Поиск
Показаны результаты для тегов 'xdma'.
-
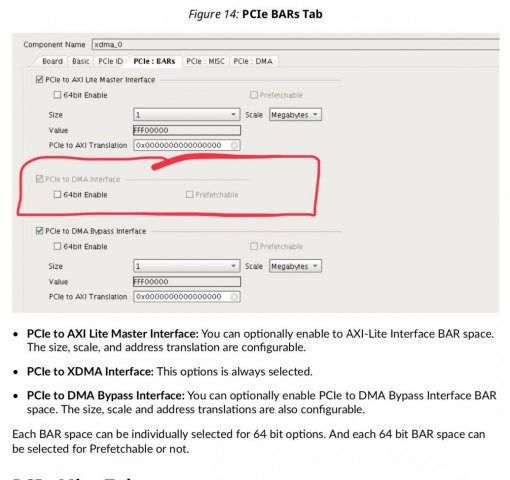
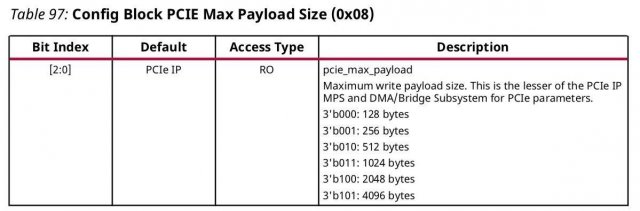
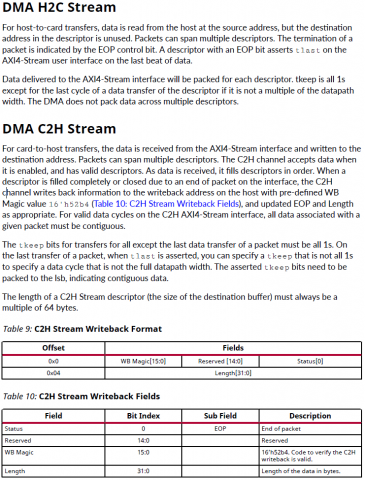
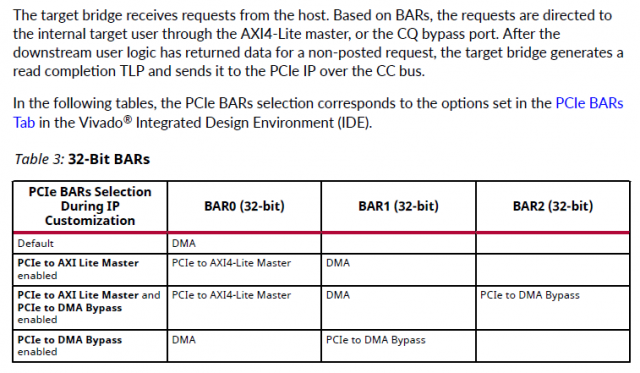
Собственно задача - с минимальными потерями времени и усилий работать с хоста через PCI-E с ускорителем в ПЛИС. Насколько я понял самый простой способ - использование ядра XDMA (обёртка над ядром PCI-E) [1], готовых драйверов xdma.ko [2] и шаблонов приложений которые идут в комплекте [3] Но после вдумчивого изучения pg195 и запуска на плате тестового примера остались вопросы, хотя они скорее системного плана, но связаны именно со спецификой ядра XDMA. Что надо от ускорителя (для определенности - пусть будет крипто-ускоритель): 1) "стримить" с хоста данные на обработку, притом чтобы ускоритель мог сообщать, что достаточно, пока больше не надо присылать данные (т.е. некий flow control на отправку) 2) уведомлять хост о том, что данные обработаны и можно забирать, и соответственно отдавать "стрим" в хост. Почему стрим в кавычках: по сути это не непрерывный стрим, а блоки по 4К (притом с заголовками, чтобы на приёмной стороне (хосте) можно было сматчить контекст - какому выходному блоку какой входной соответствовал), но по природе обработки ускоритель это как PIPE: с одной стороны вышло, с другой вышло и есть некая "глубина" внутри - чтобы начал выдавать первые данные надо несколько десятков блоков в него "застримить". Т.о. в терминах xdma для этой задачи AXI Stream подходит очень хорошо, но вот на тестовом проекте заметил нестабильную работу AXI Stream (пропадание данных) в связи с чем рассматриваю и AXI MM как альтерантиву. Но что бы написать "правильное" и надёжно работающее хостовое приложение хотелось бы понимать несколько вещей (далее список вопросов): ##### BAR ##### pg195, таблица 3, соответствующа вкладка в конфигураторе XDMA * DMA - это собственно работа с самим движком * Bypass DMA - думал что это прямой доступ к пространству памяти карточки в обход движка ДМА, но похоже это не так, это ЕЩЕ ОДНО выделенное адресное пространство (доп.канал) никак не связанное ни с движком ДМА ни с памятью в которую пишет движок ДМА. * AXI Lite Master - видимо от Bypass DMA отличается только тем, что это Lite 1.1 Смущает то, что для BAR DMA в режиме AXI MM в конфиге вивадо никак не задаётся размер BAR - это как?.. где/чем определяется размеры адресного пространства с которым работает карточка? 1.2 Далее в разделе про прерывания вскользь упомянуто, что BAR может быть _address space_ а может быть и _register space_. Надо ли держать это в уме или при использовании готового драйвера просто работать с /dev/xdma0_xxx и не париться? 1.3 Какие реальные кейсы могут быть для использования Bypass DMA ? ##### IRQ & user app ##### У самого IP-ядра есть внешние ножки прерывания, но как их использовать pg195 ответа не даёт, ограничиваясь тестовым примером проекта, в котором прерывания взводятся записью из хостовой программы в регистр в пространстве AXI Lite Master. Но как это обработать из хостовой программы совершенно неясно: 2.2 Вот мы открыли /dev/xdma0_h2c и льём туда данные, как считать прерывание "BUSY", что дескать лить хорош уже (и дальше ждать прерывания "FREE") - как это на стороне пользователя обрабатывать? 2.2 При приёме мы открываем /dev/xdma0_c2h и ждём прерывания "READY" указывающее на готовность данных в /dev/xdma0_c2h - как это на стороне пользователя обрабатывать? 2.3 Чем "правильнее" пользоваться на стороне карточки - ножками usr_irq_req и usr_irq_ack, или же механизмом MSI (msi_enable, msi_vector_width)? 2.4 В AR654444 еще описан способ загрузки драйвера в режиме поллинга (работает только в направлении c2h) - стоит ли использовать его вместо прерывания для упощения логики приложения? ##### AXI ST ##### Самое интересное: управление потоками, нарезка на "пакеты" DMA H2C Stream -------------- For host-to-card transfers, data is read from the host at the source address, but the destination address in the descriptor is unused. Packets can span multiple descriptors. The termination of a packet is indicated by the EOP control bit. A descriptor with an EOP bit asserts tlast on the AXI4-Stream user interface on the last beat of data. - т.е. на стороне хоста за формирование для AXI4-Stream сигнала tlast, который фактически нарезает пакеты как мне надо, отвечает отвечает механизм, выставляющий бит EOP (в TLP???) 3.1 достаточно ли для user app указать size=4K, для формирования EOP в xdma.ko? 3.2 см. пп.1.1 если мы не задали размер BAR для DMA, то кто будет заботиться о буферах в движке DMA на карточке и в пользовательском РТЛ коде? Буферы в движке DMA на карточке вообще черный ящик: вот отправим мы пакет с size=1М - куда его сохраняет движок DMA? - не налету же он его в пользовательскую логику передаёт??? 3.3 по размерам нашёл такое упоминание в PG195, эти значения как-то завязаны на размер внутренних буферов движка ДМА??: DMA C2H Stream -------------- For card-to-host transfers, the data is received from the AXI4-Stream interface and written to the destination address. Packets can span multiple descriptors. The C2H channel accepts data when it is enabled, and has valid descriptors. As data is received, it fills descriptors in order. When a descriptor is filled completely or closed due to an end of packet on the interface, the C2H channel writes back information to the writeback address on the host with pre-defined WB Magic value 16'h52b4 (Table 10: C2H Stream Writeback Fields), and updated EOP and Length as appropriate. - тут вроде бы тоже всё прозрачно - нарезаем пакаты для отправки сигналом tlast в AXI4-Stream, который по идее должен устанавливать в дескрипторе поле EOP 3.4 Удаляет ли при приёме дескриптор с WB Magic драйвер xdma.ko или же его должно удалять пользовательское приложение? 3.5 не очень понятна строка "For valid data cycles on the C2H AXI4-Stream interface, all data associated with a given packet must be contiguous" - означает ли это, что до взведения tlast надо держать tvalid и лить данные без пропуска клоков (иначе движок ДМА "отрежет" и отправит пакет на хост по таймауту)? ##### AXI MM ##### 4.1 опять см. пп.1.1 - как задаётся размер пространства для AXI MM? В интерфейсе конфигурирования нет такой настройки. ##### источники ##### [1] https://www.xilinx.com/support/documentation/ip_documentation/xdma/v4_1/pg195-pcie-dma.pdf [2] https://github.com/Xilinx/dma_ip_drivers [3] https://github.com/Xilinx/dma_ip_drivers/tree/master/XDMA/linux-kernel/tools