


repstosw
-
Постов
2 650 -
Зарегистрирован
-
Победитель дней
2
Сообщения, опубликованные repstosw
-
-
Актуально.
-
On 11/13/2023 at 11:24 AM, repstosw said:
Теперь слабым местом стал поиск Ченя.
Оптимизировал и его. Результат:
Декодирование ускорено в 2.6 раз, кодирование - в 1.8 раз (по сравнению с исходным вариантом, для Cortex-A7).
-
Завершил оптимизацию кодека.
Что было:
Кодирование: 20.8 FPS Декодирование(исправление максимального числа ошибок): 11.8 FPS Поиск синдромов(декодирование при отсутствии ошибок): 19.1 FPS Поиск Ченя: 59.4 FPS
Что стало:
Кодирование: 37.1 FPS Поиск синдромов(без разложения): 25.0 FPS => Декодирование: 14.7 FPS Поиск синдромов(4-ступенчатое разложение): 258.5 FPS => Декодирование: 31.6 FPS Поиск Ченя: 67.8 FPS
Декодирование ускорено в 2.6 раз, кодирование - в 1.8 раз.
-
Ещё одна статья, как быстро считать синдромы, применяя много-ступенчатое преобразование: https://ipnpr.jpl.nasa.gov/progress_report2/42-52/52J.PDF
И ещё https://ipnpr.jpl.nasa.gov/progress_report2/42-54/54K.PDF
Сделал 4-х ступенчатые преобразования для:
GF(2^16): 3*5*17*257 и GF(2^12): 5*7*9*13
Выигрыш в скорости нахождения синдромов ошибок с помощью разложений - колоссален.
Теперь слабым местом стал поиск Ченя.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
On 11/10/2023 at 11:12 PM, repstosw said:Так что будущее - за преобразованиями Винограда. По-другому этот кодек уже не раскачаешь. Странно, что на гитхабе нет имплементаций кодеков с этим преобразованием. Все тупо лепят классику. Но справедливости ради, замечу, что форма преобразований зависит от размерности (порядка поля GF) кодека. Нет универсальных преобразований Винограда для любого порядка.
Перешёл тренироваться в поле GF(2^8). Освоил трёх-ступенчатое преобразование, которое по сравнению с 2-х ступенчатым дало выигрыш ещё больше.
Статья, как быстро считать синдромы, применяя много-ступенчатое преобразование: https://ipnpr.jpl.nasa.gov/progress_report2/42-52/52J.PDF
Отладил алгоритм на ПК, затем перенёс на T113-s3. Ниже результаты, причём без оптимизации кода, изменён только алгоритм. FPS справедлив для одного блока 255 символов (GF 2^8 )
Результаты 2-ступенчатого преобразования (255 = 3 * 85 ) - выигрыш в скорости нахождения синдромов 1,6x :
Classic: 1040.4 FPS Winograd: 1604.7 FPS Classic: 1041.1 FPS Winograd: 1604.7 FPS Classic: 1039.3 FPS Winograd: 1604.7 FPS Classic: 1040.4 FPS Winograd: 1604.3 FPS Classic: 1039.7 FPS Winograd: 1605.1 FPS Classic: 1037.9 FPS Winograd: 1604.7 FPS Classic: 1042.6 FPS Winograd: 1605.6 FPS Classic: 1040.8 FPS Winograd: 1606.9 FPS Classic: 1041.1 FPS Winograd: 1606.0 FPS Classic: 1043.1 FPS Winograd: 1604.3 FPS
Результаты 3-ступенчатого преобразования (максимальное разложение для 255 = 3 * 5 *17 ) - выигрыш в скорости 5.6x :
Classic: 1037.9 FPS Winograd: 5848.0 FPS Classic: 1039.1 FPS Winograd: 5859.4 FPS Classic: 1039.1 FPS Winograd: 5842.3 FPS Classic: 1039.3 FPS Winograd: 5876.6 FPS Classic: 1037.9 FPS Winograd: 5865.1 FPS Classic: 1040.0 FPS Winograd: 5859.4 FPS Classic: 1039.5 FPS Winograd: 5842.3 FPS Classic: 1038.2 FPS Winograd: 5836.6 FPS Classic: 1040.0 FPS Winograd: 5853.7 FPS Classic: 1039.7 FPS Winograd: 5825.2 FPS
Осталось теперь перейти в GF(2^16) и сделать 4-ступенчатое разложение: 2^16-1 = 65535 = 3 * 5 * 17 * 257

-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
1 hour ago, sasamy said:Для MM = 16 эти таблицы содержат 65536 элементов, для MM = 12 количество элементов 4096
мне казалось что это должно ускорить доступ а у вас он парадоксально замедлился 🙂
Потому что увеличилось число проверочных символов. А цикла там два - вложенные: один по K+E, второй по E.
В итоге сложность вычислений выросла квадратично. И во столько же раз - количество обращений к таблицам.
На таблицах там реальный прирост скорости, когда GF(2^8) и меньше (элемент таблиц - 1 байт).
Попробовал разогнать DDR, с дефолтных 792 МГц до 1008 МГц. Ощутимого выигрыша не даёт - скорость декодирования увеличилась всего на +1 FPS. Очевидно, включенный кеш данных и частота ядра значат больше, чем частота DDR.
Так что будущее - за преобразованиями Винограда. По-другому этот кодек уже не раскачаешь. Странно, что на гитхабе нет имплементаций кодеков с этим преобразованием. Все тупо лепят классику. Но справедливости ради, замечу, что форма преобразований зависит от размерности (порядка поля GF) кодека. Нет универсальных преобразований Винограда для любого порядка.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
20 hours ago, repstosw said:Собственно вопрос, как определить третий и пятый корни ? Порождающий полином: 1 + x + x^3. Поле GF(16) GF(2^4)
Вопрос решён.
Сделал имплементацию 3-точечного преобразования на Си - для GF(2^4): цикл нахождения синдромов длиной 15 итераций сжался до длины 5 итераций.
Результат сравнил с результатами по старому методу.
https://ipnpr.jpl.nasa.gov/progress_report/42-43/43Q.PDF
Значит, аналогично можно сделать и для GF(2^16).
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
18 hours ago, sasamy said:а почему не подходит GF(2^^12) ? мне кажется он в разы быстрей будет, надо только битовый буфер раскидать на слова с 12 значащами битами - сдвигами можно очень быстро раскидывать 3 байта на 2 слова по 12 бит, а потом обратно сериализовать уже с добавленными избыточными символами для передачи, приём тоже самое раскидать принятый буфер на слова, восстановить и снова в битовый буфер сериализовать.
Потому что с GF(2^12) производительность декодера ещё меньше - 12 FPS.
Исходные данные: весь пакет максимально 5952 байт. Из них 1168 байт максимально на проверку ошибок.
Для GF(2^16) это укороченый RS код (2976,2392) символа (16 бит, 2 байта на 1 символ).
Для GF(2^12) этим условиям соответствует укороченный RS код (3968,3190) символа (12 бит, 3 байта на 2 символа).
Скорость кодирования немного выросла (40+ FPS), но вот декодирование упало (до 12 FPS).
Основная проблема - промахи кеша данных при хаотичных обращениях к таблицам Alpha_to и Index_of, которые нужны для расчёта арифметики Галуа: первая таблица возводит в степень, вторая - логарифмирует.
Их использование ускоряет вычисления в GF: сложение, вычитание, умножение, возведение в степень.
20 hours ago, repstosw said:Можно применить 4-х этапное преобразование Винограда, свернув большой цикл (0..65535) в четыре мелких (3, 5 , 17, 257)
Удалось раскурить этот матан для поля GF(2^4) - сделал программную имплементацию 3-точечного преобразования: цикл нахождения синдромов длиной 15 итераций сжался до длины 5 итераций. Нахождение синдромов ошибок - самая ресурсоёмкая часть в декодере RS.
Результаты сравниваю с результатами расчётов, выполеннных по старому методу.
По вот этой статье делал: https://ipnpr.jpl.nasa.gov/progress_report/42-43/43Q.PDF
На русском языке более-менее понятную статью про свёрточное преобразование нашел здесь: https://habr.com/ru/articles/477718/
Но она не применима к моим задачам, но дала понять общий принцип.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
On 11/8/2023 at 6:38 PM, sasamy said:на Linux быстрей работает
Мне удалось сделать 14,96 FPS декодирование и 39 FPS кодирование.
Процедура остатка от деления - вместо константы NN, добавил переменную, в которой присвоено значение NN. Хитрость в том, что вместо двух инструкций вычитания IMMEDIATE, делается одна инструкция вычитания регистра. И местами цикл будет длинным - 2/3 итерации.
unsigned int nn=NN; static inline unsigned int modnn2(unsigned int x) { while(x>=nn) { x-=nn; x=(x>>MM)+(x&nn); } return x; } static inline unsigned int gf_sub(unsigned int x,unsigned int y) { y=x-y; return y+(y>x)*NN; } #define gf_add(x,y) gf_sub(x,NN-(y))
В кодировании выбросил проверку элементов полинома Gg[ i ] на значение A0. Но с этим надо быть аккуратнее - вначале проверить. Потому что я заменил полином на другой, который как раз позволил выкинуть эту проверку.
#elif(MM == 16) int Pp[MM+1] = { 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1 }; //the best of speed
void encode_rs(dtype *data) { dtype *bb=&data[K]; CLEAR(bb,EE); for(int i=K-1;i>=0;i--) { gf feedback=data[i]^bb[EE-1]; if(feedback) /* feedback term is non-zero */ { feedback=Index_of[feedback]; for(int j=EE-1;j>0;j--)bb[j]=bb[j-1]^Alpha_to[gf_add(Gg[j],feedback)]; //здесь Gg[j] никогда не будет A0 - проверил bb[0]= Alpha_to[gf_add(Gg[0],feedback)]; } else /* feedback term is zero. encoder becomes a single-byte shifter */ { for(int j=EE-1;j>0;j--)bb[j]=bb[j-1]; bb[0]=0; } } }
Но это всё мелочи. Виноград и Китайская теорема об остатках - способны ускорить этот алгоритм. Но придётся курить матан, так как имплементации на Си не нашёл.
65535 - это 3*5*17*257. Можно применить 4-х этапное преобразование Винограда, свернув большой цикл (0..65535) в четыре мелких (3, 5 , 17, 257)
-
On 11/6/2023 at 2:48 AM, thermit said:
Принципиально тут ничего оптимизировать нельзя.
Сейчас смотрю в сторону преобразований Винограда и Китайскую теорему об остатках. Есть научные выкладки на сайте nasa.gov , что в алгоритме поиска синдромов можно сократить вычисления.
Пришлось курить линейную алгебру, вспоминать матрицы, вектора и операции над ними.
Пока работаю в поле GF(2^4) - это всего 16 элементов: 0..15
Собственно вопрос, как определить третий и пятый корни ? Порождающий полином: 1 + x + x^3. Поле GF(16) GF(2^4)
-
2 hours ago, makc said:
Нет, если данные уже есть в кеше.
И это хорошо.
Читал, что в разных архитектурах по-разному: кеш либо до MMU, длибо после него.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
1 hour ago, thermit said:А выкалывание делается так: на передающей стороне на 3 входных бита получаем 12 на выходе кодера. 8 бит выкидываются. Получаем 3/4. На приемной стороне недостающие биты заполняются 0.
Исчерпывающе. Попробую из 1/2 сделать 3/4.
1 hour ago, thermit said:Ну и http://www.eccpage.com. Очень полезный.
Неплохо. Правда Generic всё - придется оптимизировать.
Немного удалось поднять скорость кодера RS на нужных мне параметрах (2976 символов сообщения + 584 проверочных, GF 2^16).
На Allwinner T113-s3 (ARM A7, 1200 МГц) кодирование было 32 FPS, стало 39. Изначально вообще было 6 FPS (без укорочения циклов до длины полезной части сообщения)
С декодированием всё хуже, самые ресурсоёмкие места: поиск синдромов и Чень. Второй уже ускорен, с первым не получается.
Поиск синдромов:
//Alpha_to - статический массив //modnn - остаток от деления на 65535. //K - число символов сообщения //EE - число проверочных символов //KK - число сивмволов сообщения + нули for(i=0;i<K+EE;i++)recd[i]=Index_of[data[i]]; /* data[] is in polynomial form, copy and convert to index form */ /* first form the syndromes; i.e., evaluate recd(x) at roots of g(x) * namely @**(B0+i), i = 0, ... ,(EE-1) */ syn_error=0; for(i=0;i<EE;i++) { tmp=0; unsigned int w[2]={0,i*KK}; gf *v[2]={&recd[0],&recd[K]}; int n[2]={K,EE}; while(n[0]--) { if(*v[0]!=A0)tmp^=Alpha_to[modnnF(*v[0]+w[0])]; v[0]++; w[0]+=i; } while(n[1]--) { if(*v[1]!=A0)tmp^=Alpha_to[modnnF(*v[1]+w[1])]; v[1]++; w[1]+=i; } syn_error|=tmp; /* set flag if non-zero syndrome => error */ s[i+1]=Index_of[tmp]; /* store syndrome in index form */ } if(!syn_error) { /* * if syndrome is zero, data[] is a codeword and there are no * errors to correct. So return data[] unmodified */ printf("Syndrome OK!\n"); return 0;
Было: 14,3 FPS, стало 14,7 FPS (изначально было 2,3 FPS). Что можно ещё придумать с кодом выше?
-
Допустим MMU настроено так, что есть пара виртуальных адресов памяти:
0x40000000 0x40020000
Которые ссылаются на один и тот же физический адрес памяти:
0x40000000Кеширование и буфер включены в MMU для этих регионов (биты C и B).
Собственно вопрос: при чтении-записи в эти виртуальные адреса - как будет работать кеширование и буферизация?
Будут ли заново читаться-записываться память второго региона, если ранее происходили чтение-запись первого региона?
Проще говоря - кеширование работает по физическим или виртуальным адресам? Линии кеша обновляются при изменении содержимого по виртуальному или физическому адресу?
-
23 hours ago, thermit said:
3/4 и все такое получаются из 1/4 через выкалывание. Реализации существуют. Надо в хухеле поискать.
"Прикольный" ответ. Предполагалось, что задавший вопрос излазил весь интернет в поисках нужного, и не найдя, задал вопрос здесь.
Плюс декодирование Витерби: каким образом восстанавливается то, что выкололи или чем замещается?
Вопрос имплементации свёрточника 3/4 на Си остаётся в силе.
-
On 11/3/2023 at 3:24 AM, thermit said:
Рс обычно в каскаде используется. Со сверточным.
Слишком дорогое удовольствие - сверточный кодер. CR = 1/2, 1/3, 1/6.
Я могу позволить выделить на проверочные символы не более 1/4. (25%) от всего фрейма.
Имплементация сверточного кодера с CR 3/4 , 4/5, 5/6, 7/8 - существует? На сях.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
1 hour ago, sasamy said:а сколько это мегабит в секунду ? попробовал симулятор на этом процессоре (t113-s3) в линуксе кодирование + декодирование и мне кажется он значительно больше показывает - порядка 1.340 Mb/s, ваши параметры не знаю - пальцем в небо ткнул исправлять 100 ошибок на 2047 символов
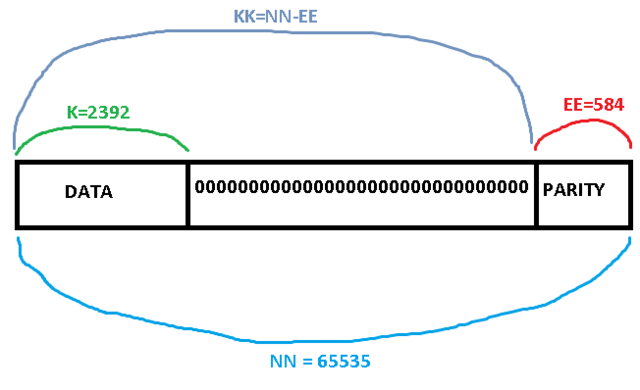
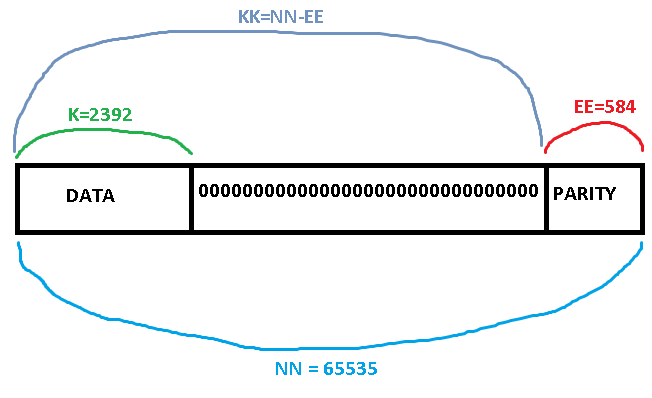
Параметры такие:
M=16 (GF 2^16) -- степень полинома (Galois field order)
NN = 65535 -- общая длина блока в 16-битных символах
EE = 584 -- размер блока проверочных символов
K = 2392 -- размер блока полезных символов (отличается от KK = NN - EE )
Оптимизированный мод даёт на T113-s3 (1200 МГц) такие показатели -
причём время декодирования здесь в случае, когда число ошибок максимально и декодер может восстановить пакет (число ошибок = половина от числа проверочных символов).
Ясен фиг, что если ошибок будет меньше - декодирование пойдёт быстрее.
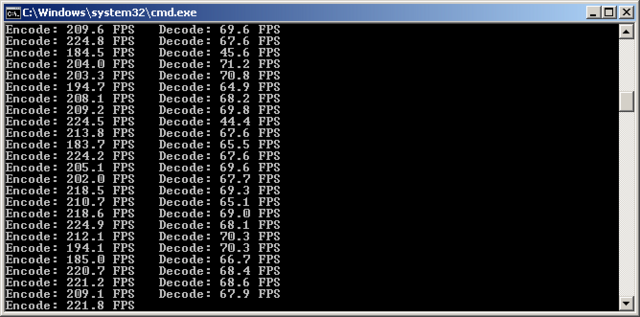
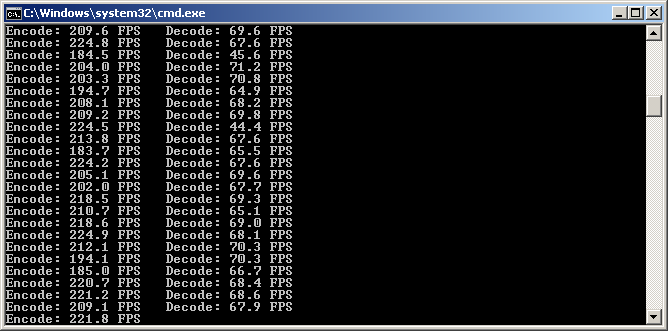
T113-s3... FEC T113-s3 CPU ===> Encode: 35.68 FPS Decode: 14.60 FPS T113-s3 CPU ===> Encode: 35.71 FPS Decode: 14.60 FPS T113-s3 CPU ===> Encode: 35.70 FPS Decode: 14.60 FPS T113-s3 CPU ===> Encode: 35.70 FPS Decode: 14.62 FPS T113-s3 CPU ===> Encode: 35.70 FPS Decode: 14.61 FPS T113-s3 CPU ===> Encode: 35.71 FPS Decode: 14.60 FPS T113-s3 CPU ===> Encode: 35.70 FPS Decode: 14.63 FPS T113-s3 CPU ===> Encode: 35.70 FPS Decode: 14.61 FPS T113-s3 CPU ===> Encode: 35.68 FPS Decode: 14.60 FPS T113-s3 CPU ===> Encode: 35.69 FPS Decode: 14.64 FPS T113-s3 CPU ===> Encode: 35.72 FPS Decode: 14.62 FPS T113-s3 CPU ===> Encode: 35.70 FPS Decode: 14.63 FPS T113-s3 CPU ===> Encode: 35.71 FPS Decode: 14.60 FPS
Воркбенч с кодеком приложил: rs_fec.zip
Суть моей оптимизации - ускорение поиска Ченя: упрощены вычисления, на промежутке [ K .. KK - 1 ], где находятся нули в блоке (не используются):
Spoiler/* * Find roots of the error+erasure locator polynomial. By Chien * Search */ COPY(®[1],&lambda[1],EE); count = 0; /* Number of roots of lambda(x) */ for (i = NN-1; i >= KK; i--) //Parity { q = 1; for (j = deg_lambda; j > 0; j--) if (reg[j] != A0 ) { reg[j]= /*gf_add(reg[j],j)*/ modnn1(reg[j]+j) ; q ^= Alpha_to[reg[j]]; } // if(q)continue; if (!q) { /* store root (index-form) and error location number */ root[count] =NN-i; // loc[count] = i; //позиции ошибочных байт // count++; if(++count==deg_lambda)break; } } for(j=deg_lambda;j>0;j--)if(reg[j]!=A0)reg[j]= /*gf_add(reg[j],nool[j])*/ modnnF(reg[j]+(j*(KK-K))) /*modnn1(reg[j]+nool[j])*/ ; //!!! for (i = K-1; i >= 0 ; i--) //Data { q = 1; for (j = deg_lambda; j > 0; j--) if (reg[j] != A0) { reg[j]= /*gf_add(reg[j],j)*/ modnn1(reg[j]+j) ; q ^= Alpha_to[reg[j]] ; } // if(q)continue; if (!q) { /* store root (index-form) and error location number */ root[count] =NN-i; // loc[count] = i; //позиции ошибочных байт // count++; if(++count==deg_lambda)break; } }
1 hour ago, sasamy said:исправлять 300 ошибок 0.39 Mb/s
Galois field order = 11. Нечестно! У меня 16 : как раз чтобы 2 байта компактно разместить в один символ.
И ошибок по-больше.
Параметры блока напиcал в предыдущем посте.
-
2 hours ago, sasamy said:
https://godbolt.org/z/dd55Wjo68
Работает, но вот реализация оказалась быстрее:
static inline unsigned int modnn1(unsigned int x) { for(;x>=NN;x-=NN)asm volatile ("" ::: "memory"); return x; } modnn1: movw r3, #65534 cmp r0, r3 bxls lr sub r0, r0, #65280 sub r0, r0, #255 bx lr
Удалось поднять производительность кодера - на 12%, путём замены на суммирование:
static inline unsigned int gf_sub(unsigned int x,unsigned int y) { y=x-y; return y+(y>x)*NN; } #define gf_add(x,y) gf_sub(x,NN-(y)) void encode_rs(dtype *data) { dtype *bb=&data[KK]; gf feedback; register int i,j; CLEAR(bb,EE); for(i=K-1;i>=0;i--) { feedback=Index_of[data[i]^bb[EE-1]]; if(feedback!=A0) /* feedback term is non-zero */ { for(j=EE-1;j>0;j--)if(Gg[j]!=A0)bb[j]=bb[j-1]^Alpha_to[ gf_add(Gg[j],feedback) /*modnn(Gg[j]+feedback)*/ ]; else bb[j]=bb[j-1]; bb[0]=Alpha_to[ gf_add(Gg[0],feedback) /*modnn(Gg[0]+feedback)*/ ]; } else /* feedback term is zero. encoder becomes a single-byte shifter */ { for(j=EE-1;j>0;j--)bb[j]=bb[j-1]; bb[0]=0; } } }
Но декодер, плохо поддаётся оптимизации. Было 14.3 FPS, стало 14.6
2 minutes ago, thermit said:Вы-то что хотите?
Ускорить работу декодера с 14 FPS , до 16. Это как минимум. В идеале - больше, чтобы больше ошибок исправлялось.
14,6 уже есть.
5 minutes ago, thermit said:Все вычисления только через таблицу.
Слишком хаотичные выборки из таблицы. Кеш мажет. С увеличением таблицы - падает производительность. Это в GF 2^8 всё быстро, так как таблицы небольшие. Для GF 2^16 таблицы раздуваются.
Пробовал жать RAR-архивом таблицы Index_Of, Alpha_to - практически не сжимаются. Потому что хаоса там предостаточно.
8 minutes ago, repstosw said:static inline unsigned int gf_sub(unsigned int x,unsigned int y) { y=x-y; return y+(y>x)*NN; }
Асм даёт вот такое изящество - без условий, от того и быстро работает кодер:
gf_sub: subs r0, r0, r1 addcc r0, r0, #65280 addcc r0, r0, #255 bx lr
-
6 minutes ago, thermit said:
Ну давайте разберем.x=65535. Мы его эндим с 65535. Получаем 65535. И это чудо мы суммируем с 0. Что получится? Я пойду нахрен застрелюсь, если это будет 0. Обещаю
Никто не спорит, что данное выражение даст 65535.
Но нам это не нужно! Нам нужен остаток от деления на 65535.
Данное выражение не реализует остаток от деления на 65535.
-
20 minutes ago, repstosw said:
То на выходе будет ужас:
Если добавить барьер компилятору:
unsigned int __attribute__ ((noinline)) modnn1(unsigned int x) { while(x>=NN) { x-=NN; asm volatile ("" ::: "memory"); } return x; }
То выглядит воплне прилично:
modnn1: movw r3, #65534 cmp r0, r3 bxls lr .L8: sub r0, r0, #65280 sub r0, r0, #255 cmp r0, r3 bhi .L8 bx lr
Интересно, что-ж его понесло?
-
Тут ещё попутно обнаружил, что компилятор создаёт монстров.
Функция:
unsigned int __attribute__ ((noinline)) modnnF(unsigned int x) { while(x>=NN) { x-=NN; x=(x>>MM)+(x&NN); } return x; }
Ассемблируется в полне нормальный вид:
modnnF: movw r2, #65534 cmp r0, r2 bxls lr .L3: sub r0, r0, #65280 sub r0, r0, #255 uxth r3, r0 add r0, r3, r0, lsr #16 cmp r0, r2 bhi .L3 bx lr
Но если сделать так:
unsigned int __attribute__ ((noinline)) modnn1(unsigned int x) { while(x>=NN)x-=NN; return x; }
То на выходе будет ужас:
Spoilermodnn1: movw r3, #65534 mov r2, r0 cmp r0, r3 bxls lr sub r0, r0, #65280 movw r1, #32769 movt r1, 32768 sub r0, r0, #255 movw r3, #65527 umull ip, r1, r1, r0 movt r3, 7 cmp r0, r3 lsr r1, r1, #15 add r1, r1, #1 bls .L8 vdup.32 q8, r2 vldr d18, .L14 vldr d19, .L14+8 vldr d22, .L14+16 vldr d23, .L14+24 vldr d20, .L14+32 vldr d21, .L14+40 vadd.i32 q8, q8, q9 lsr r0, r1, #2 mov r3, #0 .L9: vmov q9, q8 @ v4si add r3, r3, #1 cmp r0, r3 vadd.i32 q8, q8, q11 vadd.i32 q9, q9, q10 bne .L9 bic r3, r1, #3 cmp r1, r3 sub r3, r3, r3, lsl #16 vmov.32 r0, d19[1] add r2, r2, r3 bxeq lr sub r0, r2, #65280 sub r0, r0, #255 .L8: movw r3, #65534 cmp r0, r3 bxls lr mov r0, #2 movt r0, 65534 add r0, r2, r0 cmp r0, r3 bxls lr mov r0, #3 movt r0, 65533 add r0, r2, r0 cmp r0, r3 bxls lr sub r0, r2, #261120 sub r0, r0, #1020 cmp r0, r3 bxls lr mov r0, #5 movt r0, 65531 add r0, r2, r0 cmp r0, r3 bxls lr mov r0, #6 movt r0, 65530 add r0, r2, r0 cmp r0, r3 bxls lr mov r0, #7 movt r0, 65529 add r0, r2, r0 cmp r0, r3 movhi r0, #8 movthi r0, 65528 addhi r0, r2, r0 bx lr .L15: .align 3 .L14: .word 0 .word -65535 .word -131070 .word -196605 .word -262140 .word -262140 .word -262140 .word -262140 .word -65535 .word -65535 .word -65535 .word -65535 .size modnn1, .-modnn1
GCC v. 10.3
Флаги компиляции:
CFLAGS=-DNDEBUG -DUSE_JPWL -Ofast -marm -mcpu=cortex-a7 -mfloat-abi=hard -mfpu=vfpv4 -mfpu=neon \ -ftree-vectorize -fno-math-errno -fmax-errors=1 -ffunction-sections -fdata-sections
Как раз тот случай, когда считаешь компилятор дрУгом, а он оказывается врагом

-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
2 hours ago, sasamy said:скорей всего в вашем наборе большинство данных меньше 65535, кстати попробуйте вариант modnn3()
unsigned int modnn3(unsigned int x) { x=(x>>16)+(x&65535); x=(x>>16)+(x&65535); return x; }
Даёт неверное значение при x=65535. Должно быть 0, возвращает 65535.
А так, всё верно - тормоза при сравнении и вычитании, оно выходит составное:
sub r0, r0, #65280 subs r0, r0, #255
Всё потому, что ARM не умеет нормально загружать произвольные константы в свои регистры.
-
On 11/1/2023 at 1:44 AM, thermit said:
Но бывают и не примитивные бчх. 65537 - простое число.
Данный полином не удвовлетворил кодек Рида -Соломона.
Вот эти удовлетворяют (записаны в 8-ричной системе счисления, для GF 2^16):
210013, 234313, 233303, 307107, 307527, 306357, 201735, 272201, 242413, 270155, 302157, 210205, 305667, 236107
On 10/31/2023 at 6:53 PM, des00 said:да вроде всегда так делали, вычитанием если надо.
c = a + b; rslt = (c >= 65535) ? (c - 65535) : cПочему-то этот вариант работает медленее (на ARM Cortex-A7), чем вот этот вариант:
unsigned int modnn(unsigned int x) { while(x>=65535) { x-=65535; x=(x>>16)+(x&65535); } return x; }
В чём фокус? Функция попала целиком в кеш? Или аппаратное выполнение по условию?
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
4 hours ago, sasamy said:эту не смотрели ?
Смотрел. Всё теже самые тормоза, нуждающиеся в оптимизации. Конкретно меня интересует RS GF(2^16):
https://github.com/HAMNET-Access-Protocol/libfec/blob/master/decode_rs.h#L218
Поиск Ченя не оптимизирован: цикл от 1 до NN - тоесть на всю длину блока 65535 символов. На моём ПК это даёт 12 - 15 FPS всего.
Нужно оптимизировать, к примеру полезная длина 2976 символов + проверочные (600-16) символов:
//1 ------------------------------------------ for(j=deg_lambda;j>0;j--)if(reg[j]!=A0)reg[j]=MODNN(reg[j]+(j*((NN-1)+1-(2976+600-16)))); k=(NN-1)-(2976+600-16); //2 ------------------------------------------ for(i=2976+600-16-1;i>=0;i--) { q = 1; /* lambda[0] is always 0 */ for(j=deg_lambda;j>0;j--) { if(reg[j]!=A0) { reg[j]=MODNN(reg[j]+j); q^=ALPHA_TO[reg[j]]; } } k++; if(q!=0)continue; /* Not a root */ /* store root (index-form) and error location number */ root[count]=NN-i; loc[count]=k; /* If we've already found max possible roots, * abort the search to save time */ if(++count==deg_lambda)break; }
Плюс элемент массивов должен быть short int, а не Int. Это даёт возможность в 2 раза меньше загружать кеш. Так как размерность символа как раз укладывается в short int, нет надобности забивать кеш ненужными нулями.
С этими двумя приёмами FPS на ПК вырос до 68 - 70. При условии, если декодируется пакет с максимально допустимым числом ошибок - (600-16)/2 символов.
Бенчмарк в спойлере:
Spoiler/* Test the Reed-Solomon codecs * for various block sizes and with random data and random error patterns * * Copyright 2002 Phil Karn, KA9Q * May be used under the terms of the GNU Lesser General Public License (LGPL) */ #include <stdio.h> #include <stdlib.h> #include <memory.h> #include <time.h> #include "fec.h" #define random rand #define srandom srand struct etab { int symsize; int genpoly; int fcs; int prim; int nroots; int ntrials; } Tab[] = { {9, 0x211, 1, 1, 32, 10 }, {10,0x409, 1, 1, 32, 10 }, {11,0x805, 1, 1, 32, 10 }, {12,0x1053, 1, 1, 32, 5 }, {13,0x201b, 1, 1, 32, 2 }, {14,0x4443, 1, 1, 32, 1 }, {15,0x8003, 1, 1, 32, 1 }, { 16,0x1100b, 1, 1, /*32*/ (600-16), 1 }, //!!! // sym genpoly fcs prim nroots ntrials {0, 0, 0, 0, 0}, }; int exercise_int(struct etab *e); int main(void) { int i=7; srandom(time(NULL)); int nn,kk; nn = (1<<Tab[i].symsize) - 1; kk = nn - Tab[i].nroots; exercise_int(&Tab[i]); } #define u16 unsigned short static __inline__ unsigned long long rdtsc(void) { unsigned hi, lo; __asm__ __volatile__ ("rdtsc" : "=a"(lo), "=d"(hi)); return ( (unsigned long long)lo)|( ((unsigned long long)hi)<<32 ); } int exercise_int(struct etab *e) { int nn = (1<<e->symsize) - 1; data_t block[nn],tblock[nn]; int i; int errors; int derrors,kk; int errval,errloc; int erasures; int decoder_errors = 0; void *rs; /* Compute code parameters */ kk = nn - e->nroots; #define K 2976 #define E e->nroots #define PAD (nn-e->nroots-K) printf("start!\n"); rs=init_rs_int(e->symsize,e->genpoly,e->fcs,e->prim,e->nroots,PAD); if(rs==NULL) { printf("init_rs_int failed!\n"); return -1; } else printf("inited!\n"); unsigned long long t=0; Loop: memset(block,0,sizeof(block)); /* Load block with random data and encode */ for(i=0;i<K;i++)block[i]=((u16)random())&nn; memcpy(tblock,block,sizeof(block)); t=rdtsc(); encode_rs_int(rs,block,&block[K]); t=rdtsc()-t; printf("Encode: %0.1lf FPS ",(double)3000000000ULL/(double)t); //"%llu\n" /* Make temp copy, seed with errors */ memcpy(tblock,block,sizeof(block)); for(int i=0;i<(E/2)+0;i++)tblock[(((u16)rand())%(K+E))]=(u16)rand(); /* Decode the errored block */ t=rdtsc(); derrors=decode_rs_int(rs,tblock,NULL,0); t=rdtsc()-t; printf("Decode: %0.1lf FPS\n",(double)3000000000ULL/(double)t); //"%llu\n" if(memcmp(tblock,block,sizeof(tblock))!=0) { printf("Decode Error!\n"); while(1); } // else printf("All OK!\n"); goto Loop; free_rs_int(rs); return 0; }
-
1 hour ago, des00 said:
так а там же оно аппроксимируется через одноранговое вычитание. ЕМНП все случаи этого остатка связаны с тем что делимое меньше двух делителей.
Вот здесь: https://github.com/quiet/libfec/blob/master/decode_rs.c
остаток от деления на 65535. Нету однорангового вычитания.
Собственно, как сложить два числа с остатком от деления на 65535 ?
тоесть (a+b)%65535 ?
не прибегая к вычислению остатка от деления (в т.ч. и самого деления)
Про виртуальные адреса вопрос (ARM)
в Программирование
Опубликовано · Пожаловаться
Автор статьи на Хабре утверждает, что в разных архитектурах кеш может быть перед MMU или за MMU. Из-за этого универсального ответа на мой вопрос не будет.
Но мне был интересен вопрос в контексте ARM Cortex A7, ответ на него получен.
https://habr.com/ru/articles/211150/