dxp
Свой-
Постов
4 601 -
Зарегистрирован
-
Посещение
-
Победитель дней
18
Весь контент dxp
-
В даташите написано, что по 1М на землю на каждый вход. Между входами 2М. CMRR 10000:1 на DC. Зависимость от частоты не приводится.
-
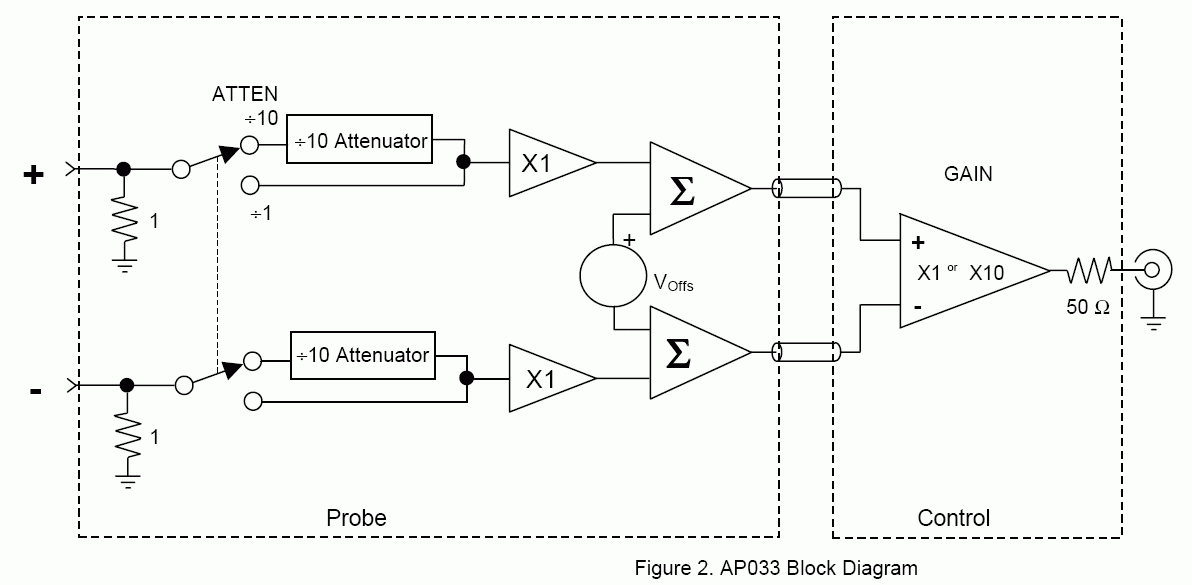
За что Вы меня так?.. :) Сам пробник не разбирали - боязно как-то, уж больно конструкция хлипкая. В доке на него есть такая картинка. Схематично, конечно, но кое-что проясняет.

-
А по сгенеренному коду если посмотреть, что видно?
-
Да нет, почему же не очень, очень даже очень. :) Просто у него здоровенная полоса, очень малые собственные шумы и, естестенно, сравнительно небольшой КОСС сам по себе. Смотреть таким пробником сигналы на относительно узкополосном Н-мосте с большой динамической синфазной видимо не самое лучшее применение указанному пробнику. А вот мелкий сигнал на фоне постоянки - самое оно. При этом у него очень малая входная емкость и возможность включить усиление на 10! Это значительно расширяет возможности наблюдения малых сигналов. Особенно с постоянной составляющией. Т.ч. дивайс очень даже ничего. Жаль, что такой дорогой, конечно. :(
-
Ну, это какие ОУ на это место подобрать. Чего бы их плючщило и колбасило в режиме повторителей, если их характеристики производителем в полосе нормированы. И лучше, конечно, взять сдвоенный вариант. :) Вот у нас, как раз, есть дифференциальный активный пробник от LeCroy. Около трех тонн баксов, между прочим. 500 МГц полоса, 3 пФ входная емкость, 3 нВ на корень из Гц шумов, в общем, круто во всех смыслах. Так вот, при измерении падения на шунте в Н-мосте, 24 В синфазное, 100 мВ сигнал, дешевый AD8205 дает практически идеальное подавление синфазной, а упомянутый пробник лажается - броски на переключениях. Т.ч. сам по себе КОСС там весьма небольшой.
-
А причем тут это. Я про Фому (про фильтр, т.е.), а Вы про Ерему. В общем, сдаетесь!? :) :) Да ну ! И Вы в состоянии заливающиеся данные по DMA тут же обрабатывать, так сказать в процессе пересылки DMA -> ОЗУ ? Тут одно из двух - или память должна быть 2-портовой в DSP (в фине внутренняя - однопортовая) или нужно обрабатывать данные по времени сразу за DMA, что требует (1) быстрого алгоритма, (2) филигранной отстройки системы. Тут можно сказать что скорость подачи данных будет определять каким сложным может быть алгоритм, т.е. если скорость у нас высокая фин просто ничего не успеет сделать. Как у Вас все сложно. Память в фине побита на блоки (afair, размером 4Кбайт) и можно спокойно одновременно обращатсья в разные блоки. Пока DMA льет данные в один блок, мы спокойненько лабаем другой, потом меняем местами. Там же тоже не дураки сидят, и фин - это не первый их процессор, прошлые ошибки учтены, новые возможности введены. Да хоть даром пусть его отдают - фирма AD славится своими "достижениями" в области камней и софта, глядя на толщину errata их чипов и уникальность visualdsp как-то становится не по себе. Ну, это вообще уже напоминает анек: :) "Встречаются лисенок, волчонок и медвежонок. Лисенок: - А мне мать джинсы привезла фирменные, на заклепках, с лейбаками! Во!! Волченок: - А мне батя магнитолу подарил, FM берет, лазерные диски, стерео, долби и все такое! Медвежонок: - А я... а мне... а у меня.... А я вам сейчас 3.14..дюлей дам!" :) А если серьезно, то не ошибается тот, кто ничего не делает. Фин - реально сложный проц, в нем помимо CPU еще наворочено ой-ой-ой сколько всякого. И чтобы это все заработало - надо поработать и напрягаться. Сегодня ревизия 0.4 уже вполне юзабельная. Да и в ките, где 0.3 стоит, я на грабли в интересующем меня спектре задач пока не наступал. По поводу уникальности. А не пугает уникальность Quartus'а или ISE? А под фин есть еще гринхиллс и даже, вроде (не проверял), гнутый компилер. С уникальностью тулзов в мире ПЛИС все значительно хуже, нежели в мире процессоров. Этой реплики не понял. Я хотел лишь сказать, что каждому зверю свой лес. И если есть задача, эффетивно решаемая, скажем, на MSP430 или AVR, то ставить туда ПЛИС или DSP по меньшей мере глупо. Кроме того, не одни ПЛИСы развиваются, но и процессоры тоже. И там прогресс весьма нехилый. И зацикливание на одном никогда не шло на пользу ни делу, ни квалификации специалиста.
-
От дифференциальной архитектуры никто и не предлагает отказываться - AD813x как раз дифференциальный усилитель с диф. входом и диф. выходом. Но у него получится небольшое входное сопротивление. Этот недостаток предгалается пофиксить просто с помощью буферов, цель которых - передать сигнал со входа на выход при наименьших искажениях (в том числе и смещения). Единственное "узкое" место тут - это резисторы в цепях дифференциальника. Их придется ставить прецизионными.
-
Знаете, пиписками мериться что-то неохота, да и времени нет. А если хочеться убедиться, то возьмите например простой КИХ фильтр тапа скажем на 32 и сравните. На блекфине это будет два тапа на такт, т.е. при 600 МГц 1200 мегатапов. Да, конечно, еще есть накладные расходы на настройку хардваре луп и дата адрес генератора, но это порядка 5-10 тактов. Такт 1.67 нс, таким образом вычисление очередного отсчета сигнала займет порядка (считаем по наихудшему случаю 10 тактов на инициализацию + 5 тактов на вызов функции и столько же на возврат): (10 + 5 + 5 + 32/2)*1.67нс = 36*1.67нс = 60 нс. И что?! Какая ПЛИС без параллелизма сможет такое? Что касается пересылки данных, то сведения об аппаратной поддержке этого процесса, в частности, у черного фина у Вас несколько неверные. Там есть 12-канальный DMA, который позволяет делать пересылки на максимальной скорости совершенно без участия CPU. Хоть с последовательного порта наливайте, хоть с PPI, хоть из внешней памяти во внутреннюю и обратно. Типично, скорость обмена с внешней SDRAM 133 МГц. Т.е. отнимем примерно 1% накладных на рефреш и получим (133-1.33)*16 или порядка 260 мегабайт в секунду (если непрерывно лить, а там все можно так организовать - DMA можно настроить один раз и он будет лить по дескрипторам по кругу). И если учесть что младший BF-531 стОит меньше $10 в розницу, то тут множно и подумать, на чем выгоднее делать. Особенно, если учесть, что сложность реализации подобных фильтров на процессоре на порядок (как минимум) меньше, чем на ПЛИС. Резюмируя. Никто не оспаривает того тезиса, что на ПЛИС, при возможности распараллелить и не ограничиваясь по стоимости, всегда можно сделать быстрее. Сказно было лишь то, что последовательлно на проце штатные операции выходят быстрее. И это логично - ведь там тоже железа нехило навернуто - умножитель-аккумулятор, толстые и быстрые шины, быстрое АЛУ и т.д., все это аппаратно на кристале, а не разведено на универсальной логике в ПЛИС. Никакой узел в ПЛИС не может работать быстрее аналогичного узла в аппаратном процессоре, это естественно. Поэтому у ПЛИС преимущества только возможности параллелить и на нестандартных операциях - типа, развернуть слово (чтобы младшие биты стали старшими, а старшие младшими), если проц не поддерживает это на уровне инструкций.
-
Почему бы тогда не использовать широкополосные прецизионные усилители в качестве буферных и дальше после них поставить дифференциальный драйвер типа THS413x, AD813x (выбрать по требованиям/вкусу). Буфера должны только точно передать сигнал, внеся на вход схемы большое входное, а дифференциальный драйвер делает все остальное.
-
В плане быстродействия cyc2 от cyc не особенно отличается, даже кое-где проигрывает. И на обоих можно и на 300 МГц разогнать. Только вот сложность логики, работающей на такой частоте, будет очень малой - не более одного уровня. Если же логику усложнить, то или тактовая сильно упадет, или конвейер придется городить, оптимизировать его. Тоже задача еще та. Какие такие универсальные задачи? Там заточенность под пересылку данных и арифметические операции - именно то, что и нужно. Что-то я очень сомневаюсь, что без параллелизма любой Cyclone обгонит тот же Blackfin@600MHz.
-
Если функция встроена, т.е. ее код явно помещен в точку вызова, то все испольуемое видно. Если организован вызов, то все, никих потрохов функции компилятор рассматривать не будет, поведение будет всегда таким, каким оно должно быть при вызове функции. Так ведь можно далеко зайти - а если та функция тоже содержит вызов и т.д. Обычно такое поведение присутствует на самом деле. Хотя, конечно тут поведение компилятора может быть неоднозначно - он может делать различные оптимизации. Сегодня уже есть варианты компиляторов, которые делают post-link оптимизацию, т.е. проходятся уже по слинкованному коду и оптимизируют его. Т.ч. делать просмотр всего файла и организовывать оптимизации в пределах него вообще не очень сложная задача. В общем, все зависит от самого компилятора, указанных оптимизаций и их стратегий. Кое-что, между прочим, из таких оптимизаций и делается. Например, при оптимизации по размеру компилятор ищеть одинаковые куски во всем файле, выносит их в отдельные функии и организовывает вызовы. Т.ч. возможно скоро доживем и до более крутых оптимизаций. Но в настоящее время этого, насколько знаю, нет и лучше контролировать этот процесс, явно указывая, встраивать функцию или нет. Кстати, квалификация функции словом inline совсем не гарантирует, что функция окажется встроенной. inline - это не более, чем подсказка компилятору, компилятор имеет полное право не встраивать функцию. Есть несколько объективный ситуаций, где встраивание не может быть осуществлено в принципе (например, рекурсивный вызов). Но в большинстве случаев у компилятора нет никаких причин отказывать во встраивании, если это явно указано. И кстати же, наш любимый IAR, как раз, замечен в нехорошем поведении - отказываться встраивать. Там, типа, как объяснили из саппорта, используется неслабый эвристический анализатор, который и определяет, стОит ли встраивать функцию или нет. По мне так все эти эвристики идут лесом, еще на версиях 2.хх столько крови они попили, сколько было сломано копий в дискуссиях с саппортом, доказывая, что эвристика - эвристикой, но лучше меня компилятор не может знать, встраивать функцию или нет, и если я явно написал inline (или определил тело функции-члена в классе), то пусть встраивает, не выпендривается. В конечном итоге они признали, что в этом есть смысл, но от эвристики не отказались, мотивируя, что если все отдать на откуп пользователю, то он (пользователь) может и дров наломать - навстраивает функций, а потом будет недоволен, что код у программы здоровенный. Поэтому для тех, кто хочет стопудово встроить фунцию и настаивает на этом, ввели специальную прагму #pragma inline=forced, при ее использовании гарантируется, что функция будет встроена, а если встраивание невозможно, то будет выдана ошибка. Этот подход, в принципе, устраивает всех. Т.ч. как уже сказал, всегда лучше держать этот процесс под контролем, если надо, чтобы функция была встроена, то лучше позаботиться об этом: сделать ее определение доступной в точке компиляции, снабдить словом inline и, если компилятор поддерживает дополнительные средства типа упомянутой прагмы, то обязательно использовать их.
-
Не все, а только используемые. Компилятор обязан генерить код, не нарушающий целостность работы программы, не более того. Исходя из этого, им сохраняются только регистры, используемые асинхронно (по отношению к основному потоку выполнения прогрммы). Если весь код обработчика прерывания доступен компилятору на этапе компиляции, то компилятор может легко определить, какие именно регистры ему нужны, и именно их и сохранить. Если в обработчике прерывания используется вызов функции, чей код недоступен компилятору (т.е. если функция невстраиваемая), то компилятор не знает, какие регистры эта функия использует и сохраняет все scratch регистры (preserved регистры ему тут сохранять не надо, их сохранит при необходимости вызываемая функция). Исходя из этого, если нужен максимально быстрый обработчик прерываний, то вызов функций нецелесообразен. Если все-таки такая необходимость есть, то имеет смысл подумать, нельзя ли сделать эту функцию встраиваемой и разместить ее определение в заголовочном файле так, чтобы ее определение было доступно компилятору в точке компиляции кода обработчика прерывания.
-
Такие вещи хороши в "динамических" системах - где что-то может добавляться/изменяться в процессе работы. У меня-же все жестко привязано: те-же менюшки раз и навсегда определены и зафиксированы в коде программы. Т.е. все "навороты" с цепочками указателей - просто не нужный оверхед. Я понимаю, что нынче это не принципиально - за каждый байт/такт не борятся, но все-же. Кстати - огород с классами в программе на MSP430 настолько раздул код и стек, что я перестал влезать в контроллер. Несколько странно. Интенсивно использую классы, виртуальные функции, не замечал, чтобы это давало заметный оверхед. На MSP430, например, вызов виртуальной функции по сравнению с вызовом обычной функции - это всего две быстрых (однотактовых) регистровых команды, т.е. практически незаметно. На AVR оверхед чуть больше, но тоже не давит. Т.ч. непонятно, откуда раздулся код и возникли дополнительные требования к размеру стека. Вот чем можно легко и незаметно разудуть код и потребляемую память - так это шаблоны. :) Тут надо аккуратно следить и думать при инстанцировании. Но оверхед от приемения классов (даже с виртуальными функциями) очень мал, практически программа по быстродействию и размеру не будет отличаться от программы с той же функциональностью, написанной на С. Что касается "динамических" систем, тоже не согласен. Если не надо ничего менять, то и не меняйте - заложите указатели в таблицы намертво. Таблицы эти (если большие) можно и во флешь затолкать.
-
ADUM в качестве SPI развязки
dxp ответил Serjio тема в Форумы по интерфейсам
Применял 1400 и 1100, никаких проблем не обнаружил. Видимо, все-таки индивидуальные особенности окружения. -
точка привязки корпусов
dxp ответил mika тема в Altium Designer, DXP, Protel
Tools->Preferences->Protel PCB->General, включить крыжик Smart Component Snap. Так он будет цепляться за ближайший пад. Надо за первый - тыкаете примерно в первый и он к центру первого и приклеится. Почитайте подсказку на крыжик и все станет ясно. -
По фотке. Конденсаторы, которые на кварце висят - их надо на ноги проца вешать. Стопудов. :)
-
Двухстороннее размещение элиментов
dxp ответил Muxamor тема в Altium Designer, DXP, Protel
Разрешить правило Component Clearence с параметром Full Check. -
Реально синхронизация, предистория не зависят у последних моделей осциллографов от интерфейса ПК встроенного в осциллограф. Это реализовано на различных FPGA и тому подобном железе. Я где-то утверждал другое? Еще есть промежуточный уровень - статистики всякие и прочая "околостандартная" обработка, которые реализовывать аппаратно достаточно непросто (по сравнению с реализацией в виде программы ПК) и возможности аппаратной реализации в плане функциональности весьма ограничены. :) У Вас слишком высокое мнение о возможностях FPGA в плане функциональных возможностей прибора. Каковы бы эти возомжности ни были, реализация на программно уровне как минимум на порядок проще. А значит и баги и отладка/"вылизывание" кода идут намного быстрее и качественнее. Прежде чем обсуждать вопросы тормознутости, надо сначала определить, что именно не устраивает? Скорость обновления экрана? Т.е. если я сейчас на своем скопе не вижу аналогового мельтешения, то это недостаток? Я так не считаю. Дивайс мне позволяет четко и без проблем ловить и отображать интересующие меня сигналы, производить их оценки, измерения и обработку. Что еще надо? Тем более, что в новых скопах эта проблема уже решена путем подачи сигнала на экран минуя постобработку.
-
Включен, мне нужны его фичи: инлайн функции, переопределения функций и т.п. Жаль :( А тогда каким образом можно это обойти: пример структура с меню, содержит массив структур пунктов. Число пунктов может быть различно. Придется делать отдельно массив с пунктами мень, а в структуру меню вставлять адрес этого массива. А так как массив пунктов меню - это тоже набор указателей - в процедуре меню получается обращение по цепочке указателей, что мне не очень нравится. Почему не нравится? Именно так - через указатели на функции, - и делают подобные вещи. Конечно, при развесистых меню получится гора маловразумительного запутанного кода, и чтобы облегчить ситуацию тут, как раз, С++ные фичи и катят. Используйте для посторения меню возможности ООП. Т.е. создайте абстрактные базовые классы меню, элемента меню с чисто виртуальными (pure virtual) функциями. От них наследуйте конкретные классы, где переопределите эти функции. Все должно получиться элегантно и красиво. Множество ГУИев строится именно так.
-
А С++ случайно не включен? В С++ Incomplete types не разрешены. Только в С.
-
Это я все видел. Только тут тоже есть вопросы. Например, при записи в LCx даже 0 все равно уходит 10 тактов на каждый. И независимо от того, какое там записано значение. Т.ч. 20 тактов как с куста. :( И все же, где в доке (кроме этого ЕЕ) описаны все эти такты? Облазил HRM, PRM вдоль и поперек. Не нашел. Смутно помню, что вроде где-то попадалось, но вспомнить, хоть убей, не могу. Должно же где-то это быть! :cranky:
-
Полоса измерительного усилителя
dxp ответил DSIoffe тема в Вопросы аналоговой техники
Полосу-то (в смысле какого-нибудь прохождения сигнала) сохранит. Но инструментальным усилителем быть перестанет. Во всяком случае степень "инструментальности" сильно уменьшится. :) На пальцах если: одной из главных (если не самой главной) характеристикой инструментального усилителя является коэффициент подавления синфазной составляющей (КПСС :) ) или, по-буржуйски, CMRR (Common Mode Rejection Rate). И он в первом приближении зависит от согласования резисторов схемы. А во втором приближении от идеальности самих ОУ. Т.е. резисторы все определяют только в том случае, если используемые ОУ идеальные, т.е. обладают бесконечным усилением и полосой. Если ОУ не идеальные, как имеет место быть на практике, то их влияние уже нельзя сбрасывать со счетов. К примеру, один усилитель, скажем, в верхнем плече, чуть хуже такого же, который стоит в нижнем, т.е. все у него в допуске, но реально коэффициент усиления разомкнутой ОС немного меньше. Или полоса у него поменьше. На низких частотах (по отношению к полосам ОУ) это не сказывается - по обратной связи все нормально отрабатывается. Но с увеличением частоты верхнее плечо уже имеет петлевое усиление меньше нижнего и, как следствие, возникает дополнительное (паразитное) рассогласование сигналов, что вносит ошибку. Примерно та же картина и с выходным дифференциальным усилителем - его идеальность с увеличением частоты падает, что вносит ошибку. Поэтому получить большие значения CMRR (> 90-100 дБ) на больших частотах реально трудно. Применение широкополосных ОУ может помочь, но и тут есть ограничения - у широкополосных ОУ, как правило, другие параметры, влияющие на точность, не блещут - напряжения смещения, входные токи и их разность, коэффициент усиления разомкнутой ОС относительно небольшой, что не дает получить хороший CMRR даже на низких частотах. В общем, можно как-то соптимизировать, спроектировать подходящий инструментальник на требуемую полосу, но в целом проблема есть и реально, как уже сказали, получить CMRR даже >80 на десятках МГц практически очень сложно, если вообще возможно на сегодняшний день. -
Зачем это еще каждый бит смотреть? Байт приняли и смотрим, что там пришло. И сразу видно, правильно или нет. И если неправильно, то видно. что неправильно. Надуманная ситуация. А реально гораздо чаще бывает так, что отладили на симуляторе, все замечательно работает. А зашили в железо, и перестало работать. И все потому, что там еще другие части проекта шевелятся, отнимают процессороное время, вызывают свои прерывания, которые лочат наше отлаженное. И это проблема и задача гораздо серьезнее и жизненее. Требует системного подхода.
-
Скорость обновления экрана - это проблема любого скопа, который пропускает данные через обработку, тут уж ничего не попишешь. Сейчас есть решения, как это обойти - в новых раннерах Xi как раз такая фича реализована - режим быстрой прорисовки, когда данные после АЦП сразу, минуя ПК, подаются на экран. Внешне очень похоже на экран аналогового скопа, смотрися клево. :) Правда, практическая полезность этого мне не очень ясна. С цифровым скопом сам принцип работы другой - у него множество режмов синхронизации, "предистория" сигнала, всякие зумы и прочее, ему эта скорость прорисовки разве что "до кучи". Меня тоже поначалу несколько коробила тормознутость реакции вывода на экран. Но когда освоился, так и по-другому не очень-то и надо. Главное, что схватил он сигнал, а дальше смотри его как хочешь и сколько влезет. И вся обработка тут же. Т.ч. если цифровой скоп может только быстро экран обновлять и больше ничего, то идет но лесом.
-
У IAR IDE, конечно отстой полный. А где Вы лучше видели? Все они примерно одинаковые. Оболочкой пользоваться на начальном этапе гораздо проще. Для связки редактор+make надо "дорасти", освоить фичи редактора, освоить make (где тоже нюансов дофига). И все равно, для "попробовать" в оболочке получается всегда быстрее - не надо разбираться с ключами командной строки и прочим. Хотя, конечно, для серьезной работы вариант редактор+make как правило подходит лучше.