю на известные позиции.
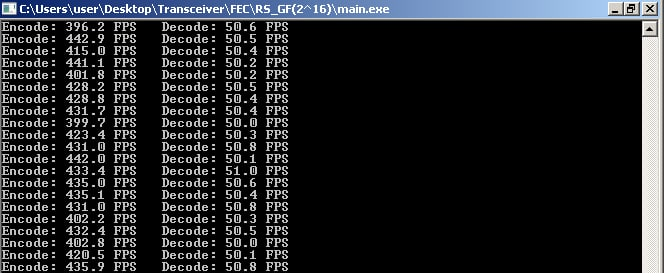
Работает тоже, но скорость работы просто ужасная. Исходный пакет 8192 байта, число ошибок - 256. Работает медленно - скорость декодирования всего 17 FPS (59 мс).
Получается 32 штуки 8-битных RS работает намного быстрее, чем один 16-битный RS.
Есть ли способы ускорить работу декодера RS GF(2^16) за счёт того, что известно, что после полезного пакета до проверочных символов - идут нулевые символы?
И вообще, есть ли какое-нибудь кодирование-декодирование длинных пакетов 1 кбайт - 8 кбайт?
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
7 hours ago, makc said:Это много кому надо, в том числе мне, только готовых открытых решений нет. Продают готовые реализации в виде библиотек или даже прошивок для микросхем кодеков с DSP, но это всё не то.
PS: на сколько я уяснил для себя после изучения этого вопроса, сейчас наиболее популярны многомикрофонные системы эхо/шумо подавления с одним или несколькими дополнительными микрофонами. Если хочется качество, то смотреть нужно именно в эту сторону и SPEEX по-моему этого не умеет.
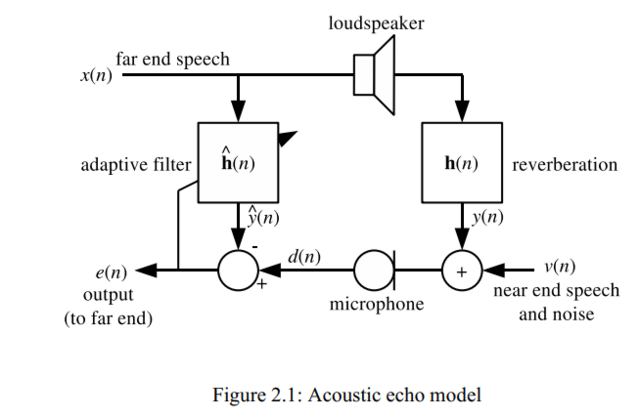
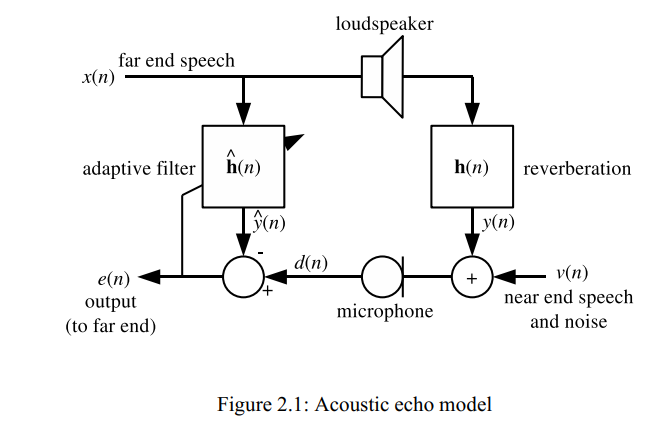
Я использую libspeexdsp. AEC, VAD и AGC.
В моём full-duplex цифровом трансивере эхоподавление(AEC) и активация по голосу(VAD) и АРУ(AGC) прекрасно работают.
Всё сделал как в примере testecho.c : размер "хвоста" в 8 раз больше, чем размера фрейма. Один фрейм 16,667 мс.
Записывал логи звука : после микрофона, после очистки, сигнал воспроизводимый в динамике. Разница есть.
Как это ни странно, но время эха у меня как раз оказалась именно в 8 раз больше времени одного фрейма. Потому что в приёмнике - двойная буферизация, в передатчике - тоже, плюс ещё декодирование конвеер. Итого задержка: 2x2x2x16,667 = 133 мс.
Кодек использую CELT 9-й версии. Кодек Speex не использую. CELT удобен тем, что можно выбрать размер сжатого фрейма в нужное количество байт, что упрощает синхронизацию с видео и её релизацию в коде (к примеру на 15 FPS, на один видео-фрейм приходится ровно четыре CELT фрейма по 16,667 мс).
 5 hours ago, andyp said:
5 hours ago, andyp said:эходав совсем тот, а шумодав может рокот движка, особенно когда обороты повыше, например, давануть примерно в той области где бошка человека находится
Эходав AEC
Шумодав - VAD. Убирает монотонный шум. Например: работающий вентилятор, кухонная вытяжка или шум автомобилей по трассе. VAD из Speex работает. Адаптивный. Через 1с - шум замолкает.
-
Столько времени провисел вопрос и никто не ответил.
Сдулись все что-ли?

Запустил AEC от Speex на фулл-дуплексе (с обоих сторон). Всё работает, эхо давит на 95%.
Правда пришлось повозиться... Была проблема кормления через зад, а не рот. Проще говоря, функции дают очищенный сигнал с микрофона для передачи. А я вначале думал, что сигнал очищается для динамика(воспроизведение). На вход: сигнал с микрофона(который будет содержать дополнительную составляющую с динамика - эхо) и воспроизводимый кусок с приёмника. На выходе - очищенный сигнал с микрофона для передачи.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
Делаю фулл-дуплекс. Приём и передача равными интервалами.
Одновременно нужно слушать собеседника и разговаривать с ним.
Возникает обратная связь: если я начну говорить, то слышу себя, так как микрофон собеседника передаёт звук с динамика.
Система цифровая. Только речевые сигналы
Есть ли способы подавить обратную связь?
Бегло просмотрел SPEEX DSP, там есть алгоритм подавления эха и AEC (acoustic echo cancellation). Они подойдут?
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
17 minutes ago, jcxz said:Когда-то боролся с похожим шумом (только от работы WiFi). Что только не делал: и питание (для WiFi) из разных точек брал; и LC-фильтры на питание ESP8266 вешал; и даже отдельный LDO для ESP - ничего не помогало!
 Всё равно шум в динамике (хотя УМЗЧ запитан от +7V с отдельного DC-DC, а ESP8266 - от DC-DC +5V с последующим LDO +3.3V). Потом тупо впаял конденсатор 2700 мкФ на шину 3.3V (после LDO) и... шум пропал!
Всё равно шум в динамике (хотя УМЗЧ запитан от +7V с отдельного DC-DC, а ESP8266 - от DC-DC +5V с последующим LDO +3.3V). Потом тупо впаял конденсатор 2700 мкФ на шину 3.3V (после LDO) и... шум пропал! 
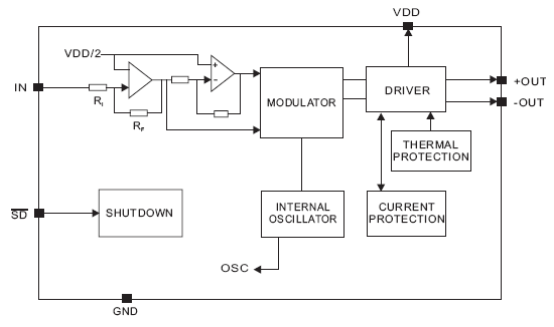
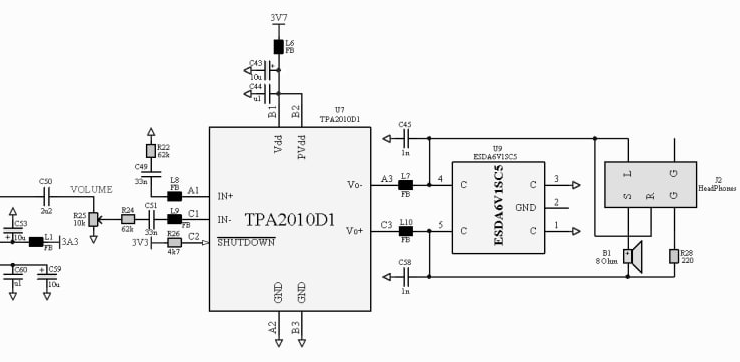
Мне непонятно почему этот усилитель(PAM8301) вообще восприимчив к шумам в питании. У него дифференциальный выход. Значит должны быть по барабану пульсации питающего напряжения - всё прыгает относительно точки половины питания. Вот TPA2010 работает как надо - питаю его прямо от литий-ионного аккумулятора (первичный источник питания).
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
36 minutes ago, mantech said:Во вторых для слабых DC-DC такая емкость будет восприниматься, как длительное КЗ и они могут просто сгореть...
Ничего не сгорит. Потому что RC. Резистор не даст конденсатору начать быстро заряжаться - жёсткого КЗ в начальный момент не будет.
А без резистора фильтрация не работает: хоть 1000 мкФ поставь.
Эмпирически взял 15 Ом + 470 мкФ. Емкости 100 и 220 мкФ хуже подавляют щелчки (15 Гц - частота запуска G2D, растягивающего и поворачивающего на 90 градусов кадр).
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
38 minutes ago, jcxz said:1. Сделать отдельный источник питания для УМЗЧ.
2. Попробовать вешать конденсатор огромной ёмкости (тысячи-десятки тысяч мкФ) на разные питания.
Проблема оказалась не в HPOUT (выход с HPOUT на наушники - чистый), а в усилителе мощности PAM8301 - он сильно восприимчив к пульсациям питания. И это странно. Потому что у него выход дифференциальный.
Применял аналогичный усилитель TPA2010 - таких проблем не возникало - этот усилитель устойчив к пульсациям питания.
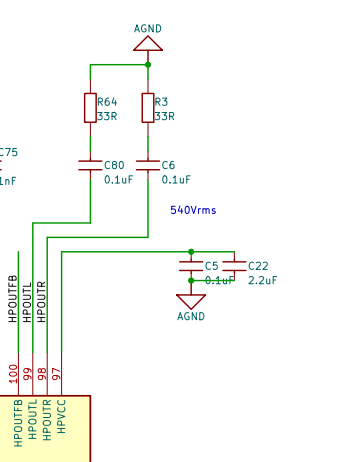
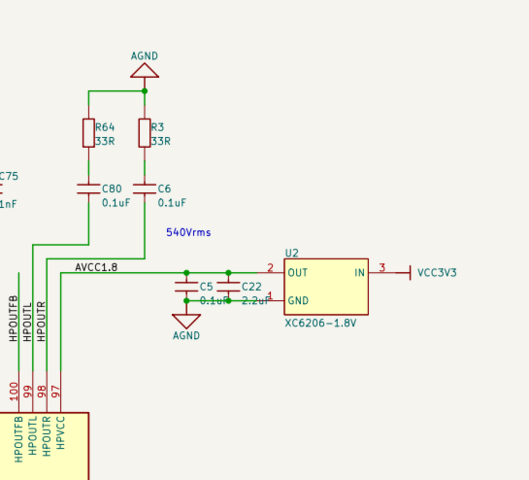
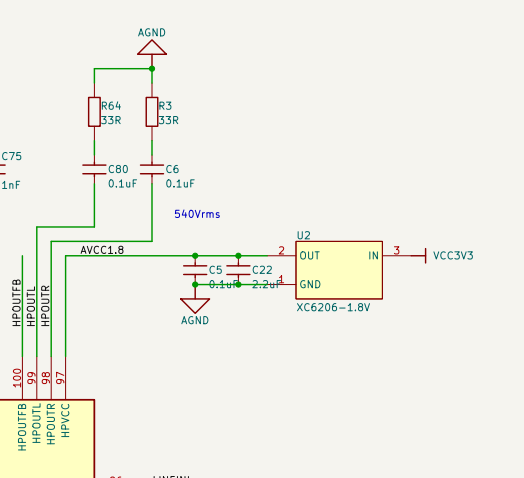
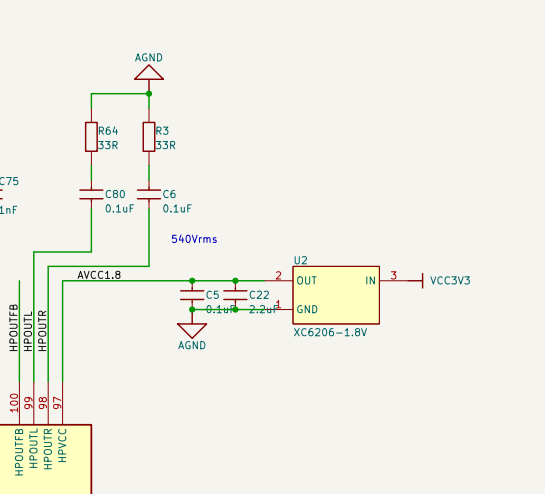
Мало того, на плате MangoPi MQ-R отсутствует внешний LDO(1,8V) для HPVCC - звук был очень слабый. Включил внутренний LDO регистром. Замерял напряжение на 97-й ноге: появилось. Звук стал сильным.
На плате MangoPi MQ-Dual этот внешний LDO есть.
Китайцы что хотят, то и творят называется...
MangoPi MQ-R (куцая которая): https://mangopi.org/mangopi_mqr
MangoPi MQ-Dual: https://mangopi.org/mangopi_mq
А щелчки ушли, как только добавил RC-звено по питанию: 15 Ом + конденсатор 470 мкФ (с меньшей ёмкостью - результат хуже):
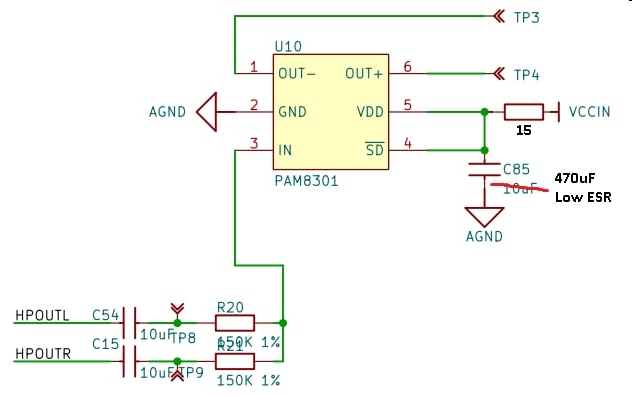
Пришлось сдувать феном PAM8301 и паять её боком, чтобы добавить резистор 15 Ом:

Пробовал подать питание с 3,3V DC/DC - щелчки тише, но есть.
В идеале - отдельный LDO для этого усилителя. Или отказаться от него и использовать тот, который не восприимчив к пульсациям питания - TPA2010:
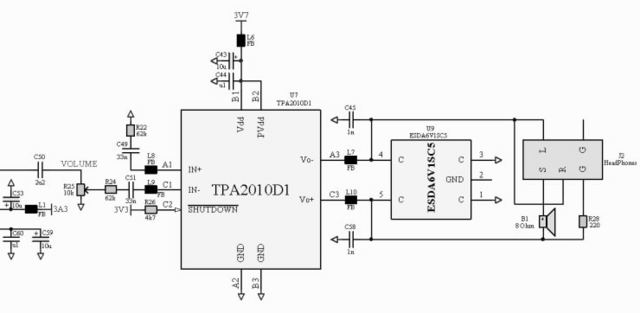
-
Настало время поговорить о помехозащищённости акустического тракта у плат MangoPi.
Столкнулся с тем, что в наушниках слышна работа G2D - щелчки с частотой запуска G2D.
Если G2D исключить из работы - щелчки прекращаются.
Наушники соединены последовательно, земля не используется. Только HPOUTL и HPOUTL. HPOUTFB соединён через конденсатор 0,1 мкФ на AGND.
Источник питания на AVCC свой - HPVCC 1.8V.
Тем не менее, слышен любой шум - даже с USB компа при движении мыши или записи на жёсткий диск.
Шум при запуске G2D:
Что можно предпринять в данной ситуации?


Allwinner T113-s3 уделал HiFi4 DSP. Смеяться или плакать?
в TI, Allwinner, GigaDevice, Nordic, Espressif и другие
Опубликовано · Изменено пользователем repstosw · Пожаловаться
Не нашёл такого в IAR 7.60.
Так называемый "SDK" для H616: https://github.com/dumtux/Allwinner-H616/tree/develop
Мда... Называть помойку под названием сорцы Линукса - SDK, это верх дебилизма. Вот у меня SDK. Все примеры которого можно запускать независимо друг от друга.
Я уже понял что у китайцев SDK - это линукс. Но ведь они этот линукс же пишут, смотря куда и во что??? Вот это было бы интересно.
А так придётся снова сношать свой мозг чтобы из этой помойки вычленить нужное и превратить его в независимое.