


lennen
Свой-
Постов
233 -
Зарегистрирован
-
Посещение
Весь контент lennen
-
Вейвлет анализ - сам процесс фильтрации
lennen ответил lennen тема в Алгоритмы ЦОС (DSP)
Вернулся к теме и стало интересно. Прочитал еще раз топик и есть непонятный момент: После университета я это не использовал, поэтому можете уточнить? То есть когда мы принимаем сигнал любой системой связи, мы его можем сгладить некоторым окном, так, это об этом речь? А где это используется в OFDM-трансиверах, на каком этапе? А то вроде БПФ и ОБПФ классически делаются, окно то на этом этапе не используется, или я неправ? А далее появилась идея. Santic показывал, как графики ЛЧМ-сигнала показаны на 3-х мерной плоскости после оконного Фурье-преобразования. Я так понимаю, чем специфичен ЛЧМ, что он идет в виде наклонной прямой на графике. Santic, и только сейчас дошло, на графиках - это а-ля OFDM? Или Вы это и делали для случая с OFDM? Можете подробнее немного пояснить, если не секрет? Но если мы рассматриваем то же оконное преобразование Фурье в качестве базиса в системе связи, получается, что в обычном ОБПФ мы не сможем сделать ЛЧМ. А если возьмем хотя бы оконное БПФ (с ориентировкой на Вейвлет как более детализирующее в тех или иных диапазонах), получается, что теоретически можно генерировать ЛЧМ-OFDM-сигналы. Как-то я поднимал эту тему, хотя уже не помню, но 1. ЛЧМ в каких-то случаях работает лучше синусоиды. 2. В скорость изменения ЛЧМ можно тоже что-то заложить. Так вот, это мои доводы, я хочу понять, не заблуждаюсь ли, давайте еще раз прикинем. 1. В каких случаях ЛЧМ-модулированный сигнал дает преимущество перед модуляциями гармонического сигнала? 2. Можно ли с помощью оконного БПФ сгенерировать OFDM-сигнал, в котором будут не гармоники, а ЛЧМ-поднесущие? 3. Наверняка есть уже такие сигналы и исследованы (например, при этом показаны их недостатки). Может есть какие-то источники с данной информацией? Вот я нашел пару статей, но это же по каким-то причинам не используется? Или наоборот просто надо дальше копать? https://ieeexplore.ieee.org/document/6313888 https://ieeexplore.ieee.org/document/7097051 4. Действительно ли просто разделить несколько ЛЧМ-сигналов, одновременно идущих во времени, частоты которых пересекаются между собой, но в разные моменты времени? А если это будет не просто в модели на графике, а в трансивере? -
Прием сигнала анализатором - ресемплинг
lennen ответил lennen тема в Алгоритмы ЦОС (DSP)
Ок, можно тогда проще. Допустим, я принял такое созвездие, как на рисунке. Частота дискретизации на передатчике 1 МГц. На приеме полоса 4,167 МГц. В двух словах то все просто, данные то я уже на глаз различаю. Просто в каком смысле - созвездие эллипсоид, значит дисбалланс I и Q, и созвездие с размытыми точками и крутящейся фазой, что исправляется синхронизацией несущей частоты. Как я могу это смоделировать в Matlab, или хотя бы с чего начать? -
Прием сигнала анализатором - ресемплинг
lennen ответил lennen тема в Алгоритмы ЦОС (DSP)
Попробовал еще так. M = 4; fs = 1e6; foffset = 100; carriersync = comm.CarrierSynchronizer('Modulation','QPSK', ... 'DampingFactor',0.05,'NormalizedLoopBandwidth',0.01); syncInfo = info(carriersync) aa = [foffset/fs syncInfo.NormalizedPullInRange/(2*pi)] carriersync.DampingFactor = aa(1)*1000; fid=fopen('C:\Users\User\Documents\UDP_log.pcm','r'); sig=fread(fid,inf,'int16'); I = sig(1:2:end); Q = sig(2:2:end); fclose(fid); sI = smooth(I,4); sQ = smooth(Q,4); yI=resample(sI,1000,4167); yQ=resample(sQ,1000,4167); ss = I+1i*Q; [ssI,phErrI] = carrSynch(ss); plot(ssI); hold on; Но получается, пока не могу въехать в тему, как использовать CarrierSynchronizer и нужен ли он тут вообще. Картинка может служить логотипом или продолжением кубизма-круголизма-импрессионизма. Я так-то осознаю чуть чуть, что раз эллипсоид, нужно устранить IQ дисбаланс, а раз все смешалось в круг, надо применить то, что пробовал. Но вот я не могу до конца понять, подскажите, пожалуйста, чтобы я все таки получил долгожданные точки созвездия:) Попробовал эту функцию без компенсатора: compSig = iqImbComp(ss); Но что-то не так может настраиваю. Если мои вопросы очень простые, прошу наставить, что я могу сделать следующим шагом. Возможно уже есть готовое решение на Матлабе, которым могу воспользоваться?
-
Прием сигнала анализатором - ресемплинг
lennen ответил lennen тема в Алгоритмы ЦОС (DSP)
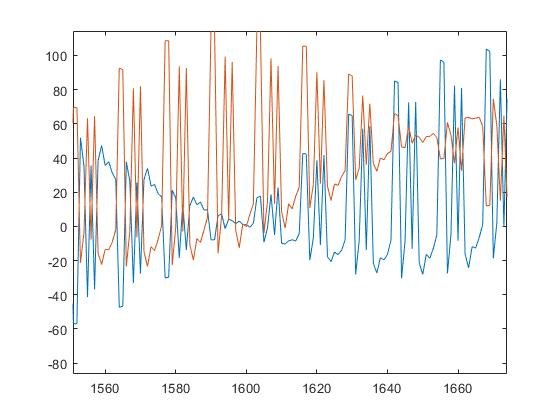
В общем, немного расширяется суть топика. Ресемпл я сделал, серьезно помогло. Передаю на синхросигнале длинную постедовательность Баркера 13-позиционную, а в качестве информации зацикленный код Баркера 13-позиционный, так вот, на графиках, я приложил, видно, что все принял на ура. Но это на глаз так. 1. Амплитуда постоянно скачет, как это устранить. 2. Как проще сделать правильный детектор? Чтобы в итоге я получил просто битовую последовательность I и Q и мог дальше это интерпретировать как QAM-модуляцию... 3. Понял, что вопрос немного расширяется. Там в сигнале видно, что присутствует паразитная ненулевая частота, как ее лучше убрать Сейчас примерно так все представляю, но не получилось! Сигнал после кода все-равно скачет по гармонике. fid=fopen('C:\Users\User\Documents\UDP_log.pcm','r'); sig=fread(fid,inf,'int16'); I = sig(1:2:end); Q = sig(2:2:end); fclose(fid); sI = smooth(I,4); sQ = smooth(Q,4); yI=resample(sI,1000,4167); yQ=resample(sQ,1000,4167); carrSynch = comm.CarrierSynchronizer( ... 'SamplesPerSymbol',1,'Modulation','QPSK'); [ssI,phErrI] = carrSynch(yI); [ssQ,phErrQ] = carrSynch(yQ) plot(ssI); hold on; plot(ssQ); hold off;

-
Прием сигнала анализатором - ресемплинг
lennen ответил lennen тема в Алгоритмы ЦОС (DSP)
Шикарно, в принципе решение, спасибо! Но думаю еще, а так же теряется информация об амплитудах остальных точек. Можно как-то использовать эти 4,167 выборки для накопления информации об амплитуде сигнала? -
Прием сигнала анализатором - ресемплинг
lennen опубликовал тема в Алгоритмы ЦОС (DSP)
Я генерирую сигнал векторным генератором, задал частоту дискретизации 1000 кГц, то есть полоса сигнала 1 МГц, 0.5 МГц слева несущей частоты и 0.5 МГц справа, я прав? Тогда имеем на приеме необходимость анализа полосы 1 МГц. В приборе доступно 4.167 МГц, то есть на каждую выборку моего сигнала теоретически приходится 4.167 выборок с анализатора спектра, опять же, ничего не путаю? Итак, в итоге получаем, что мне нужно в Матлабе использовать какой-то фильтр, который бы из 4.167 выборок сделал одну. Подскажите несложное и правильное решение, чтобы не ломать голову? Я бы мог просто откидывать лишние выборки, но дробный коэффициент заставляет меня пока сильно напрячься + фильтр, наверное, эффективнее был бы здесь, но вот хочу услышать варианты для моего случая. Принимаю обычный 13-позиционный код Баркера, на приеме отлично вижу как синхросигнал, так и информационный код, но надо дальше с ним что-то делать. -
Модель канала связи для слепого разделения сигналов
lennen опубликовал тема в Алгоритмы ЦОС (DSP)
Имеется 2-4 сигнала, они так-то из разных источников. Проходя через канал связи, они проходят разные пути, зашумляются и смешиваются. На приеме стоит столько же антенн, сколько и сигналов, 2-4. Я использовать FastICA и просто разделил сигналы. Но там модель канала связи такая: X = A*S, где S - это 2-4 вектора сигнала, A - это как канал связи, случайные мультипликативные коэффициенты для сигнала, X - это уже набор 2-4 векторов, которые приходят на приемник. Трудность я ощущаю пока в том, что канал Прокиса и АБГШ то добавить вообще не вопрос. Я в Matlab моделирую, кстати. Но сигналы надо сложить.... Итак. И я имею вариант, но я в нем сомневаюсь, подскажите, плиз. %s1, s2; s1_awgn = awgn(s1); //Если зашумить каждый сигнал в отдельности, то он шум будет разный для каждого сигнала s2_awgn = awgn(s2); s11_proakis = proakis11(s1_awgn); //Каждый сигнал также проходит через свой многолучевой канал связи s21_proakis = proakis21(s2_awgn); //Первое число - номер для сигнала, второе - номер антенны sum1 = s11_proakis + s21_proakis; //Наконец-то суммировали s12_proakis = proakis12(s1_awgn); //2 антенна s22_proakis = proakis22(s2_awgn); sum2 = s12_proakis + s22_proakis; Заодно хочу спросить, а FastICA потянет решение такой задачи? Или что бы вы предложили и почему? Кстати, а киньте еще ссылок, может какие-либо интересные коды по этому поводу есть в направлении MIMO-систем? -
Есть ли усиление в CDMA?
lennen ответил lennen тема в Алгоритмы ЦОС (DSP)
Супер. А получается, что IDMA это тоже аналог перенасыщенного множества сигналов? Только как итеративный Турбоэквалайзер + CDMA? Я бы сейчас прочитал про ПМД, но не сильно понял, можно в двух словах? Сложность приема ок, но получается, что перенасыщенное множество все таки дает выигрыш при прочих равных условиях? -
Есть ли усиление в CDMA?
lennen ответил lennen тема в Алгоритмы ЦОС (DSP)
Вынужден упомянуть мой последний пост, так как немного двигаемся, но масло масленым) Выигрыш в скорости за счет расширения спектра методом расширяющей последовательности - для меня это не равные условия, так можно сделать и для одного пользователя. Grizzzly, а есть какие-нибудь графики по поводу выигрыша при определенных замираниях CDMA с юзерами против OFDM c 1 пользователем? Ну хотя бы по памяти где-то встречались? Просто я понимаю, что когда у нас в течение 1 чипа ПСП сигнал замер, то конечно вроде как очевиден выигрыш CDMA. А как это показывают в теории? А по поводу этой моей цитаты в этом посте - все таки вроде количеством пользователей выигрыша не добъешься, не? Добъешься только если суммарная энергия этих юзеров окажется меньше, чем если бы их по-отдельности передавали. ? Andyp, но таки хороший комментарий по поводу широкополосности. Получается, что если куча потоков передается в одном спектре, спектральная эффективность все же может не упасть? Как раз по причине того, что действует, например, узкополосная помеха и тп... Статья интересная, но честно я до сих пор не всегда понимаю, как канал Рэлея + АБГШ модель канала связи помогает заметить в OFDM выигрыш, тогда как выигрыш, если правильно понял, в борьбе именно с узкополосными селективными помехами или быстрыми замираниями во временной области... -
Есть ли усиление в CDMA?
lennen ответил lennen тема в Алгоритмы ЦОС (DSP)
1. В отличие от TDMA, в CDMA-радиосигнале постоянно присутствует информация сразу обо всех пользователях. Конечно, это увеличивает мощность, тогда мы должны ее уменьшить для равных условий. Получается, что CDMA работает за счет корреляции с ортогональным кодом, что приводит к тому, что информация собирается во все моменты времени, в отличие от TDMA. Верно? 2. Так как надо уменьшать мощность, вроде TDMA и CDMA действительно практически одинаковы. А какие преимущества по совместному использованию спектра? Я пока вижу только борьбу с замираниями, но вроде замирание, так как мультипликативно, иначе ему без разницы, CDMA там или OFDM с 1 пользователем. Имеется ввиду, что если будет быстрое замирание, то потеряется информация не для пользователя N, а для всех пользователей, но за счет кода Уолша это будет не так критично? Меньшие требования к синхронизации? Да, можно и так подходить, как сейчас пробуем, но у меня остается эта дилемма, ведь если ортогональных кодов больше, чем длина кода Уолша, то получится выигрыш в скорости из за числа пользователей, так? Полоса должна быть одинаковой, все таки. Я так рассматриваю пока: Хотя подержите в голове, но я так понимаю, что конечно, растет полоса, растет и помехоустойчивость, так то интересная вещь, которую, кстати, кто и где использует?) На практике просто не встречал. То есть если не имеется выигрыша в CDMA, то почему именно на основе всего вышесказанного? Действительно не можем сделать больше ортогональных кодов, чтобы было скорее 2^n, а не просто n юзеров при длине ПСП n. -
Есть ли усиление в CDMA?
lennen ответил lennen тема в Алгоритмы ЦОС (DSP)
В Баскакове нет случая по поводу уровня шума для множества сигналов. Ок, по порядку и по полочкам. Наша цель посмотреть, есть ли выигрыш в CDMA по сравнению с OFDM (1 пользователь), если брать равные условия. Разделение на реальных пользователей не подразумевается, в итоге все принимает один приемник и пытается извлечь для себя выгоду в CDMA. 1. Мы взяли амплитуду одного сигнала P1. Шум sigma^2. 2. Если мы начинаем увеличивать амплитуду P1 до P2, по классике это поднимает соотношение С/Ш, то есть природа шума аддитивна и он не увеличивается с ростом сигнала, в отличие от коэффициента многолучевого затухания. 3. Если под P2 мы подразумеваем сумму разных пользователей, то за нас говорит уже эта формула из классики CDMA: y(t) = h*x1+sum(hk*xk)+sigma, где есть основной сигнал x1, сумма сигналов остальных юзеров xk и АБГШ, что сигма не увеличивается. 4. Таким образом, подняв мощность до P2, когда мы перешли от OFDM к CDMA, мы увеличили таки соотношение сигнал/шум. Однако в CDMA есть случаи, когда сумма пользователей дает +3, а когда 0 или просто 1, равновероятны ли такие ситуации? Допустим, я пока не могу признать, что мощность сигнала сильно увеличилась, тогда получается, что есть некоторый выигрыш в суперпозиции сигналов. Без кода мы их и не разделили бы на юзеров, так как реально видим "0", когда на самом деле передается 1+1-1-1 = 0. 5. Теперь я учитываю ортогональность кодов. Получается, что за кодовую последовательность у нас в любом случае 2 пользователя дают 0-ю мощность для одного и того же кода. Если перевернуть один из кодов Уолша (*(-1)), то ортогональность сохраняется. Так как нас здесь интересует не ортогональность, а сумма, то складывая 2 функции Уолша, пусть даже одна перевернута или сразу две, мы убеждаемся, что за всю ПСП-функцию Уолша, если у нас для отдельных пользователей все было нормировано, и просто постоянно шли либо + 1, либо -1, то теперь просто вначале может быть +2 +2, а затем 0 0, мощность не меняется, вроде, и получается, что мы суммируем мощности. Для гармоник вроде все тоже самое. 6. Ок, действительно мощности сложились, S/N поднялось. Значит мы должны уменьшить мощность в то количество раз, сколько у нас пользователей. Их 4, например. Значит уменьшили мощность суммарного сигнала в 4-ре раза. Вроде бы не изменилось ничего по сравнению с OFDM, просто несколько параллельных кодированных потоков в канале связи. 7. Рассмотрим сами коды. Мы взяли 4-ре. Мы можем передать более 4-х пользователей по этой технологии? Есть ли еще ортогональные коды длиной 4 кроме тех, что на картинке. Я решил, что нет, может поправьте меня... Тогда получается, что мы сейчас не в стандартах, и можем сами задавать скорость обмена данными. А давайте предположим так. Кодированные данные могли бы передаваться теперь быстрее, то есть мы бы один чип (я подразумеваю, что чип - это кодированный информационный бит, поправьте, если неправ) могли бы передавать с такой же скоростью, как и информационный бит без кодирования. Как это влияет на помехоустойчивость, ну отдельный вопрос. Я хочу не так. 8. Мы один информационный бит теперь передаем в 4-ре раза дольше, а один бит кода теперь передается столько же, сколько для одного пользователя передавался информационный бит. 9. Складываем 4 пользователя, получаем, что выигрыша нет никакого, ведь 4 растянутых во времени потока в 4-ре раза в итоге дают нам прежнюю скорость, как в OFDM без юзеров. 10. А если информация растягивается в 4 раза, но пользователей у нас 6. Тогда получается выигрыш? Давайте рассмотрим код Уолша. если есть 4 состояния, то возможных комбинаций кода 16, мы могли бы пользоваться именно 16 комбинациями, но кроме 4-х остальные неортогональны... Да? Или являются перевернутыми версиями основных ортогональных 4-х последовательностей. Давайте посчитаем. 4+4 инвертированных = 8. Остальные 4+4 неортогональны. 11. Вот тут у меня был, возможно, недочет. А если псп длиной 16? Какая формула позволяет выявить, сколько в 16 битах кода Уолша содержится ортогональных кодов. И вот если больше 16, то будет же выигрыш. Если ровно 16, ок, мы разобрали этот вопрос, и с CDMA все ясно. Прошу по любому пункту сказать, бред это или нет, а то вроде я все по полочкам сейчас разложил, по крайней мере своим)) -
Есть ли усиление в CDMA?
lennen ответил lennen тема в Алгоритмы ЦОС (DSP)
Ок. Вот подробнее тогда здесь. Меня смущает, а точнее я, что-то не учитывая, считаю, что если мы сложим N-пользователей вместе, то их амплитуда будет уже больше амплитуды одного потока (NUSER = 1). Давайте рассмотрим случай, что все N-пользователей в итоге принимаются одним приемником, дескать если нам нужно просто кодовым разделением достичь какого-либо выигрыша. Амплитуда всего сигнала не возросла, так как где-то 1+(-1) может дать вообще ноль, но так-то есть амплитуды и 3 и 4 после сложения юзеров. В теории IDMA я прочитал, что соотношение сигнал-шум все же падает, типа как для одного пользователя остальные являются шумом, но я не понимаю в чем фишка для CDMA. Я по прежнему не понимаю. Если амплитуда суммарного сигнала возросла, то энергия полезного сигнала все-таки выросла. Если мы хотим ее оставить прежней, сигнал стоит нормировать, чтобы максимум был 1, а минимум - (-1). Но появляется другая вещь - тогда если мы умножаем на кодовую последовательность, то вроде как мощность и упала. Короче под вечер я немного разучился думать. В двух словах: я считал, что если мы можем спокойно выделить из суперпозиции Юзера 1, то нам не нужна уже мощность User1+User2+... Дескать выделение это некоторая магия, для которой нужна мощность такого сигнала, который только 1 пользователь. Но тогда получается, что мощность прежняя, а суммарная скорость на всех пользователях либо прежняя, либо больше... Разве не так? Все-таки Если последовательность длинная, то можем же мы найти, например, 128 ортогональных кодов в последовательности длиной, скажем, 16? Если не можем просто найти столько ортогональных кодов, то получается, что IDMA все таки переворачивает картину мира и позволяет поднять скорость. Либо подтвердите, либо где ошибаюсь?) -
Ок. Еще упорно и нундо не могу понять одну строчку: Ext[nuser][m] = SpreadSeq[j] * AppLlr[nuser][i] - Chip[nuser][m]; Я смоделировал отдельно без шумов, Ext получается 0!!!! Так как Chip и Spreaded AppLlr это одинаковые массивы. Где чего я не понял? Так то по логике турбоэквалайзера + CDMA на каждой итерации Chip должен использоваться для обновления матожидания и дисперсии, но эта строка это как-то странно.
-
Я уже почитал много чего, поэтому в точку! Но надо подробнее. Подробнее хочу понять теперь следующее: После нахождения e_ese = Chip: for ( i=0; i<_ChipLen; i++ ) { Chip[nuser][ScrambleRule[nuser][i]] = TempChip[nuser][i]; if ( Chip[nuser][ScrambleRule[nuser][i]] > 20 ) Chip[nuser][ScrambleRule[nuser][i]] = 20; if ( Chip[nuser][ScrambleRule[nuser][i]] < -20 ) Chip[nuser][ScrambleRule[nuser][i]] = -20; } происходит удаление ПСП, а затем снова операция расширения спектра с помощью ПСП. e_dec = Ext показывает функцию правдоподобия как отношения вероятностей того, что бит 1 и 0. Но так то e_dec должна быть равна нулю, тут же в коде взаимообратные операции Spreading/Despreading. Значит вся магия дейсствительно в ограничителях? if ( Chip[nuser][ScrambleRule[nuser][i]] > 20 ) Chip[nuser][ScrambleRule[nuser][i]] = 20; if ( Chip[nuser][ScrambleRule[nuser][i]] < -20 ) Chip[nuser][ScrambleRule[nuser][i]] = -20; Как лучше это понимать? Кстати, а в CDMA есть возможность 2+ раза разделять пользователей (в 2+ этапа). Допустим, сначала из потока выделил 4 пользователя, а затем из каждого еще по 4 саб-пользователя? Есть ли в этом смысл, существует ли такая техника и если да, то как она называется?
-
Есть ли усиление в CDMA?
lennen опубликовал тема в Алгоритмы ЦОС (DSP)
Есть ли усиление в CDMA? Поясню. Если мы используем CDMA, то я вижу так, что мы каждый бит представляем в виде, например, 4-х бит функции Уолша. Если пользователя 4, то получается, что каждый разделен одной из функций Уолша, которые ортогональны между собой. Получается, что фактически данные теперь отправляются в 4 раза медленнее, чем если бы мы не использовали кодовое разделение. Для суммы всех 4-х пользователей именно здесь скорость будет в 4-ре раза выше, то есть такая же, как и без разделения пользователей, то есть как будто не было бы разделения на пользователей. Если же мы можем использовать больше 4-х пользователей, то выигрыш по скорости таки будет, если не рассматривать мощности пока. Например, длина функций Уолша = 16. Это 2^16 комбинаций, n из которых ортогональны. Сдается мне, что ортогональных функций больше 16-ти, получается выигрыш. Но мощность.... А возникает еще и приятный момент с мощностью, и прошу пояснить, если не так понимаю, или рассказать подробнее. Получается, что помехоустойчивость в канале связи зависит от того, насколько сигнал больше шума. Если амплитуда суммарного сигнала теперь увеличилась в 4 раза, то выходит, что мы увеличили мощность сигнала и ее надо уменьшить в 4-ре раза. Ок, уменьшим. Получаем мощность суммарного сигнала, равную мощности сигнала при отсутствии многих пользователей. Тогда получается, что соотношение сигнал/шум теперь то же, а при этом во время разделения (может тут не дошло до меня?) мы просто домножаем сигнал и еще и складываем все биты ПСП. Но этот сигнал, который мы домножаем на опорные ПСП, он зашумлен ровно также, как и сигнал без разделения пользователей. Что получается, действительно это дает усиление? То есть CDMA, если ее использовать для 1-го пользователя, дает выигрыш в помехоустойчивости? Или я не все учитываю? Я слышал, что есть такое понятие вообще, как кодовое усиление. Но помню еще, что вроде усиление то как раз и происходит за счет снижения скорости передачи данных. Чело в CDMA я не вижу. Прошу пояснить. Логично, если бы была такая лазейка, то зачем бороться за каждый дБ. Что-то тут явно не так. Прошу помочь понять. Либо это же нереально крутое свойство, как и MIMO технологии и тп... -
Если это сильно сложно, давайте по порядку теперь, общий вопрос я изложил, а теперь на понимание. 1. Зачем при разделении двух и более сигналов, сложенных друг с другом, используется ковариация? 2. Как участвует функция правдоподобия при разделении сигналов? Я понимаю, что функция правдоподобия позволяет понять, насколько правдоподобно, что апостериорная статистическая информация близка к тем или иным априорным распределением. Но при чем тут может быть разделение сигналов?
-
Задача такая. Я ее сам ставлю, не подумайте, что не разобравшись обращаюсь, но хотел бы просто небольшое Ваше мнение услышать У нас есть 1. Генератор данных для N пользователей- 2. OFDM-модем. 3. Канал связи с импульсной характеристикой. 4. Приемник. В приемнике метод максимума функции правдоподобия и итерации для разделения пользователей (IDMA). Полностью рабочий код приемника прилагаю. #include <stdio.h> #include <stdlib.h> #include <mex.h> #include <math.h> #include "define.h" #define __RRE prhs[0] // 1 #define __RIMG prhs[1] // 2 #define __SIGMA prhs[2] // 3 #define __DATALEN prhs[3] // 4 #define __CHIPLEN prhs[4] // 5 #define __PREFIX prhs[5] // 6 #define __NUSER prhs[6] // 7 #define __ITNUM prhs[7] // 8 #define __RAYRE prhs[8] // 9 #define __RAYIMG prhs[9] // 10 #define __SPREADLEN prhs[10] // 11 #define __SPREADSEQ prhs[11] // 12 #define __SCRAMBLERULEIN prhs[12] // 13 #define __APPLLROUT plhs[0] // 14 int _NUser = NUSER; int _DataLen = DATALEN; int _SpreadLen = SPREADLEN; int _ChipLen = CHIPLEN; int _Prefix = PREFIX; int _ItNum = ITNUM; int _Block = BLOCK; int _EbNoNum = EBNONUM; double _EbNoStart = EBNOSTART; double _EbNoStep = EBNOSTEP; void kkfft(double pr[], double pi[], int n, int k, double fr[], double fi[], int l,int il) { int it,m,is,i,j,nv,l0; double p,q,s,vr,vi,poddr,poddi; for (it=0; it<=n-1; it++) { m=it; is=0; for (i=0; i<=k-1; i++) { j=m/2; is=2*is+(m-2*j); m=j;} fr[it]=pr[is]; fi[it]=pi[is]; } pr[0]=1.0; pi[0]=0.0; p=6.283185306/(1.0*n); pr[1]=cos(p); pi[1]=-sin(p); if (l!=0) pi[1]=-pi[1]; for (i=2; i<=n-1; i++) { p=pr[i-1]*pr[1]; q=pi[i-1]*pi[1]; s=(pr[i-1]+pi[i-1])*(pr[1]+pi[1]); pr[i]=p-q; pi[i]=s-p-q; } for (it=0; it<=n-2; it=it+2) { vr=fr[it]; vi=fi[it]; fr[it]=vr+fr[it+1]; fi[it]=vi+fi[it+1]; fr[it+1]=vr-fr[it+1]; fi[it+1]=vi-fi[it+1]; } m=n/2; nv=2; for (l0=k-2; l0>=0; l0--) { m=m/2; nv=2*nv; for (it=0; it<=(m-1)*nv; it=it+nv) for (j=0; j<=(nv/2)-1; j++) { p=pr[m*j]*fr[it+j+nv/2]; q=pi[m*j]*fi[it+j+nv/2]; s=pr[m*j]+pi[m*j]; s=s*(fr[it+j+nv/2]+fi[it+j+nv/2]); poddr=p-q; poddi=s-p-q; fr[it+j+nv/2]=fr[it+j]-poddr; fi[it+j+nv/2]=fi[it+j]-poddi; fr[it+j]=fr[it+j]+poddr; fi[it+j]=fi[it+j]+poddi; } } if (l!=0) for (i=0; i<=n-1; i++) { fr[i]=fr[i]/(1.0*n); fi[i]=fi[i]/(1.0*n); } if (il!=0) for (i=0; i<=n-1; i++) { pr[i]=sqrt(fr[i]*fr[i]+fi[i]*fi[i]); if (fabs(fr[i])<0.000001*fabs(fi[i])) { if ((fi[i]*fr[i])>0) pi[i]=90.0; else pi[i]=-90.0; } else pi[i]=atan(fi[i]/fr[i])*360.0/6.283185306; } return; } void Receiver( double rRe[CONVLEN(PREFIX)], //*in 1 double rImg[CONVLEN(PREFIX)], //*in 2 double sigma, // in 3 int _DataLen, // in 4 int _ChipLen, // in 5 int _Prefix, // in 6 int _NUser, // in 7 int _ItNum, // in 8 double RayRe[DENULLIFY(PREFIX)], //*in 9 double RayImg[DENULLIFY(PREFIX)], //*in 10 int _SpreadLen, // in 11 double SpreadSeq [SPREADLEN], //*in 12 int ScrambleRuleIn [FULLCODDATA], //*in 13 double AppLlrOut [FULLDATA]) //*in 14 { int i, j, m, nuser, it, index, _tmp = 0; double s2 = sigma * sigma; double Chip [NUSER][CHIPLEN] = {0}; double RCPrRe[CHIPLEN/2] = {0}; // RCP stands for remove cyclic prefix double RCPrImg[CHIPLEN/2] = {0}; double FFTrRe[CHIPLEN/2] = {0}; // Received symbols after OFDM demodulation double FFTrImg[CHIPLEN/2] = {0}; double CovX[NUSER][CHIPLEN/2][2][2] = {0}; double MeanLRe[NUSER][CHIPLEN/2] = {0}; double MeanLImg[NUSER][CHIPLEN/2] = {0}; double MeanrRe[CHIPLEN/2] = {0}; double MeanrImg[CHIPLEN/2] = {0}; double MeanXRe[NUSER][CHIPLEN/2] = {0}; //mean value for each chip double MeanXImg[NUSER][CHIPLEN/2] = {0}; double MeanLHRe[NUSER][CHIPLEN/2] = {0}; double MeanLHImg[NUSER][CHIPLEN/2] = {0}; double rkHRe[NUSER][CHIPLEN/2] = {0}; //rkH means rk head double rkHImg[NUSER][CHIPLEN/2] = {0}; double Temp[NUSER][CHIPLEN/2][2][2] = {0}; //for some matrix calculation double CovL[NUSER][CHIPLEN/2][2][2] = {0}; double Covr[CHIPLEN/2][2][2] = {0}; double CovLH[NUSER][CHIPLEN/2][2][2] = {0}; //LH means L head double ChipRe[NUSER][CHIPLEN/2] = {0}; double ChipImg[NUSER][CHIPLEN/2] = {0}; double TempChip[NUSER][CHIPLEN] = {0}; double Ext[NUSER][CHIPLEN] = {0}; double R[NUSER][CHIPLEN/2][2][2] = {0}; double RT[NUSER][CHIPLEN/2][2][2] = {0}; //T means transpose double HRe [NUSER][CHIPLEN/2] = {0}; double HImg [NUSER][CHIPLEN/2] = {0}; double _HRe [CHIPLEN/2] = {0}; double _HImg [CHIPLEN/2] = {0}; double AppLlr[NUSER][DATALEN] = {0}; int ScrambleRule[NUSER][CHIPLEN] = {0}; for( nuser=0; nuser<_NUser; nuser++ ) for( i=0; i<_ChipLen; i++ ) ScrambleRule[nuser][i] = ScrambleRuleIn[(nuser * _ChipLen) + i]; for( i=0; i<_ChipLen/2; i++ ) { _HRe[i] = 0; _HImg[i] = 0; } for( i=0; i<_ChipLen/2; i++ ) { if ( _Prefix == 0 ) { j=0; _HRe[i] += RayRe[0]*cos(6.283185307*i*j/_ChipLen*2) + RayImg[0]*sin(6.283185307*i*j/_ChipLen*2); _HImg[i] += -RayRe[0]*sin(6.283185307*i*j/_ChipLen*2) + RayImg[0]*cos(6.283185307*i*j/_ChipLen*2); } if ( _Prefix > 0 ) { for( j=0; j<DENULLIFY(_Prefix); j++ ) { _HRe[i] += RayRe[j]*cos(6.283185307*i*j/_ChipLen*2) + RayImg[j]*sin(6.283185307*i*j/_ChipLen*2); _HImg[i] += -RayRe[j]*sin(6.283185307*i*j/_ChipLen*2) + RayImg[j]*cos(6.283185307*i*j/_ChipLen*2); } } } for( nuser=0; nuser<_NUser; nuser++ ) for( i=0; i<(_ChipLen/2); i++ ) { HRe [nuser][i] = _HRe[i]; HImg [nuser][i] = _HImg[i]; } for( nuser=0; nuser<_NUser; nuser++ ) { for( i=0; i<_ChipLen/2; i++ ) { R[nuser][i][0][0] = HRe[nuser][i]; R[nuser][i][0][1] = -HImg[nuser][i]; R[nuser][i][1][0] = HImg[nuser][i]; R[nuser][i][1][1] = HRe[nuser][i]; RT[nuser][i][0][0] = R[nuser][i][0][0]; RT[nuser][i][0][1] = R[nuser][i][1][0]; RT[nuser][i][1][0] = R[nuser][i][0][1]; RT[nuser][i][1][1] = R[nuser][i][1][1]; } } // Remove cyclic perfix & cyclic for ( i=0; i<_ChipLen/2; i++ ) { RCPrRe[i] = rRe[i+_Prefix]; RCPrImg[i] = rImg[i+_Prefix]; } // Get index for FFT and IFFT, where 2^index=_ChipLen/2 (расчет log2()) очень интересный способ) i = _ChipLen/2; index=0; while (i != 1) { i = i/2; index += 1; } // FFT kkfft (RCPrRe,RCPrImg,_ChipLen/2,index,FFTrRe,FFTrImg,0,0); // Normalization for ( i=0; i<(_ChipLen/2); i++ ) { FFTrRe[i] = FFTrRe[i]/pow(_ChipLen/2,0.5); FFTrImg[i] = FFTrImg[i]/pow(_ChipLen/2,0.5); } for( nuser=0; nuser<_NUser; nuser++ ) for( i=0; i<(_ChipLen/2); i++ ) { MeanXRe[nuser][i] = 0; MeanXImg[nuser][i] = 0; } for( i=0; i<(_ChipLen/2); i++ ) { MeanrRe[i] = 0; MeanrImg[i] = 0; } for( i=0; i<(_ChipLen/2); i++ ) for( nuser=0; nuser<_NUser; nuser++ ) { MeanrRe[i] += ( HRe[nuser][i]*MeanXRe[nuser][i] - HImg[nuser][i]*MeanXImg[nuser][i] ); MeanrImg[i] += ( HRe[nuser][i]*MeanXImg[nuser][i] + HImg[nuser][i]*MeanXRe[nuser][i] ); } for( i=0; i<(_ChipLen/2); i++ ) { Covr[i][0][0] = 0; Covr[i][0][1] = 0; Covr[i][1][0] = 0; Covr[i][1][1] = 0; } for( nuser=0; nuser<_NUser; nuser++ ) for( i=0; i<(_ChipLen/2); i++ ) { CovX[nuser][i][0][0] = 1; CovX[nuser][i][0][1] = 0; CovX[nuser][i][1][0] = 0; CovX[nuser][i][1][1] = 1; } for( i=0; i<(_ChipLen/2); i++ ) for( nuser=0; nuser<_NUser; nuser++ ) { Temp[nuser][i][0][0] = R[nuser][i][0][0]*CovX[nuser][i][0][0] + R[nuser][i][0][1]*CovX[nuser][i][1][0]; Temp[nuser][i][0][1] = R[nuser][i][0][0]*CovX[nuser][i][0][1] + R[nuser][i][0][1]*CovX[nuser][i][1][1]; Temp[nuser][i][1][0] = R[nuser][i][1][0]*CovX[nuser][i][0][0] + R[nuser][i][1][1]*CovX[nuser][i][1][0]; Temp[nuser][i][1][1] = R[nuser][i][1][0]*CovX[nuser][i][0][1] + R[nuser][i][1][1]*CovX[nuser][i][1][1]; Covr[i][0][0] += Temp[nuser][i][0][0]*RT[nuser][i][0][0] + Temp[nuser][i][0][1]*RT[nuser][i][1][0]; Covr[i][0][1] += Temp[nuser][i][0][0]*RT[nuser][i][0][1] + Temp[nuser][i][0][1]*RT[nuser][i][1][1]; Covr[i][1][0] += Temp[nuser][i][1][0]*RT[nuser][i][0][0] + Temp[nuser][i][1][1]*RT[nuser][i][1][0]; Covr[i][1][1] += Temp[nuser][i][1][0]*RT[nuser][i][0][1] + Temp[nuser][i][1][1]*RT[nuser][i][1][1]; } for( i=0; i<(_ChipLen/2); i++ ) { Covr[i][0][0] += s2; Covr[i][1][1] += s2; } for( it=0; it<_ItNum; it++ ) for( nuser=0; nuser<_NUser; nuser++ ) { // Produce the LLR values for the de-interleaved chip sequence. for( i=0; i<(_ChipLen/2); i++ ) { //(39/u) MeanLRe[nuser][i] = MeanrRe[i] - HRe[nuser][i]*MeanXRe[nuser][i] + HImg[nuser][i]*MeanXImg[nuser][i]; MeanLImg[nuser][i] = MeanrImg[i] - HRe[nuser][i]*MeanXImg[nuser][i] - HImg[nuser][i]*MeanXRe[nuser][i]; //(38/u) MeanLHRe[nuser][i] = HRe[nuser][i]*MeanLRe[nuser][i] + HImg[nuser][i]*MeanLImg[nuser][i]; MeanLHImg[nuser][i] = HRe[nuser][i]*MeanLImg[nuser][i] - HImg[nuser][i]*MeanLRe[nuser][i]; //(35) rkHRe[nuser][i] = HRe[nuser][i]*FFTrRe[i] + HImg[nuser][i]*FFTrImg[i]; rkHImg[nuser][i] = HRe[nuser][i]*FFTrImg[i] - HImg[nuser][i]*FFTrRe[i]; //(39/d/1) Temp[nuser][i][0][0] = R[nuser][i][0][0]*CovX[nuser][i][0][0] + R[nuser][i][0][1]*CovX[nuser][i][1][0]; Temp[nuser][i][0][1] = R[nuser][i][0][0]*CovX[nuser][i][0][1] + R[nuser][i][0][1]*CovX[nuser][i][1][1]; Temp[nuser][i][1][0] = R[nuser][i][1][0]*CovX[nuser][i][0][0] + R[nuser][i][1][1]*CovX[nuser][i][1][0]; Temp[nuser][i][1][1] = R[nuser][i][1][0]*CovX[nuser][i][0][1] + R[nuser][i][1][1]*CovX[nuser][i][1][1]; //(39/d/2) CovL[nuser][i][0][0] = Covr[i][0][0] - Temp[nuser][i][0][0]*RT[nuser][i][0][0] - Temp[nuser][i][0][1]*RT[nuser][i][1][0]; CovL[nuser][i][0][1] = Covr[i][0][1] - Temp[nuser][i][0][0]*RT[nuser][i][0][1] - Temp[nuser][i][0][1]*RT[nuser][i][1][1]; CovL[nuser][i][1][0] = Covr[i][1][0] - Temp[nuser][i][1][0]*RT[nuser][i][0][0] - Temp[nuser][i][1][1]*RT[nuser][i][1][0]; CovL[nuser][i][1][1] = Covr[i][1][1] - Temp[nuser][i][1][0]*RT[nuser][i][0][1] - Temp[nuser][i][1][1]*RT[nuser][i][1][1]; //(38/d/1) Temp[nuser][i][0][0] = RT[nuser][i][0][0]*CovL[nuser][i][0][0] + RT[nuser][i][0][1]*CovL[nuser][i][1][0]; Temp[nuser][i][0][1] = RT[nuser][i][0][0]*CovL[nuser][i][0][1] + RT[nuser][i][0][1]*CovL[nuser][i][1][1]; Temp[nuser][i][1][0] = RT[nuser][i][1][0]*CovL[nuser][i][0][0] + RT[nuser][i][1][1]*CovL[nuser][i][1][0]; Temp[nuser][i][1][1] = RT[nuser][i][1][0]*CovL[nuser][i][0][1] + RT[nuser][i][1][1]*CovL[nuser][i][1][1]; //(38/d/2) CovLH[nuser][i][0][0] = Temp[nuser][i][0][0]*R[nuser][i][0][0] + Temp[nuser][i][0][1]*R[nuser][i][1][0]; CovLH[nuser][i][0][1] = Temp[nuser][i][0][0]*R[nuser][i][0][1] + Temp[nuser][i][0][1]*R[nuser][i][1][1]; CovLH[nuser][i][1][0] = Temp[nuser][i][1][0]*R[nuser][i][0][0] + Temp[nuser][i][1][1]*R[nuser][i][1][0]; CovLH[nuser][i][1][1] = Temp[nuser][i][1][0]*R[nuser][i][0][1] + Temp[nuser][i][1][1]*R[nuser][i][1][1]; //(37) ChipRe[nuser][i] = 2 * (pow(HRe[nuser][i],2)+pow(HImg[nuser][i],2)) * ( rkHRe[nuser][i] - MeanLHRe[nuser][i] ) / CovLH[nuser][i][0][0]; ChipImg[nuser][i] = 2 * (pow(HRe[nuser][i],2)+pow(HImg[nuser][i],2)) * ( rkHImg[nuser][i] - MeanLHImg[nuser][i] ) / CovLH[nuser][i][1][1]; } for ( i=j=m=0; i<_ChipLen; i++ ) { if ( i % 2 == 0 ) TempChip[nuser][i] = ChipRe[nuser][j++]; else if ( i % 2 == 1 ) TempChip[nuser][i] = ChipImg[nuser][m++]; } for ( i=0; i<_ChipLen; i++ ) { Chip[nuser][ScrambleRule[nuser][i]] = TempChip[nuser][i]; if ( Chip[nuser][ScrambleRule[nuser][i]] > 20 ) Chip[nuser][ScrambleRule[nuser][i]] = 20; if ( Chip[nuser][ScrambleRule[nuser][i]] < -20 ) Chip[nuser][ScrambleRule[nuser][i]] = -20; } // De-spreading operation. for( m=i=0; i<_DataLen; i++ ) { AppLlr[nuser][i] = SpreadSeq[0] * Chip[nuser][m++]; for( j=1; j<_SpreadLen; j++ ) AppLlr[nuser][i] += SpreadSeq[j] * Chip[nuser][m++]; } // Data Reinterpritation for( j=0; j<_NUser; j++ ) for( i=0; i<_DataLen; i++ ) AppLlrOut[(j * _DataLen) + i] = AppLlr[j][i]; // Feed the AppLlr to decoder, if there is a FEC codec in the system. // Spreading operation: Produce the extrinsic LLR for each chip for( m=i=0; i<_DataLen; i++ ) for( j=0; j<_SpreadLen; j++, m++ ) Ext[nuser][m] = SpreadSeq[j] * AppLlr[nuser][i] - Chip[nuser][m]; // Update the statistic variable together with the interleaving process. for( i=0; i<(_ChipLen/2); i++ ) { MeanXRe[nuser][i] = tanh( Ext[nuser][ScrambleRule[nuser][i*2]] / 2 ); MeanXImg[nuser][i] = tanh( Ext[nuser][ScrambleRule[nuser][i*2+1]] / 2 ); CovX[nuser][i][0][0] = 1.0 - pow(MeanXRe[nuser][i],2); CovX[nuser][i][1][1] = 1.0 - pow(MeanXImg[nuser][i],2); } for( i=0; i<(_ChipLen/2); i++ ) { MeanrRe[i] = 0; MeanrImg[i] = 0; for( j=0; j<_NUser; j++ ) { MeanrRe[i] += HRe[j][i]*MeanXRe[j][i] - HImg[j][i]*MeanXImg[j][i]; MeanrImg[i] += HRe[j][i]*MeanXImg[j][i] + HImg[j][i]*MeanXRe[j][i]; } Covr[i][0][0] = sigma*sigma; Covr[i][0][1] = 0; Covr[i][1][0] = 0; Covr[i][1][1] = sigma*sigma; for( j=0; j<_NUser; j++ ) { Temp[j][i][0][0] = R[j][i][0][0]*CovX[j][i][0][0] + R[j][i][0][1]*CovX[j][i][1][0]; Temp[j][i][0][1] = R[j][i][0][0]*CovX[j][i][0][1] + R[j][i][0][1]*CovX[j][i][1][1]; Temp[j][i][1][0] = R[j][i][1][0]*CovX[j][i][0][0] + R[j][i][1][1]*CovX[j][i][1][0]; Temp[j][i][1][1] = R[j][i][1][0]*CovX[j][i][0][1] + R[j][i][1][1]*CovX[j][i][1][1]; Covr[i][0][0] += Temp[j][i][0][0]*RT[j][i][0][0] + Temp[j][i][0][1]*RT[j][i][1][0]; Covr[i][0][1] += Temp[j][i][0][0]*RT[j][i][0][1] + Temp[j][i][0][1]*RT[j][i][1][1]; Covr[i][1][0] += Temp[j][i][1][0]*RT[j][i][0][0] + Temp[j][i][1][1]*RT[j][i][1][0]; Covr[i][1][1] += Temp[j][i][1][0]*RT[j][i][0][1] + Temp[j][i][1][1]*RT[j][i][1][1]; } } } } /* main function that interfaces with MATLAB */ void mexFunction( int nlhs, mxArray *plhs[], int nrhs, const mxArray *prhs[] ) { double *rre_double; double *rimg_double; double *rayre_double; double *rayimg_double; double *spreadseq_double; double *scramblerule_double; double *appllrout_double; // Получаем информационные и служебные данные rre_double = mxGetPr(__RRE); double rre [CONVLEN(PREFIX)]; for (int i = 0; i < CONVLEN(PREFIX); i++) rre[i] = rre_double[i]; rimg_double = mxGetPr(__RIMG); double rimg [CONVLEN(PREFIX)]; for (int i = 0; i < CONVLEN(PREFIX); i++) rimg[i] = rimg_double[i]; rayre_double = mxGetPr(__RAYRE); double rayre [DENULLIFY(PREFIX)]; for (int i = 0; i < DENULLIFY(PREFIX); i++) rayre[i] = rayre_double[i]; rayimg_double = mxGetPr(__RAYIMG); double rayimg [DENULLIFY(PREFIX)]; for (int i = 0; i < DENULLIFY(PREFIX); i++) rayimg[i] = rayimg_double[i]; spreadseq_double = mxGetPr(__SPREADSEQ); double spreadseq [SPREADLEN]; for (int i = 0; i < SPREADLEN; i++) spreadseq[i] = spreadseq_double[i]; scramblerule_double = mxGetPr(__SCRAMBLERULEIN); int scramblerule [FULLCODDATA]; for (int i = 0; i < FULLCODDATA; i++) scramblerule[i] = (int) scramblerule_double[i]; double sigma = (double) *mxGetPr(__SIGMA); int datalen = (int) *mxGetPr(__DATALEN); int chiplen = (int) *mxGetPr(__CHIPLEN); int prefix = (int) *mxGetPr(__PREFIX); int nuser = (int) *mxGetPr(__NUSER); int itnum = (int) *mxGetPr(__ITNUM); int spreadlen = (int) *mxGetPr(__SPREADLEN); double appllrout [FULLDATA]; Receiver( rre, rimg, sigma, datalen, chiplen, prefix, nuser, itnum, rayre, rayimg, spreadlen, spreadseq, scramblerule, appllrout); /* Передаем в Матлаб данные */ __APPLLROUT = mxCreateDoubleMatrix(FULLDATA, 1, mxREAL); appllrout_double = mxGetPr(__APPLLROUT); for ( int i = 0; i < FULLDATA; i++ ) appllrout_double[i] = appllrout[i]; return; } Этот код я хочу понять и правильно описать своими словами. Это .cpp файл в проекте, по которому создается mex файл для Matlab. В коде на вход подаются комплексные данные, представляющие собой сумму данных N-пользователей. Например, если передавались 32 бита для каждого из 2х пользователей, то в итоге надо передать 64 бита, с ПСП это 64*16 = 1024 бит, после модуляции у нас 512 выборок, так как 2 пользователя, мы сложили 256+256 и на приемник поступает 256 выборок + длина ЦП, то есть 266, например. Вопрос такой, там в коде есть ковариационные матрицы, итеративный метод и расчет максимума функции правдоподобия при разделении. Вам знаком этот подход? О нем можно где-то почитать? Как бы Вы в двух словах могли это описать, если задача понятна? Хочу понять физику явления, зачем это все и как максимум правдоподобия на практике помогает разделить суперпозицию сигналов. Чтобы было проще, сейчас я могу объяснить примерно так. Мы можем разделить один сигнал на несколько, используя один из 9 методов (9+), куда входят сингулярный анализ, метод независимых компонент (ICA), метод главных компонент. Однако так я подхожу к вопросу издалека. Эти методы разработаны для разделения звуковых сигналов, что используется, например, в Dolby Digital, когда нужно выделить разные музыкальные инструменты из дорожки. В каких-то из методов используются итерации, но зачем? Я еще дохожу. В ICA находится ковариационная зависимость, а разделить сигналы можно только тогда, когда есть избыток информации, классика - это у нас несколько микрофонов или приемных антенн. Я начал разбираться и понял (еще понимаю), что в CPP, который прислал, там избыток за счет того, что мы знаем импульсную характеристику канала связи (эквалайзер с нулевым усилием (ZF)). И фактически здесь для разделения используется что-то подобное, а потом та же ковариационная матрица, расчет правдоподобия и от итерации к итерации мы находим максимум функции правдоподобия, что позволяет нам разделить сигналы. По коду я еще вижу, что сначала данные разделяются, а потом уже декодируются, а ПСП, дескать, мы знаем, и они подаются на вход Приемника. appllr = ReceiverMx(rreout, rimgout, sigma, datalen, chiplen, prefix, nuser, itnum, rayre, rayimg, spreadlen, spreadseq, scramblerule); Это строчка из Матлаб, scramblerule и spreadseq говорят сами за себя. И после разделения и избавления от ПСП (получаем данные для N-пользователей) мы заново на конце итерации оцениваем статистические параметры, при чем для этого используются все те же ковариационные матрицы... Но в последних нескольких предложениях я еще не понял, что сказал, можете навести на мысль? Все таки как объяснить, 1. зачем мы находим среднее значение Mean, 2. зачем нужны ковариационные матрицы, 3. избыток какой информации в данном коде? Я прав про то, что вся фишка в том, что мы знаем комплексную импульсную характеристику канала связи H? 4. как максимум функции правдоподобия позволяет нам один сигнал разделить на 2 и более, да еще и так в итоге, что мы находим данные для каждого пользователя? 5. зачем мы комплексные коэффициенты импульсной характеристики RayRe+1i*RayImg приводим в таком гармоническом виде? (ChipLen - длина чипа, для вышеописанной частной ситуации это 1024 бита/ 2 пользователя = 512. Или же 32*16 (длина ПСП) = 512): for( i=0; i<_ChipLen/2; i++ ) { if ( _Prefix == 0 ) { j=0; _HRe[i] += RayRe[0]*cos(6.283185307*i*j/_ChipLen*2) + RayImg[0]*sin(6.283185307*i*j/_ChipLen*2); _HImg[i] += -RayRe[0]*sin(6.283185307*i*j/_ChipLen*2) + RayImg[0]*cos(6.283185307*i*j/_ChipLen*2); } if ( _Prefix > 0 ) { for( j=0; j<DENULLIFY(_Prefix); j++ ) { _HRe[i] += RayRe[j]*cos(6.283185307*i*j/_ChipLen*2) + RayImg[j]*sin(6.283185307*i*j/_ChipLen*2); _HImg[i] += -RayRe[j]*sin(6.283185307*i*j/_ChipLen*2) + RayImg[j]*cos(6.283185307*i*j/_ChipLen*2); } } }
-
Вопросы по слепому приему сигналов
lennen опубликовал тема в Алгоритмы ЦОС (DSP)
Извиняюсь, если что-то сильно просто, а что-то наоборот усложняю, но я начитался по этой теме, и теперь охота уложить все по полочкам, а также в процессе еще некоторые вопросы поставить. Суть в том, что может быть 2 антенны на передаче, 4 на приеме, и 10 сигналов (как лучей, так и посторонних), некоторые из которых могут быть примерно одинаковой мощности. Нужно в любой момент сказать, что сигнал № 5 идет именно оттуда-то, выделить его на фоне остальных и принять. Все 10 сигналов могут быть с любыми видами модуляции, кодированием и так далее. Хотя можно условится, например, в гармонической природе сигнала, если это важно. 1. Прошу подтвердить, что для решения таких задач используются корреляционные методы хоть во времени, хоть в частотной области. А есть ли еще что-то кроме корреляционных оценок, чтобы выделить 1 сигнал на фоне другого, когда сами сигналы могут быть абсолютно любыми? 2. Где-то 3 года назад я был на семинаре Rohde and Schwarz по телевизионному оборудованию в Москве, там показали выделение лучей из всей приходящей многолучевой структуры, дескать видно мощность, задержку. Если память не изменяет, даже направление как-то понимали. Тогда я задал им пару слов и все стало у меня на места, но сейчас подзабыл. Если на векторный анализатор, скажем, пришло 4 луча, пусть одного сигнала, как можно их разделить? (на пальцах) Заранее спасибо :rolleyes: -
Вот да. Процесс итеративный. Просто здесь я предположил именно то, что использование в циклическом префиксе фаз, которые бы согласовали фазы предыдущего и следующего OFDM-символа, дало бы преимущество против фазовых скачков, искажений спектра, нарушений синхронизации и тп. Но это тогда бы уже появилось в виде алгоритмов, а я не видел, что так делают. Это может звучать глупо, но исследования делать, возможно, не имеет смысла, если здесь не очевиден выигрыш. Вот и интересуюсь, эта идея - она глупая или таки нет? Взвешивание происходит до добавления циклического префикса. Хотя информация в ЦП нас все-равно не волнует. Поэтому последний пост как раз не понял, зачем взвешивать сам ЦП? Из презентации вижу, что связано с наложением конца предыдущего символа и начала следующего. Но информация то не важна. То есть такое взвешивание позволяет скорректировать комплексный спектр? И в случае рассинхронизации не допустить резкого скачка фазы?
-
Я понимаю, что наверняка этот вопрос поднимается много где, поэтому просьба меня наставить просто, что это может быть за техника и где она есть. Либо почему ее не сделали. Но недавно пришла такая идея, что циклический префикс не должен повторять конец OFDM-символа, а должен быть таким, чтобы фаза в его конце совпадала с начальной фазой следующего OFDM-символа, а фаза в его начале совпадала с начальной фазой в конце предыдущего OFDM-символа. Почему этот вопрос имеет значение, с моей точки зрения. Скачки фазы или частоты искажают спектр, если есть хоть небольшое нарушение синхронизации.
-
1. Ок, прочитал, но просто это шикарно. Получается, что когда есть уже сгенерированные в генераторе выборки OFDM-сигнала, то нельзя менять частоту, на которой будут синтезированы гармоники?! 2. То есть эксперимент, где я пробовал вводить разное время дискретизации между выборками OFDM-сигнала в векторном генераторе - это эксперимент, в котором я нарушал ортогональность, и возможно так и не добился ортогональности поднесущих частот? 3. А насколько критично, чтобы поднесущие были ортогональными? У меня то сигнал передавался. правда, наверное, из за этого и возникали искажения, да?
-
Пытаюсь осознать Quinn. А в OFDM принцип тот же? Я так понимаю, что там же не одна гармоника, а спектр, хотя и на сравнительно узкой полосе частот в классическом случае. Я не совсем понял момент про то, куда именно вводится найденное отклонение частоты, в гетеродин? Quinn я в двух словах понял - после ДПФ нужно проверить отклонения точек созвездия и с помощью интерполяции посчитать частотную расстройку, пока так. Вот нашли мы ее, это получается, тогда уже, число в вычислительном процессоре или ПЛИС, так? Но если мы ее введем математически, разве мы уменьшим ошибку? Или так и делается и мне стоит подробнее понять? А если сам процесс компенсации происходит не через математику, то куда, все-таки, вводится найденное значение частотной расстройки?
-
Давайте, чтобы я точно понял, рассмотрим на конкретном примере. Блок ОДПФ выдает выборки, поэтому еще не важно, какой там частотный разнос. А вот дальше имеется синтезатор частоты. Если в спектре 64 гармоники + 64 комплексно сопряженные, то всего будет 128 гармоник, например. Частота дискретизации сигнала fd = 128 МГц. Тогда получим, что 128 гармоник укладываются в полосе 100 МГц. 128МГц/128 = 1 МГц. Я так понимаю, такой и будет частотный разнос. И, вроде, все ортогонально. Информация закладывается в OFDM символ целиком, поэтому если мы говорим о длительности информационного символа Ти = 0,1 мс, то это время должно быть связано с частотным разносом 1МГц. То есть мы сейчас не можем просто взять и сказать, что Ти = 0.1 мс, так? Можно подробнее тогда? То есть если я генерирую сигнал с длительностью информационного символа Ти, я не могу менять частотный разнос совсем на небольшую величину, например, на 1 кГц? Меняя при этом, например, частоту дискретизации сигнала. Хотя я немного запутался, потому что вот вопрос у меня возникает именно такой. А связь Ти с fd я понимаю, ведь если разделим Ти/128 выборок ОБПФ, получим период дискретизации Тd. Получается, с другой стороны, что частота дискретизации жестко связана с Ти. Но тогда получается, что ничего подбирать не надо, частотный разнос может быть абсолютно любым, в чем я был уверен до того, как услышал комментарий Grizzzly. Хотя это же исключительно про ортогональность, а я так понимаю, что исторически так сложилось, что ОДПФ генерирует ортогональные сигналы, и заморачиваться не надо. Поправьте, пожалуйста.
-
И тема уже обсуждалась, и вроде ответ, на первый взгляд, прост - любой частотный разнос нужен. Но еще раз и по порядку. В OFDM-сигнале поднесущие ортогональны между собой. Это означает, что интеграл от их произведения равен 0. Моделирую следующим образом, но небольшая погрешность остается, и не могу точно определиться: n = 1:100000; t = n*0.0001; f1 = 100; f2 = 160; s1 = cos(2*pi*f1*t); s2 = cos(2*pi*f2*t); plot(s1); hold on; plot(s2); sm = s1.*s2; ss = sum(sm); Разве две гармоники все время ортогональны между собой? Как это правильно доказать? Потому что помню из учебника Баскакова, что либо во временной области должен быть правильный разнос, либо в частотной... Но вроде же ортогональны только синус и косинус? Одной частоты. Просто правильно подобран временной сдвиг. А в итоге получилось, что мне доказывали недавно, что разнос между поднесущими частотами в OFDM-сигнале не может быть любым, и что он зависит в том числе от длины информационного символа в поднесущей частоте. Вернее пытались доказать, но я так и не понял. Я даже на практике когда генерировал все поднесущие частоты, мог задать любую частоту дискретизации, получая тем самым любую полосу сигнала и любой частотный разнос. По кабелю, вроде, все ок передавалось. Можете уточнить ситуацию? И вот так то, вроде, когда на отрезке укладывается нецелое число периодов гармонических сигналов, то эти сигналы неортогональны. Но я так понимаю, что обычно это не учитывается при генерации и приеме OFDM-сигнала? Там же типичная ситуация, вроде, когда в одном OFDM-символе укладывается нецелое число периодов сигнала. Или обязательно учитывается?
-
Спасибо, читаю. А, все-таки, в двух словах - можно ли напрямую измерять частоту в системе связи и вводить разницу между эталоном и измеренным значением для компенсации частотной расстройки? Какие методы существуют и как называются?