


repstosw
-
Постов
2 582 -
Зарегистрирован
-
Победитель дней
2
Сообщения, опубликованные repstosw
-
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
10 hours ago, _pv said:да вроде имеет право
А меня нервирует, что C++ не любит void main(void). пишет, что main() должен возвращать int. У меня программа постоянно в main() в вечном цикле. Даже освобождение ресурсов не нужно, так как программа работает вечно, пока питание не закончится.
Тут ещё споры разгорелись, по поводу того, если функция не имеет аргументов - надо ли void писать в скобках или нет. Я по всей строгости - пишу void, если нет параметров. Но коллеги не согласны с моим решением - оставляют пустые скобки. Это принципиально - для C, а для C++ ?
-
19 hours ago, jcxz said:
Просто чудный компилятор - даже на отсутствие return в int main() не обратил внимания.

Проверил с -Wall -Wextra -pedantic. Да, действительно пропускает 🤣
17 hours ago, Arlleex said:Тоже объяснимо, но в нынешних реалиях мало соотносится с логикой.
Я полагаю, Вы имели в виду вызов func("string"), где void func(char *str). Проблема в том, что в Си строка (строковый литерал) имеет тип char [] (не char * и не const char *). Поэтому компиляция "перлов" в виде func("string") происходит молча. Ну хоть в C++ это уже не пройдет - там символьная строка имеет тип char const [].
В защищённых режимах всяких это может вылезти боком. Потому что char const* это Read Only. А передача char* подразумевает, что в вызываемой функции может производиться запись в память.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
1 hour ago, Arlleex said:Ну, вернее, написать сможете (только не для CPU с внеочередным исполнением), но результирующий код Вам не понравится совершенно😆
А если я дам гарантии, что ни один обработчик прерывания не работает со спинлоками и с расшаренной памятью?
У меня строго цикл. Только в main() идут операции с SHARED memory. А обработчики прерываний работают в пределах ресурсов управляющего процессора
-
38 minutes ago, jcxz said:
Ну так - не кешировать её. Зачем кешировать расшаренную память, используемую для межъядерного обмена? Выигрыш - копейки (или вообще нет), а проблем сами же себе создаёте вагон.
Что определяет расшаренную память? Мануал на контроллер или бит SHARED в MMU ? Вопрос в контексте Cortex A7. Конкретнее T113-s3.
В мануале перечислены адреса памяти. Некоторые адреса подключены к Internal Bus DSP, от того и быстрые. Может ли она быть SHARED? Для ARM CPU
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
On 10/18/2023 at 1:21 AM, Сергей Борщ said:int volatile * volatile pd; // volatile-указатель на volatile-int
Шедевр! Никогда не встречал такой конструкции.
On 10/18/2023 at 10:50 PM, jcxz said:Или (в качестве shared memory) использовать внутреннюю ОЗУ. Доступную всем ядрам. Без всяких кешей.
У Allwinner можно закешировать SRAM A1 и не только. И она быстрее работает. Хотя по логике вещей скорость не должна была измениться (как у того же TMS320C6745)
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
Вот есть ещё такие - софтовые спинлоки для камней Allwinner: https://github.com/uli/allwinner-bare-metal/blob/master/spinlock.c
 38 minutes ago, Arlleex said:
38 minutes ago, Arlleex said:Да, спинлоки реализуются на инструкциях атомарного доступа CPU
Так а где эта атомарность полезна? Допустим во время операции спинлока произошло прерывание. Почему это может быть нежелательно?
P.S. Вопрос-оффтопик: как запретить прерывания на уровне ядра Xtensa?
Пока делаю так, но хочется более атомарнее:
static inline void CLI(void) //disable all interrupt levels { u32 i; __asm__ __volatile__ ("rsr.ps %0" : "=r"(i)); i|=0xF; __asm__ __volatile__ ("wsr.ps %0" :: "r"(i)); __asm__ __volatile__ ("rsync"); } static inline void STI(void) //enable all interrupt levels { u32 i; __asm__ __volatile__ ("rsr.ps %0" : "=r"(i)); i&=~0xF; __asm__ __volatile__ ("wsr.ps %0" :: "r"(i)); __asm__ __volatile__ ("rsync"); }
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
36 minutes ago, repstosw said:Получилась немного инверсная логика работы, но на практике тот результат, что мне нужен.
Переделал на прямую логику. Тоже работает:
CPU0:
void FEC_Init(u8 mln) { SPINLOCK_ENABLE(); //разрешение и сброс спинлоков. Все спинлоки свободны -начальное состояние printf("T113-s3 FEC\n"); }
CPU1 Декодер:
void FEC_Decode(void) { if(SPINLOCK_STATUS&(1<<1)) //если спинлок 1 занят { cache_inv_range((u32)RSD,((u32)RSD)+Bsize); memcpy(DecodeBuf,RSD,Fsize); memcpy(&DecodeBuf[KK],&RSD[Fsize>>1],EE<<1); int r=eras_dec_rs(DecodeBuf,NULL,0); //декодирование if(r==-1)printf("Decode Error\n"); else if(r>0) { memcpy(RSD,DecodeBuf,Fsize); memcpy(&RSD[Fsize>>1],&DecodeBuf[KK],EE<<1); cache_flush_range((u32)RSD,((u32)RSD)+Bsize); } SPINLOCK_LOCK(1)=0; //освобождаем спинлок 1 } }
DSP - команда декодеру (CPU1):
void FEC_Decode(u16 *buf) { while(SPINLOCK_STATUS&(1<<1)); //ждём пока спинлок занят memcpy(DecodeBuf,buf,Bsize); xthal_dcache_region_invalidate(RSD,Bsize); memcpy(buf,RSD,Bsize); memcpy(RSD,DecodeBuf,Bsize); xthal_dcache_region_writeback(RSD,Bsize); while(SPINLOCK_LOCK(1)); //захват спинлока 1 }
-
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
Наконец-то удалось заставить работать спинлоки, как нужно для моего алгоритма. Как всегда, в даташите пример программы с опечатками. Мне эта картинка дала 100% понимание о работе спинлоков:
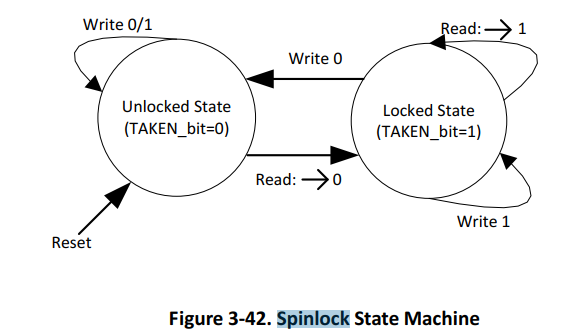
CPU0, инициализация кодера и декодера:
void FEC_Init(u8 mln) { SPINLOCK_ENABLE(); //разрешение и сброс спинлоков while(SPINLOCK_LOCK(0)); //захват спинлока 0 (кодер) while(SPINLOCK_LOCK(1)); //захват спинлока 1 (декодер) printf("T113-s3 FEC\n"); }
CPU0 - кодер:
void FEC_Encode(void) { if(!(SPINLOCK_STATUS&(1<<0))) //если спинлок 0 свободен { cache_inv_range((u32)RSC,((u32)RSC)+Fsize); memcpy(EncodeBuf,RSC,Fsize); encode_rs(EncodeBuf); //собственно кодирование memcpy(&RSC[Fsize>>1],&EncodeBuf[KK],EE<<1); cache_flush_range((u32)&RSC[Fsize>>1],((u32)&RSC[Fsize>>1])+(EE<<1)); while(SPINLOCK_LOCK(0)); //захват спинлока 0 (для DSP, индикатор того, что данные закодированы и готовы) } }
DSP - кодер (даёт команду для CPU0):
void FEC_Encode(u16 *buf) { while(!(SPINLOCK_STATUS&(1<<0))); //ждём, пока спинлок 0 свободен memcpy(EncodeBuf,buf,Fsize); //сохраняем текущий не закодированный буфер xthal_dcache_region_invalidate(RSC,Bsize); memcpy(buf,RSC,Bsize); //копируем результат предыдущей итерации memcpy(RSC,EncodeBuf,Fsize); //загружаем данные для CPU0 - новая итерация xthal_dcache_region_writeback(RSC,Fsize); SPINLOCK_LOCK(0)=0; //освобождаем спинлок 0 (запуск CPU0) }
Хедер:
#define SPINLOCK_BASE 0x03005000 #define SPINLOCK_STATUS (*(IO u32*)(SPINLOCK_BASE+0x010)) #define SPINLOCK_LOCK(N) (*(IO u32*)(SPINLOCK_BASE+((N)<<2)+0x100)) #define SPINLOCK_ENABLE() \ { \ SPINLOCK_BGR_REG&=~(1<<16); /* assert reset */ \ SPINLOCK_BGR_REG|=1; /* gating pass */ \ SPINLOCK_BGR_REG|=(1<<16); /* de-assert reset */ \ } \
Получилась немного инверсная логика работы, но на практике тот результат, что мне нужен.
И всё-же мне непонятно, чем эти спинлоки лучше, чем волатильные некешируемые флаги. Именно в моём примере. Атомарность? Вроде - нет, запись в регистр никогда не атомарна. И немного выглядит странной логика захвата спинлока - чтением регистра. Обычно статус-флаги записываются и потом читаются. А тут непривычно.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
33 minutes ago, sasamy said:если от msgbox прерывания DSP 3,4 полагаю от спинлоков где-то рядом, для арма номер в таблице есть
Вы слишком усложняете всё. Не нужны мне прерывания от спинлоков. Мне достаточно в нужное премя прочесть его состояние, что свободен.
Потому что дизайн полностью синхронный: 1 итерация цикла main = 1 итерация кодирования = 1 итерация декодирования.
33 minutes ago, sasamy said:интересно посмотреть как с флагом в памяти можно сделать такое и не накручивать бесполезные циклы ожидания
Что значит "бесполезные циклы ожидания"? Если данные не готовы, то по любому нужно будет ждать. В моём случае кодер-декодер отрабатывают быстрее, чем итерация цикла в main.
И запускаются кодер-декодер синхронно. А это значит, что к следующей итерации цикла- кодер и декодер будут гарантированно свободны, и не нужно будет ожидать их освобождения.
В общем, я думаю, что спинлоки здесь не подойдут. Потому что мне не нужно лочить DSP, пока CPU считает данные.
Кроме того, мне не понятна сама реализация спинлоков. Есть пара регистров - STATUS и LOCK. Первый проверяет занят ли спинлок. Чтение второго приводит к захвату, =0 если захват успешен. Запись в него нуля освобождает спинлок. Теперь как это соотнести к функциям CPU и DSP?
Что первично? Если в цикле CPU сделать захват спинлока, затем произвести манипуляции с памятью, затем освободить спинлок, то CPU входит в бесконечный цикл - эти действия (захват- работа - освобождение) делаются бесконечно.
#define SPINLOCK_STATUS (*(IO u32*)(SPINLOCK_BASE+0x010)) #define SPINLOCK_LOCK(N) (*(IO u32*)(SPINLOCK_BASE+((N)<<2)+0x100)) #define CHECK_SPINLOCK_STATUS(N) while(SPINLOCK_STATUS&(1UL<<(N))) #define CHECK_SPINLOCK_LOCK(N) while(SPINLOCK_LOCK(N)) #define SPINLOCK_FREE(N) SPINLOCK_LOCK(N)=0 void FEC_Encode(void) { while(1) { CHECK_SPINLOCK_STATUS(0); CHECK_SPINLOCK_LOCK(0); shared_memory_read(); encode_rs(shared_memory); shared_memory_write(); SPINLOCK_FREE(0); } }
А мне надо, чтобы DSP пинал CPU когда нужно.
В общем нестыковка с этими спинлоками. И не уверен, что в моём контексте они точно подходят.
C флагами намного прозрачнее: CPU ждёт флаг=0. DSP производит действия с памятью и выставляет флаг=0. CPU увидев что флаг=0 начинает кодирование. В конце CPU выставляет флаг =1 и снова ждёт пока DSP не скинет его в 0. DSP в следующей итерации видит флаг =1, готовит новые данные/забирает старые и снова выставляет флаг =0 для CPU. CPU ждал флага=0 и дождался: новая итерация кодирования. А со спинлоками как??
От CPU требуется только считать кодер. Более он не нужен.
void main_secondary(void) //CPU1 - decode { LowLevel_Init(); while(1)FEC_Decode(); //decode cycles (when DSP set flag_decode=0) } void main(void) //CPU0 { LowLevel_Init(); FEC_Init(); //init codec CPU1_Run(main_secondary); //Run CPU1 - decoder sunxi_dsp_init(DSPimage,sizeof(DSPimage)); //Run DSP - main while(1)FEC_Encode(); //encode cycles (when DSP set flag_encode=0) }
P.S. Кстати, проблема этого топика решена. Была некорректная работа с кешем после сброса:
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
1 hour ago, sasamy said:прочтите мануал - у спинлока как раз такая семантика, одно ядро прочитало 0 значит блокировка захвачена и можно выполнять код над шареным буфером, а второе будет читать 1 и накручивать циклы ожидания 0, первое ядро закончило работу и пишет в спинлок 0 освобождая его, второе читает 0 захватывает блокировку и начинает свою работу над шареными данными, первое ядро при попытке получить блокировку будет читать 1 и накручивать циклы ожидания 0, и так по очереди.
Читаю сейчас соответствующую главу в мануале. Я не вижу отличий между спинлоком и некешируемым волатильным флагом в памяти. В чём преимущества спинлоков перед волатильными флагами?
Когда работал с TMS320C6745, то синхронизировал их без спинлоков, всё работало.
Ниже попытался объяснить, что в конечном итоге мне надо.
Со стороны CPU - код кодера. Данные во время работы гарантированно не используются другими ядрами:
while(1) //вечный цикл, более ничего не делаем { if(coder_flag==0) //DSP дал команду запустить кодер и произвести чтение-запись данных { read_data(); //читаем SHARED данные : входные code(); //проводим вычисления write_data(); //записываем в SHARED данные : выходные barrier(); //барьер компилятору coder_flag=1; // готово! флаг для DSP } }
Cо стороны DSP - управляющий:
main() { init_all(); // инит всего и вся while(1) //вечный цикл { do_something(); //что-то делаем encode_to_cpu(); //даём команду на запуск кодера для CPU do_something2(); //что-то другое делаем } } void encode_to_cpu() { while(!coder_flag); //CPU свободен? если нет, то ждём (на самом деле этот цикл быстро завершается, //так как длительность итерации цикла главной программы - больше, чем время кодирования CPU) read_data(); //читаем SHARED данные - CPU отработал и дал нам данные предыдущей итерации write_data(); //записываем новые данные SHARED для CPU barrier(); //барьер компилятору coder_flag=0; //запускаем команду для CPU (кодер) - для новой итерации }
В чём преимущества использования здесь спинлоков вместо coder_flag ?
-
53 minutes ago, mantech said:
Да уж, странно, после повторного перезапуска оно понятно, как перевод управления из бутлоадера в осн. программу, но после аппаратного сброса...
Такое впечатление, что аппаратный сброс != сброс ДСП)))
Так в асмовском стартап-коде для Cortex A7 также запрещаются кеши и проводятся инвалидации.
Entry: MRC p15, 0, r0, c1, c0, 0 @ Read CP15 System Control register BIC r0, r0, #(0x1 << 12) @ Clear I bit 12 to disable I Cache BIC r0, r0, #(0x1 << 2) @ Clear C bit 2 to disable D Cache BIC r0, r0, #0x1 @ Clear M bit 0 to disable MMU BIC r0, r0, #(0x1 << 11) @ Clear Z bit 11 to disable branch prediction MCR p15, 0, r0, c1, c0, 0 @ Write value back to CP15 System Control register MOV r0,#0 MCR p15, 0, r0, c8, c7, 0 @ I-TLB and D-TLB invalidation MCR p15, 0, r0, c7, c5, 6 @ BPIALL - Invalidate entire branch predictor array
Вопрос в том, как это правильно сделать для DSP и желательно - с особой педантичностью, чтобы в любых случаях положительный результат был 100%.
-
1 hour ago, sasamy said:
аппаратный спинлок пробовали или капризный DSP мешает ? в мануале по шагам алгоритм расписан как обращаться к общим данным с двух ядер с поллингом спинлока
А вы точно уверены, что он для моих целей подойдёт?
Мне нужен аппаратный флаг, который оба ядра могли бы читать и писать, чтобы знать, что один работу завершил - и можно забрать данные, и потом снова пнуть чтобы работал с новыми данными.
Семафор нужен.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
3 hours ago, repstosw said:HiFi4 DSP не сбрасывается вместе с CPU 0/1 при нажатии кнопки RESET. Результат непредсказуем: после сброса DSP либо улетает в экспешн, либо работает.
Вопрос решён.
Проблема была в повторной инициализации регионов кеширования, которая приводила к эксепшену. В функции _cache_config :
https://github.com/YuzukiHD/FreeRTOS-HIFI4-DSP/blob/master/arch/board-init.c#L11
Для повторных вызовов (при нажатии кнопки RESET на плате с T113-s3) нужно сделать инвалидацию кешей:
#include "hal.h" static void _cache_config(void) { //для корректной работы DSP после сброса T113-s3 xthal_icache_all_invalidate(); xthal_dcache_all_invalidate(); /* 0x0~0x20000000-1 is non-cacheable */ xthal_set_region_attribute((void *)0x00000000, 0x20000000, XCHAL_CA_WRITEBACK,0); xthal_set_region_attribute((void *)0x00000000, 0x20000000, XCHAL_CA_BYPASS, 0); //...
По-хорошему, после сброса надо запрещать кеширование и отключать предвыборку(prefetch) и сбрасывать конвеер. Чтобы потом снова разрешать всё.
Вариант-минимум выше работает.
-
16 minutes ago, mantech said:
А если это делать на CPU, все норм?
На CPU всё давно отлажено и отлично работает при любых условиях. Проблема с DSP: слишком капризная архитектура.
-
Just now, mantech said:
то делать через память, а не фифо всякие, ИМХО...
Читать пробовали? 🤣
Где вы здесь FIFO увидели?
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
HiFi4 DSP не сбрасывается вместе с CPU 0/1 при нажатии кнопки RESET. Результат непредсказуем: после сброса DSP либо улетает в экспешн, либо работает.
Запись в регистр DSP_ALT_RESET_VEC_REG не приводит к положительному результату.
Вопрос: как остановить DSP?
Код для запуска DSP в спойлере:
Spoilervoid sunxi_dsp_init(const void *img_addr,u32 img_size) { sram_remap_set(1); //set system boot use local ram dsp_freq_default_set(); //clock gating u32 reg_val=readl_dsp(CCU_BASE+CCMU_DSP_BGR_REG); reg_val|=(1<<BIT_DSP0_CFG_GATING); writel_dsp(reg_val,CCU_BASE+CCMU_DSP_BGR_REG); //reset reg_val=readl_dsp(CCU_BASE+CCMU_DSP_BGR_REG); reg_val|=(1<<BIT_DSP0_CFG_RST); reg_val|=(1<<BIT_DSP0_DBG_RST); writel_dsp(reg_val,CCU_BASE+CCMU_DSP_BGR_REG); writel_dsp(DSP0_START_ADDRESS,DSP0_CFG_BASE+DSP_ALT_RESET_VEC_REG); reg_val=readl_dsp(DSP0_CFG_BASE+DSP_CTRL_REG0); reg_val|=(1<<BIT_START_VEC_SEL); writel_dsp(reg_val,DSP0_CFG_BASE+DSP_CTRL_REG0); sunxi_dsp_set_runstall(1); //set runstall //set dsp clken reg_val=readl_dsp(DSP0_CFG_BASE+DSP_CTRL_REG0); reg_val|=(1<<BIT_DSP_CLKEN); writel_dsp(reg_val,DSP0_CFG_BASE+DSP_CTRL_REG0); //de-assert dsp0 reg_val=readl_dsp(CCU_BASE+CCMU_DSP_BGR_REG); reg_val|=(1<<BIT_DSP0_RST); writel_dsp(reg_val,CCU_BASE+CCMU_DSP_BGR_REG); load_image(img_addr,img_size); //load image to ram sram_remap_set(0); //set dsp use local ram sunxi_dsp_set_runstall(0); //clear runstall }
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
Распределил задачи на три ядра:
1. CPU0 - инит периферии, загрузка задачи в CPU1 и DSP, кодер Рида-Соломона
2. CPU1 - декодер Рида-Соломона
3. DSP - управляющая программа + всё остальное.
Основная проблема: при подаче питания на плату - кодер Рида-Соломона на CPU0 возвращает правильнные данные, но DSP при приёме этих данных пакета из эфира с помощью приёмника (трансивер Si4463) - возвращает мусор в проверочных символах. При этом сам пакет приходит правильный. Проблема именно в проверочных символах.
Если же сделать сброс (нажать кнопку RESET на плате MangoPi - allwinner T113-s3), то проверочные символы верны. И после каждого сброса - данные верны. Проблема возникает только при подаче питания.
Взаимодействие CPU0,CPU1 с DSP : управление - через волатильный флаг, слово в памяти - регион не кеширован, не буферизован, SHARED=1. Данные - пара буферов - для кодера и декодера. Кешированы, буферизованы, SHARED=1.
#define FEC_CODER_DATA 0xC7D00000 //адрес буфера кодера (кеширован) #define FEC_DECODER_DATA 0xC7D80000 //адрес буфера декодера (кеширован) #define FEC_CODER_CONTROL 0x47E00000 //контроль кодера (не кеширован) #define FEC_DECODER_CONTROL 0x47E80000 //контроль декодера (не кеширован) #define rsc (*(IO u32*)FEC_CODER_CONTROL) #define rsd (*(IO u32*)FEC_DECODER_CONTROL)
Процедура запуска кодирования со стороны DSP - buf - входной и выходной буфер. Для простоты - приведен пример синхронной работы кодера (вынуждающий ждать его завершения работы, что сводит "на нет" преимущества многоядерности, но зато более понятен). Есть и асинхронный режим - когда возвращается закодированное содержимое с предыдущей итерации, а даётся команда на кодирование новых данных - без ожидания.
static dtype *RSC=(dtype*)FEC_CODER_DATA; static dtype *RSD=(dtype*)FEC_DECODER_DATA; void FEC_Encode(u16 *buf) { memcpy(RSC,buf,Fsize); __asm__ __volatile__ ("" ::: "memory"); xthal_dcache_region_writeback(RSC,Fsize); __asm__ __volatile__ ("" ::: "memory"); rsc=0; __asm__ __volatile__ ("" ::: "memory"); while(!rsc); __asm__ __volatile__ ("" ::: "memory"); xthal_dcache_region_invalidate(&RSC[Fsize>>1],EE<<1); __asm__ __volatile__ ("" ::: "memory"); memcpy(&buf[Fsize>>1],&RSC[Fsize>>1],EE<<1); }
Процедура кодирования со стороны CPU0:
void FEC_Encode(void) { if(!rsc) { cache_inv_range((u32)RSC,((u32)RSC)+Fsize); __asm__ __volatile__ ("" ::: "memory"); memcpy(EncodeBuf,RSC,Fsize); __asm__ __volatile__ ("" ::: "memory"); encode_rs(EncodeBuf); memcpy(&RSC[Fsize>>1],&EncodeBuf[KK],EE<<1); __asm__ __volatile__ ("" ::: "memory"); cache_flush_range((u32)&RSC[Fsize>>1],((u32)&RSC[Fsize>>1])+(EE<<1)); __asm__ __volatile__ ("" ::: "memory"); rsc=1; } }
При приёме вместо содержимого проверочных символов:
memcpy(&RSC[Fsize>>1],&EncodeBuf[KK],EE<<1);
Прилетает мусор (при каждом новом включении - разный). При этом проверял пакет данных : перед передачей, во время передачи, после передачи - он правильный. Проблема при приёме - проверочные символы битые. При сбросе проблема уходит.
Если же сделать кодирование на одном ядре - средствами DSP, то проблема не возникает:
void FEC_Encode(u16 *buf) { memcpy(EncodeBuf,buf,Fsize); encode_rs(EncodeBuf); memcpy(&buf[Fsize>>1],&EncodeBuf[KK],EE<<1); }
Настройка MMU CPU0,1 для "регистров" rsc/rsd (управление):
mmu_tlb_address[i + (dram_base>>20)] = (dram_base + (i << 20)) | (0 << 19) | (0 << 18) | (0 << 17) | (1 << 16) | //SHARED (0 << 15) | (0 << 12) | //TEX (3 << 10) | (0 << 9) | (15 << 5) | (0 << 4) | (0 << 3) | //Cacheble (0 << 2) | //Bufferable (2 << 0);
Настройка MMU для буферов:
mmu_tlb_address[i + (dram_base>>20)] = (dram_base + (i << 20)) | (0 << 19) | (0 << 18) | (0 << 17) | (1 << 16) | //SHARED (0 << 15) | (0 << 12) | //TEX (3 << 10) | (0 << 9) | (15 << 5) | (0 << 4) | (1 << 3) | //Cachable (1 << 2) | //Bufferable (2 << 0);
В чём может быть проблема?
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
1 hour ago, Arlleex said:u32 volatile *p = (какой-то адрес); // указатель на volatile: например, периферийный регистр u32 *volatile p = (какой-то адрес); // вот этот вот "какой-то адрес" нельзя оптимизировать; например, ISR "двигает" позиции программного FIFO
Какой из ваших двух примеров будет означать буфер с изменчивыми данными? Нужен буфер с volatile-содержимым. Статический массив не подходит, потому что длина может меняться.
Указатель на массив - тоже не годится : потому что надо указывать размер:
char (*mem)[256];
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
5 hours ago, sasamy said:вообще не очень понятно как вам может подойти ядро которое считает в несколько раз медленней судя по вашим тестам и при этом вы будете поллить результат на более быстром ядре. В чём смысл ? Я бы ещё понял что считается параллельно пока CPU что-то делает другое полезное и прерывается по готовности результата аппаратно.
ARM CPU 0 - кодер Рида-Соломона. 34 FPS
ARM CPU 1 - декодер Рида-Соломона 15 FPS
HiFI4 DSP - главная программа + JPEG encoder/decoder(аппаратно), CELT coder/decoder (софтово), эхоподавитель(софтово), G2D(аппаратно), захват с камеры(аппаратно), ADC/DAC(аппаратно).
Сделал HiFi4 DSP главным, потому что Рида-Соломона он не вывозит на 12 FPS. Зато на остальное его хватает. Нужно одновременно кодирование и декодирование на 12..15 FPS.
34 FPS + 15 FPS = 10.4 FPS < 12..15 FPS
Итого: все ТРИ ядра активны.
5 hours ago, Сергей Борщ said:Имя массива не может быть volatile. Как и имя любой другой переменной. Оно имя. volatile относится к содержимому переменной/массива.
А если указатель volatile? Что в этом случае что изменчиво - само значение указателя (адрес) или содержимое памяти (при разыменовывании) , на которое указывает этот указатель?
5 hours ago, sasamy said:Кстати а сброс кеша по вашему мгновенный ?
Quotecache_flush_range((u32)RSC,((u32)RSC)+fsize);
или это другое 🙂
И сколько времени надо ждать, прежде чем другое ядро сможет обращаться к этим данным?
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
9 hours ago, Сергей Борщ said:Если сам указатель не меняется - ему совершенно незачем быть volatile. Он должен быть указателем на volatile. Вы бы показали его объявление, тогда вам бы посоветовали правильный вариант.
#define FEC_CODER_CONTROL 0x47E00000 //контроль кодера (не кеширован) #define rsc (*(volatile unsigned int*)FEC_CODER_CONTROL) #define FEC_CODER_DATA 0xC7D00000 //адрес буфера кодера (кеширован) volatile dtype *RSC=(volatile unsigned short*)FEC_CODER_DATA;
9 hours ago, Сергей Борщ said:volatile int a1[10]; int volatile a2[10]; // эти два объявления эквивалентны, выбирайте по вкусу.
Это точно, что в этих случаях каждый элемент массива будет volatile? Или только имя массива?
9 hours ago, jcxz said:Тривиальное приведение типа спасёт предводителя дворянства и отца демократии от козней mamcpy.

Так и сделал.
10 hours ago, sasamy said:опять поллинг 🙂 там ведь есть аппапртные спинлоки с генерацией прерываний
В настоящий момент не до конца раскурил эти спинлоки.
Они тормозят ядро? Тогда не подходит. То, что флаг установился/сбросился, это ещё недостаточно, чтобы тормозить ядро. Потому что оно кроме этого ещё некоторые вещи делает.
8 hours ago, amaora said:В многопроцессорной системе барьеры вероятно посложнее делаются, здесь только для компилятора указания.
Для компилятора и предназначалось. Чтобы не переставил местами несвязанные между собой конструкции.
Для DSP барьер памяти : memw, для CPU - инструкция DSB
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
2 hours ago, vov4ick said:extern volatile ?
vloatile сделал. Но это указатель. И ещё когда mamcpy, memset, то требует убрать volatile.
Как сделать массив volatile? Чтобы компилятор имел ввиду - каждый элемент массива может быть volatile.
Ну ещё и барьер памяти, потому что важна последовательность действий - вызов encode_rs() не раньше инвалидации и не позже flush. rsc=1 - в самом конце - это флаг другому ядру:
void FEC_Encode(void) { if(rsc==0) { cache_inv_range((u32)RSC,((u32)RSC)+fsize); __asm__ __volatile__ ("" ::: "memory"); encode_rs(RSC); __asm__ __volatile__ ("" ::: "memory"); cache_flush_range((u32)RSC,((u32)RSC)+fsize); __asm__ __volatile__ ("" ::: "memory"); UART_putc('^'); __asm__ __volatile__ ("" ::: "memory"); rsc=1; //ready flag for first CPU } }
rsc - это некешируемая ячейка памяти, хранящая флаг - volatile : оба ядра могут её читать-писать. RSC - указатель на буфер данных, тоже volatile.
-
Опубликовано · Изменено пользователем repstosw · Пожаловаться
Пишу задачу для второго ядра. Кодер Рида-Соломона. Данные в буфере. Они читаются в задаче, далее производятся манипуляции с данными, и они обратно читаются в тот же буфер.
Эти данные использует другой процессор. Ядро другой архитектуры, не как архитектура первого ядра. И компилятор уже другой.
На оптимизации -Ofast, компилятор выкидывает процедуру обработки данных. Справедливо полагая, что результат вычислений нигде не используется.
Выкидывается функция encode_rs(RSC);
void FEC_Encode(void) { if(rsc==0) { cache_inv_range((u32)RSC,((u32)RSC)+fsize); encode_rs(RSC); cache_flush_range((u32)RSC,((u32)RSC)+fsize); UART_putc('^'); rsc=1; //ready flag for first CPU } }
Вопрос, как сделать так, чтобы код не выкидывался и выполнялся?
Вариант вывести результат функции через printf() - не рассматривается.
-
Собственно, для чего?
flush dcache - понятно. Скинуть с кеша данных в память. Чтобы DMA или периферал какой-нибудь прочитал правильные данные, подготовленные CPU
invalidate dcache - понятно. Объявить кеш данных недостоверным. Чтобы CPU прочёл корректные данные, после того как периферал или DMA записали в память данные/
invalidate icache - тоже понятно. Объявить кеш инструкций недостоверным. Для самомодифицирующегося кода: если мы записали байт-код какой-нибудь функции в память и её нужно выполнить.
А flush icache - зачем? Какова практическая цель его применения? Сбросить кеш кода в память. Для чего?
Allwinner T113-s3 уделал HiFi4 DSP. Смеяться или плакать?
в TI, Allwinner, GigaDevice, Nordic, Espressif и другие
Опубликовано · Изменено пользователем repstosw · Пожаловаться
Как-то понадобилось мне сделать задержки через DSP-таймер. В board_init.c есть такая функция: uint64_t xbsp_get_ccount(void). Задержку решил сделать так:
Не работает xbsp_get_ccount(): https://github.com/YuzukiHD/FreeRTOS-HIFI4-DSP/blob/master/arch/board-init.c#L130
Если использовать 32-битный таймер без учёта переполнения, то он переполнится через 7,15 секунд, что неприемлемо.
64 бита уже дадут переполнение через 355 839 cуток.
Сделал так: