dxp
-
Постов
4 526 -
Зарегистрирован
-
Посещение
-
Победитель дней
9
5 Подписчиков




Информация о dxp
-
Звание
Adept
")
Посетители профиля
12 916 просмотров профиля


-
Помнится, было дело тут на форуме: кто-то скидал простой, но затратный на сборке проект под Quartus (как бы не для Cyclone II), и все желающие могли собрать его на своём железе и выложить результаты -- была какая-то более-менее объективная оценка эффективности сборочной машины. Может тоже так же сделать: скидать проект под Vivado, например, на Artix7-200, и выложить, чтобы все желающие могли попробовать и доложить какие-то более-менее объективные результаты? Показать: конфигурация РС, время сборки в формате: IP ядра. Синтез. P&R. Общее время. Вот только состав проекта надо подобрать, чтобы там не было перекосов, чтобы все компоненты равномерно задейстовались: комбинационная логика, флопы, блочная память, IP ядра (как минимум PLL, а ещё, может PCIe), DSP блоки (но без фанатизма). Может есть что-то готовое на примете? Думается, такое было бы и интересно многим, и полезно.
-
Vitis Appearance
dxp опубликовал тема в Среды разработки - обсуждаем САПРы
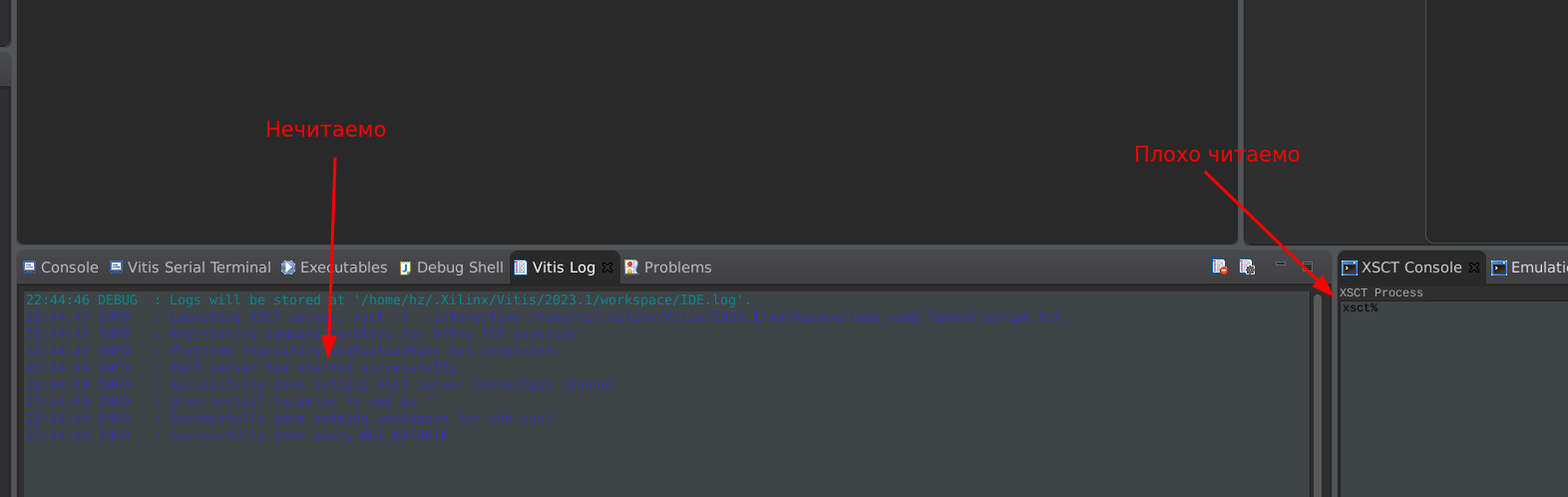
Всем привет! Какое-то время назад доводилось работать с Xilinx SDK. Потом была пауза в несколько лет, и вот сейчас опять возникла такая необходимость, но вот SDK канул в лету, и теперь вместо него Vitis. Ну, в целом вроде то же самое - эклипсообразная хрень, но сразу же столкнулся с неприятной неожиданностью: если раньше там (SDK) была традиционная светлая тема, которая, может, не слишком красивая, но вполне функциональная -- во всяком случае, всё хорошо читаемо, но теперь это просто... я не знаю, как это назвать. Оно стало тёмно-тёмно серым (щас такая мода пошла -- многие софты в этот мышиный цвет красят), и ладно бы, если бы не некоторые "но". А именно: на этом фоне содержимое отдельных окон или плохо читаемо, или вообще нечитаемо! Вот сразу с ходу при загрузке: Прочитать этот мутно-синий текст можно, только выделив (тогда контрастно)! Такая же история, например, с окном дизассемблера -- тоже такой же блёкло-синий на фоне мышиного. Ковырял настройки нашел про цвета, но там в основном настройки цветом элементов интерфейса, подсветка синтаксиса и подобное. Можно поменять фон отдельных окон, от этого вид ещё ужаснее -- некоторые окна с белым фоном, некоторые -- вот такие, тёмно-серые. Изменить цвет шрифта этих окон и окна дизассемблера не смог. Погуглил про темы (скины), вроде нашёл какое-то описание что-то там установить в виде плагина через некий marketplace, но интерфейс плагинов в Vitis или отключен (так было сказано по одной из ссылок -- и есть основания этому верить, т.к. длительные попытки найти возможность что-то установить через этот самый маркетплейс, не увенчались успехом), либо унесён куда-то в непонятное место. В общем, у меня два вопроса: 1. Риторический, к авторам этой поделки: они сами-то пробовали этим пользоваться? 2. Практический: кто как обходит эту неприятность? есть ли способы?
-
Падение 0.12 при токе 0.5А -- это характеристика силового элемента этого стабилизатора - т.е. то, что он может обеспечить, а не всей схемы. При питании 3.6В и падении на светодиоде 3 В остальные 0.6В рассеятся на внешних элементах. Итого, 0.5*0.6 = 0.3 Вт. Если питание будет выше, потери на тепло будут больше. А 0.12 падения на стабилизаторе говорит только о том, что он способен обеспечить 0.5А и выдать в нагрузку 3В при питании 3.12В. Если вам КПД и тепловыделение не препятствуют, то это другое дело. Но линейным силовым схемам по КПД тяжело тягаться с импульсными. У линейных есть другие преимущества.