Lixlex
-
Постов
52 -
Зарегистрирован
-
Посещение
Весь контент Lixlex
-
Здравствуйте. Во сколько примерно обойдется производство мелкой партии (100-500 шт) подобных велофонарей? Только механические части, без электроники.
.thumb.jpg.780e93313383270b40237636cde9f7b4.jpg)
-
Arria 10 & EMI
Lixlex ответил Novi4ok тема в Работаем с ПЛИС, области применения, выбор
Был ли у кого опыт симуляции DDR4 EMIF ядра? Запустил тестбенч из example design, есть несколько вопросов. 1. Согласно таблице из ug-20115.pdf для 4х-рангового модуля цикл симуляции составляет 1 день. Опция skip calibration значительно сократить время симуляции не помогла, симулируется по прежнему в районе суток. Как получить заявленные ~25минут? 2. Во время симуляции линии DQ, DQS/DQS_n на временных диаграммах ModelSim постоянно в Z-состоянии. Однако тесты проходят, в логах появляются записанные/прочитанные данные. Как вообще такие чудеса возможны? 3. Был ли у кого-нибудь опыт использования Verilog-модели памяти Micron? Хотелось бы заменить интеловскую модель на микроновскую. https://www.micron.com/products/dram/ddr4-sdram/part-catalog/mt40a256m16ge-083e-aut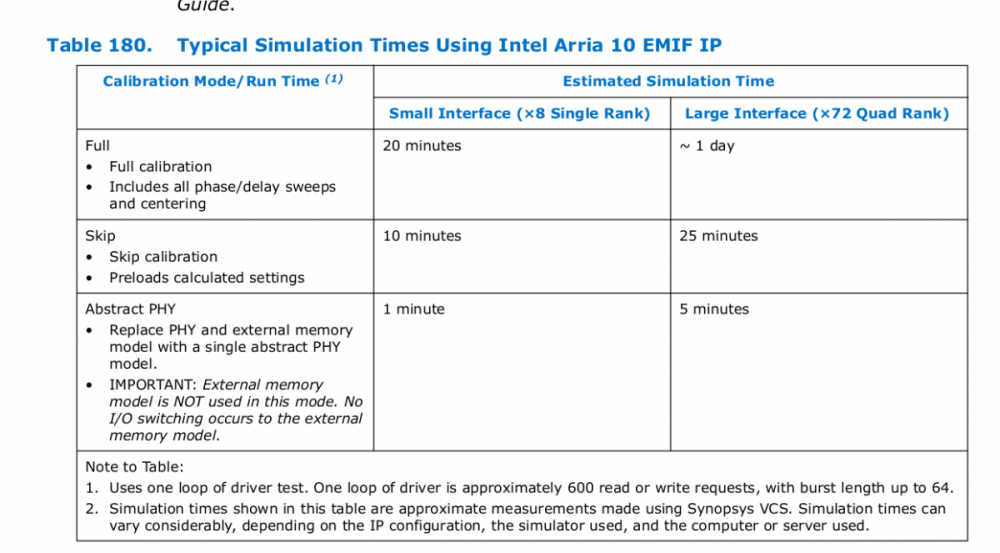
.jpg.d69a9fd9bfe5ac1c31f76322272695c3.jpg)