novartis
-
Постов
428 -
Зарегистрирован
-
Посещение
Весь контент novartis
-
Интел IP ядро Single и Double арифметика
novartis опубликовал тема в Среды разработки - обсуждаем САПРы
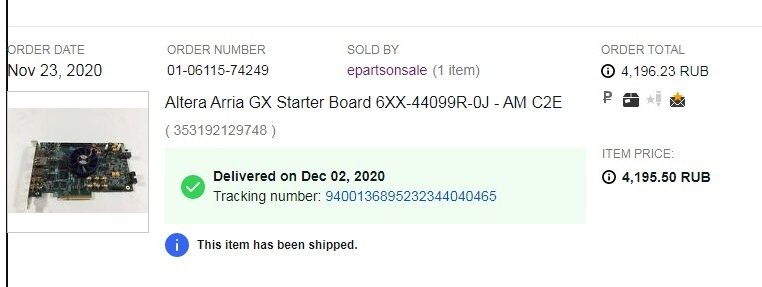
У Интела (Альтеры) есть готовые ip корки для вещественной арифметики. Мне понадобилось сложение. Если выбрать Single формат, то задержка на расчет будет 3 такта на частоте 250МГц и будут задействованы 2 аппаратных блока Аррии 10. А вот если выбрать Double формат, то задержка на расчет будет 11 тактов на частоте 250МГц, и почему то без аппаратных блоков. Это в интеле (алтере) инженеры ленивые и не захотели на аппаратных блоках реализацию писать, или для double есть какие то существенные отличия, сложности? Single: Double: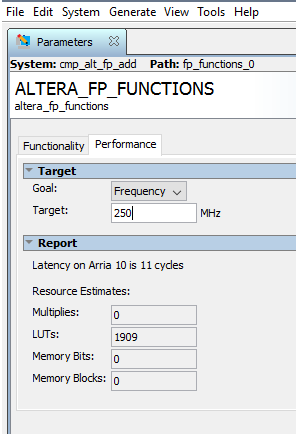
-
Купил эту плату на ebay в декабре, вместе с доставкой вышло чуть больше 5 тысяч рублей. Включил, лампочки мигают, на большее пока руки не дошли, купил именно из-за низкой цены и на предыдущей работе с ней много работал, нормальная плата. Помню у продавца их много было (>10 шт), сейчас нет, еще и в описании было написано с ошибкой, что это просто Arria GX, а не Arria V GX.
-
года два назад на алиэкспресс покупал, самые обычные. В один рейзер x16 вставлена плата с FPGA, в другой рейзер x16 вставлена сетевая карта. Эти два рейзера соединены между собой usb кабелем. К одному из этих рейзеров припаял витую пару к pcie refclk, другой конец витой пары припаял к рейзеру x1 - этот рейзер x1 вставляю в материнскую плату компа, от него и беру опорный клок для pcie. Ниоса нет. Сначала простую стейт машину набросал, потом реализовал простенький логический блок, который берет команды из памяти (чтобы команды мог без перепрошивки менять). Вместо сетевой карты цеплял NVME SSD диск, прочитал endpoint config space, запустил nvme контроллер (CC.EN = 1), посмотрел, что взводится ответный сигнал CSTS.RDY. Пока на этом остановился. Мне думается, что этот PCIe switch все у вас и портит.