des00
-
Постов
9 579 -
Зарегистрирован
-
Победитель дней
4
Весь контент des00
-
Вопросы по итеративному декодированию
des00 ответил des00 тема в Алгоритмы ЦОС (DSP)
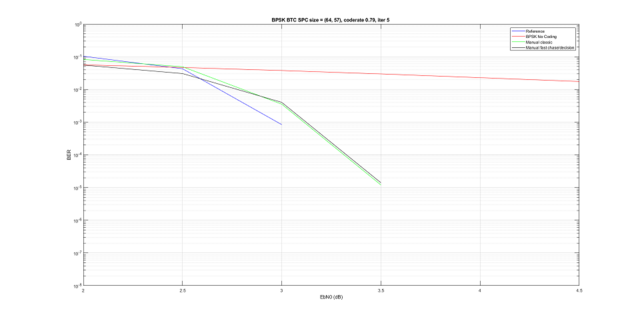
Провел еще некоторе время над кодом: 1. Методом игры с коэффициентами, изучением логов и логикой здравого смысла подобрал коэффииценты альфа и бета такие, что самописный код стал близок к референсному. Действительно тонкое место, шаг влево-вправо влияет довольно таки сильно 2. Нашел у себя ошибку в быстром чейзе с быстрым решением (без поиска), вы будете смеяться, но....это работает. И работает как в статье, вот результат Да, результат хуже, но не так катастрофично, причем чем больше итераций тем результаты ближе. Кому интересно покрутить, проверить мой код, пример в атаче hamming.zip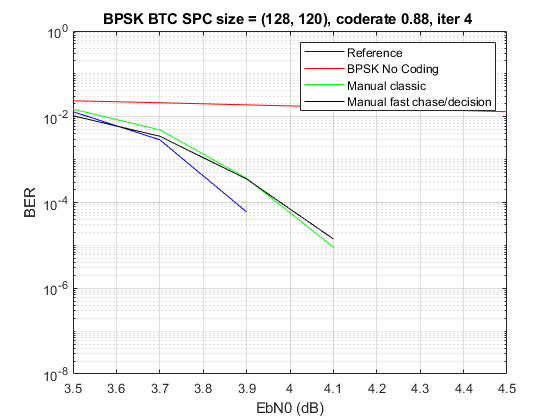
-
Вопросы по итеративному декодированию
des00 ответил des00 тема в Алгоритмы ЦОС (DSP)
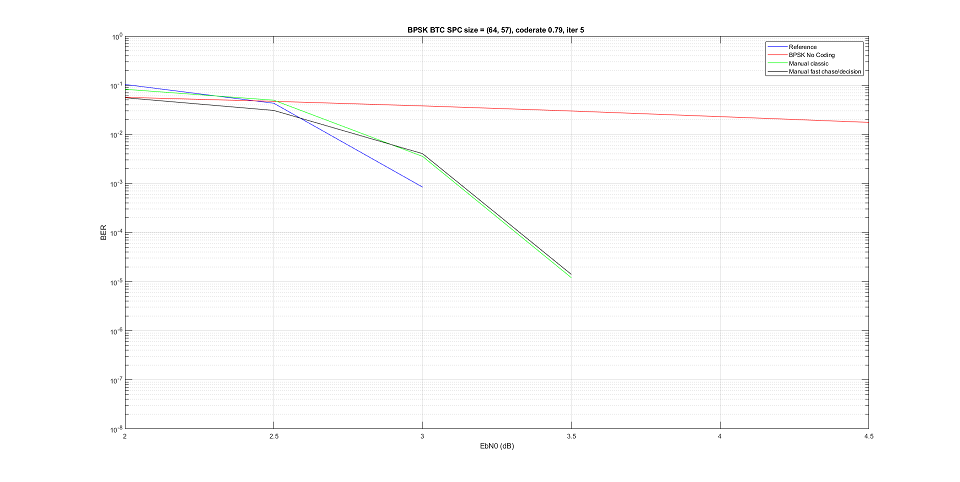
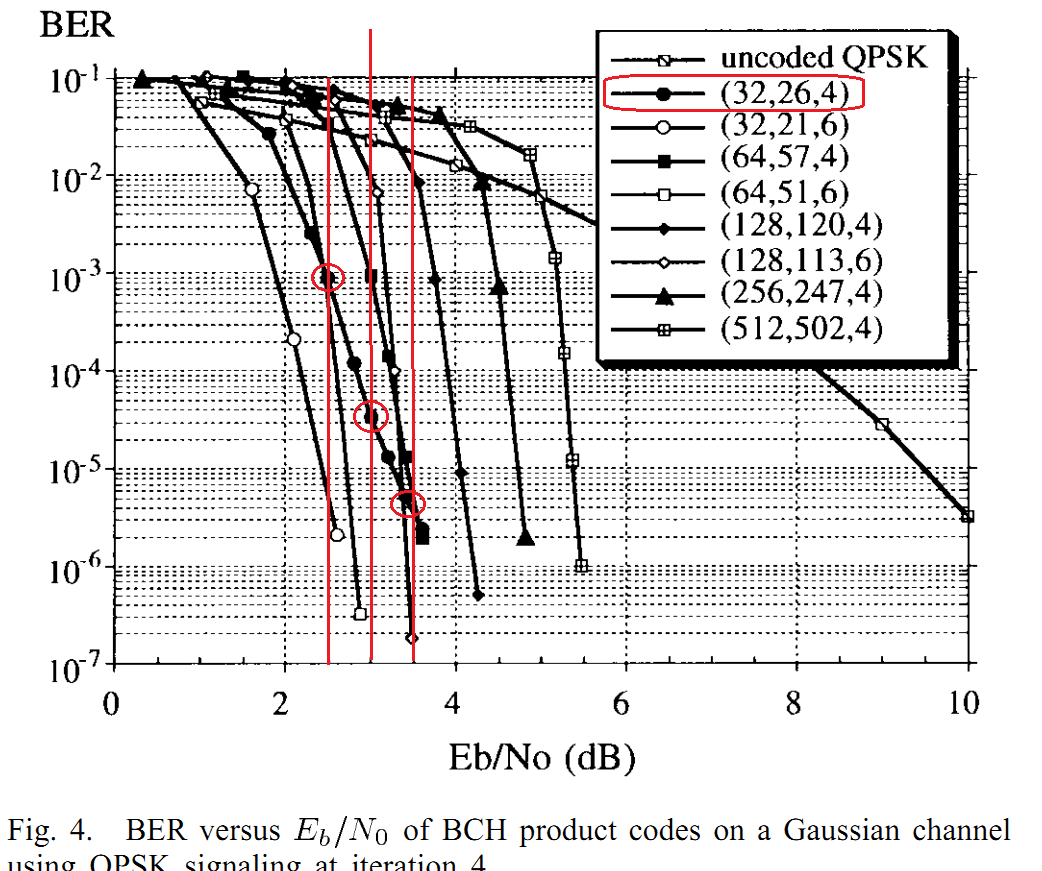
Поднимем тему. Итак дано: BTC коды из Wimax на основе расширенных кодов хэмминга. Реализация по статье Near-Optimum Decoding of Product Codes: Block Turbo Codes Ramesh Mahendra Pyndiah, Member, IEEE. Все понятно, все получилось, но есть нюанс, вокруг которого хожу уже какой день и не могу продвинуться. Поэтому прошу помощи. В атаче лежат сорцы этого кодека на м-языке и приведент тест: сравнивается BER у встроенной функции tpcdec и самописной для кода (32, 26, 4)^2. Судя по хелпу, tpcdec реализован аналогично указаной статье. Но есть ньюанс, вот эталонные кривые, приводимые автором для кода из теста результат на 2.5/3.0/3.5 дб составляет ~1e-3/5e-5/5e-6. Теперь берем результат теста, для 1е6 информационных битов (достоверное измерение где то до 1е-5, но этого достаточно) done EbN0(EsN0/SNR) = 2.00(0.20/3.21) ber = 1.16e-02 vs 2.75e-02 at ch ber = 7.43e-02 done EbN0(EsN0/SNR) = 2.50(0.70/3.71) ber = 5.55e-04 vs 3.21e-03 at ch ber = 6.29e-02 done EbN0(EsN0/SNR) = 3.00(1.20/4.21) ber = 0.00e+00 vs 7.80e-05 at ch ber = 5.18e-02 done EbN0(EsN0/SNR) = 3.50(1.70/4.71) ber = 0.00e+00 vs 0.00e+00 at ch ber = 4.26e-02 собственная реализация довольно близко идет к той что в статье, но вот tpcdec на 0.5дб ее обходит, хотя судя по хелпу она аналогична. Собственно вопросы: 1. Посмотрите код, все ли я правильно сделал с 2D турбобалалайкой, может глаз уже замылися? 2. что такого сделано в функции tpcdec что она обходит родителя на целых 0.5дб? Спасибо ЗЫ. Если взять 1е7 бит, то результат аналогичен, 0.5 дб выигрыш реализации tpcdec done EbN0(EsN0/SNR) = 2.00(0.20/3.21) ber = 1.16e-02 vs 2.75e-02 at ch ber = 7.41e-02 done EbN0(EsN0/SNR) = 2.50(0.70/3.71) ber = 6.78e-04 vs 3.71e-03 at ch ber = 6.30e-02 done EbN0(EsN0/SNR) = 3.00(1.20/4.21) ber = 9.00e-06 vs 1.81e-04 at ch ber = 5.23e-02 done EbN0(EsN0/SNR) = 3.50(1.70/4.71) ber = 0.00e+00 vs 0.00e+00 at ch ber = 4.27e-02 BTC_wimax.zip Near-Optimum Decoding of Product Codes. Block Turbo Codes.pdf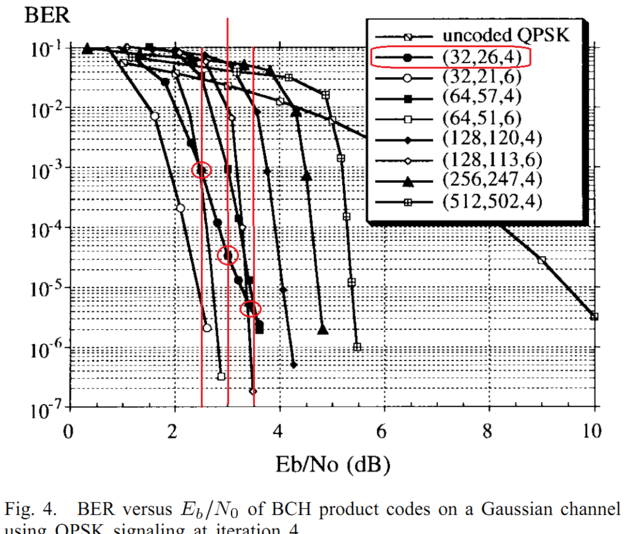
-
я может быть скажу глупость, но MT47H64M16 это DDR2, у которой всегда было 8 банков, а на скрине у вас корка SDRAM controller, не DDR2 sdram contoller. В examples там видно PC100 что было стандартом SDRAM памяти) А у SDRAM максимум всегда был 4 банка)
-
ИМХО, bank machines != ram bank, это фича что бы реализовать SDRAM command out-of-ordrer execution. А именно запаралеллить работу команд открытия и закрытия банка. Больше 4-х не имеет смысла. 3 оптимально, 2 гораздо лучше чем один) А памяти у вас как было, так и останется, потому что отображение BA[] на биты адреса не меняется)