kaktus
-
Постов
73 -
Зарегистрирован
-
Посещение



-
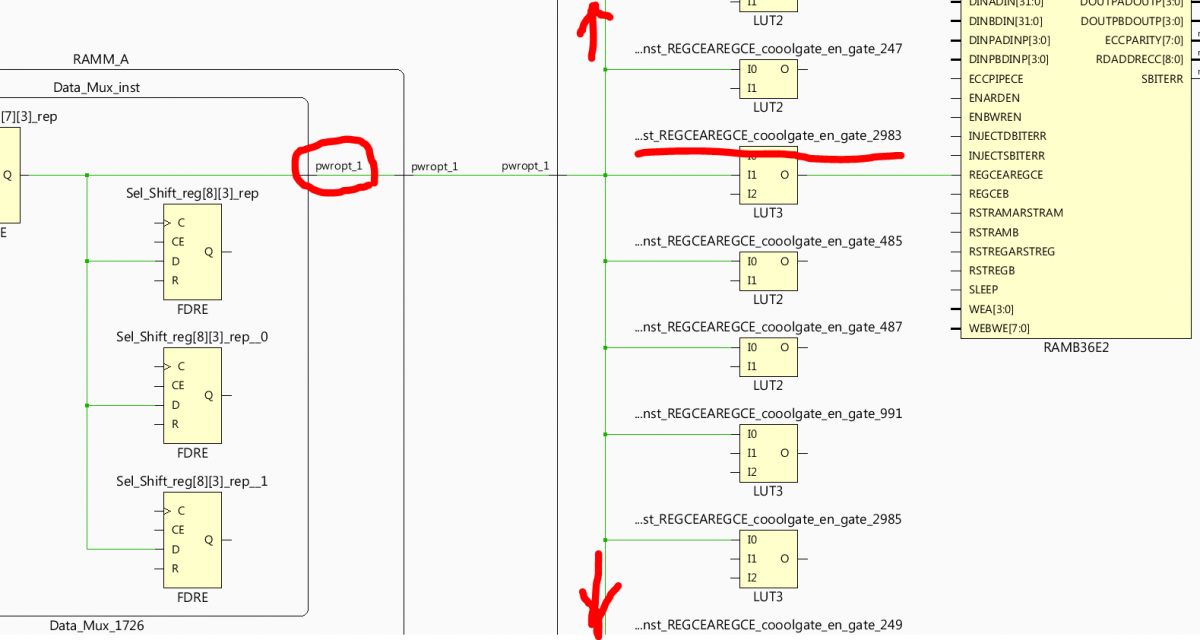
Вот иллюстрация прикола с оптимизацией питания для BRAM. Появляются цепи с характерными названиями pwropt*, *cooolgate* , на ограничения по fanout забивает, времянки в итоге не сходятся.
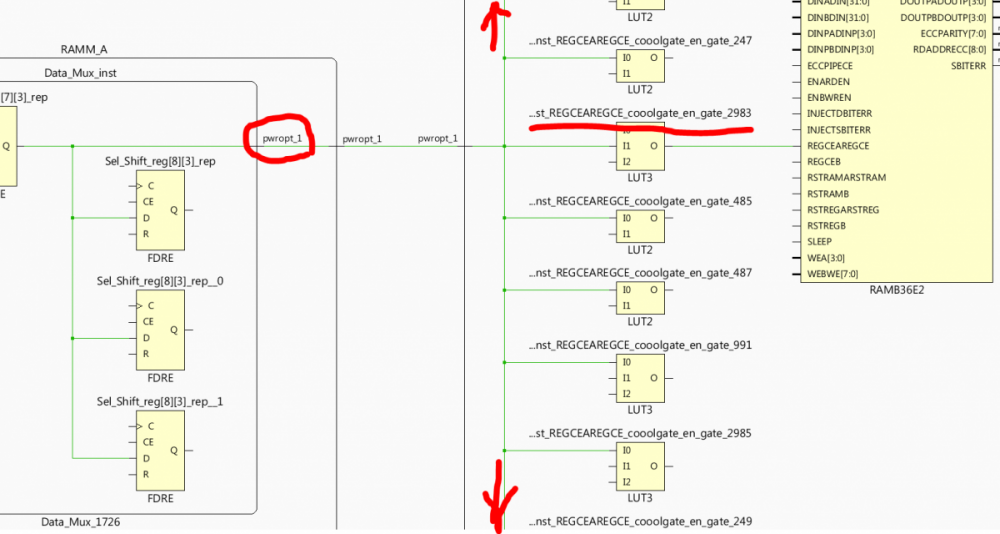
-
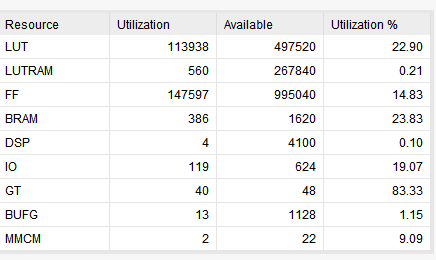
Сохранил копию проекта с которым развлекался все это время в vivado 2018.2, открыл в 2018.3, обновил IP ядра, никаких настроек не менял, нажал generate bitstream. 2018.2 размер bin : 34 138 780 ( > 32МБ) mcs: 96 024 192 (при этом меньше) По JTAG все шьется, но ПЛИС с флэшки не грузится 2018.3 размер bin : 33 307 596 ( < 32МБ) mcs: 96 686 283 (при этом больше) По JTAG все шьется, ПЛИС с флэшки грузится 32МБ = 2^25 = 33 554 432 Еще интересны результаты компиляции: сильно разное время при почти идентичной "утилизации"см. картинки
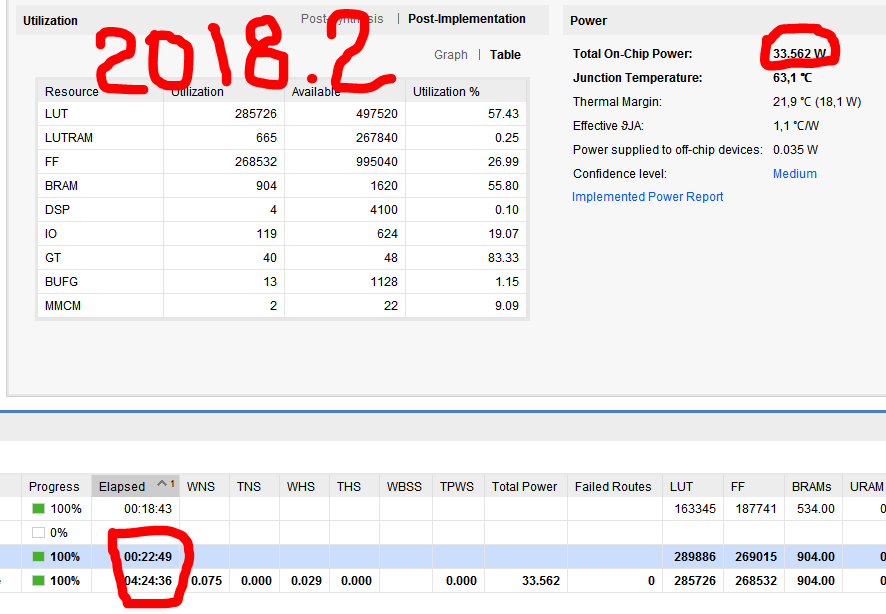
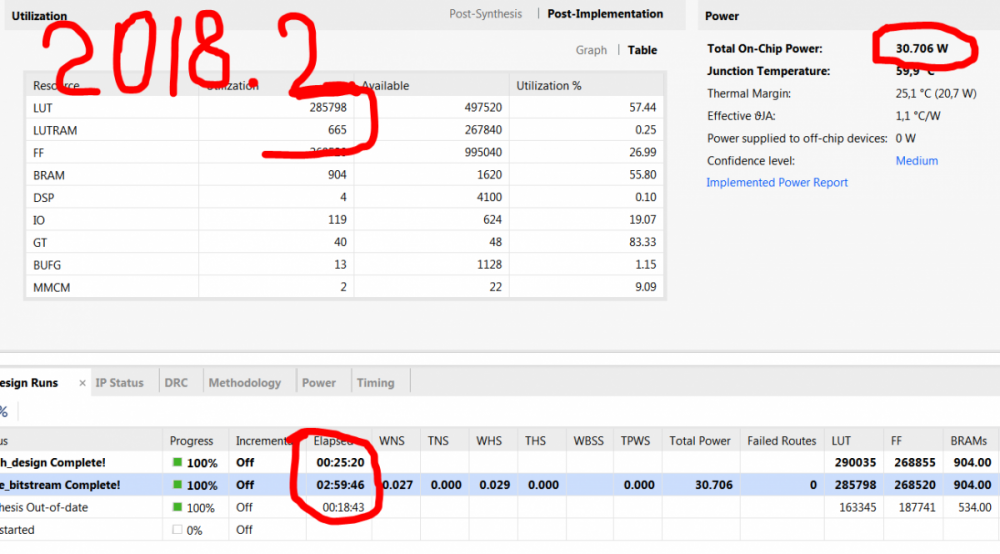
-
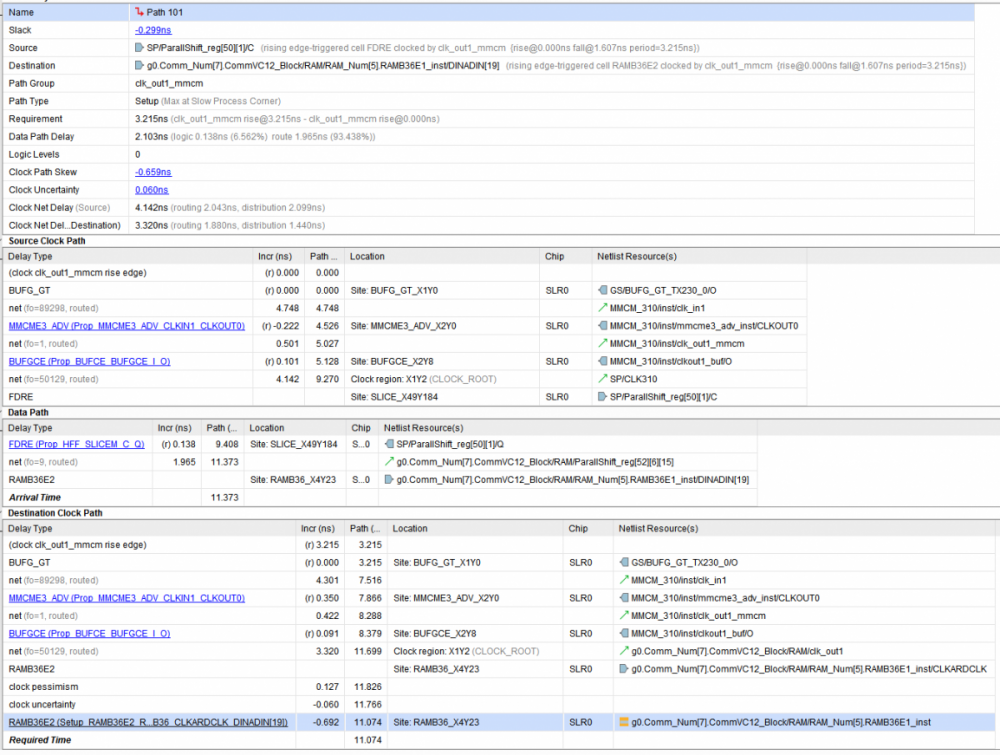
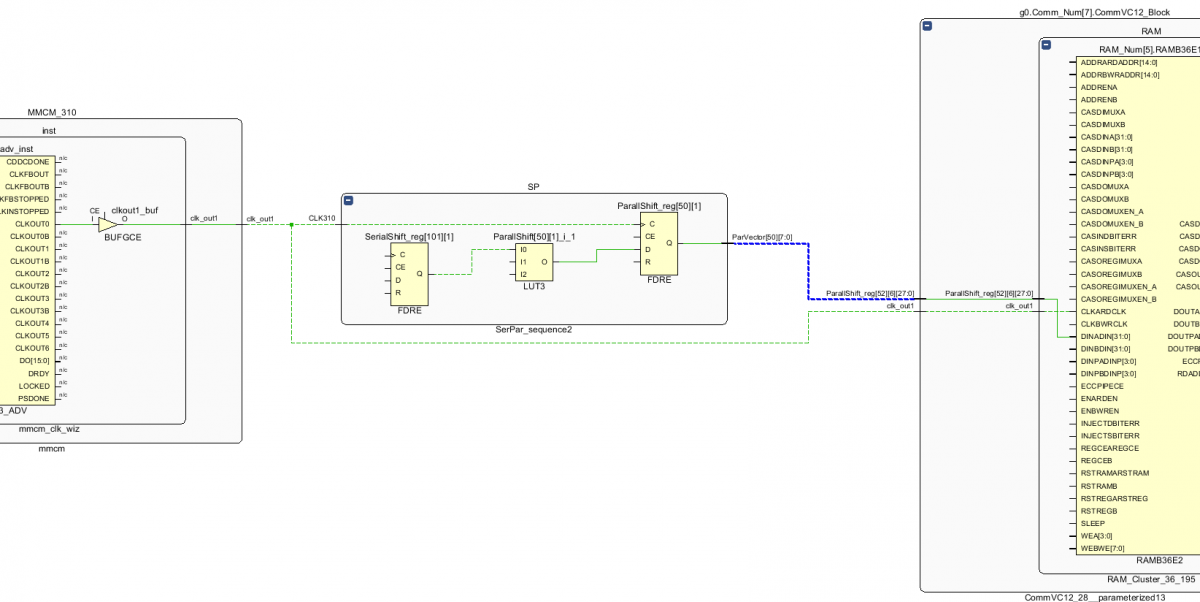
Столбец Loocation раздвинул на картинке в начале темы, но думаю следующие "веселые картинки" больше прояснят ситуацию. На картинках Тактовая, и Цепь в кристалле и схеме,на которой при задержке 2.103 и периоде 3.2 из-за разных путей тактовой Slack -0.3 И на этой тактовой должно висеть в 3 раза больше чем сейчас. Также оговорюсь, что триггеров по схеме вставлено довольно много.
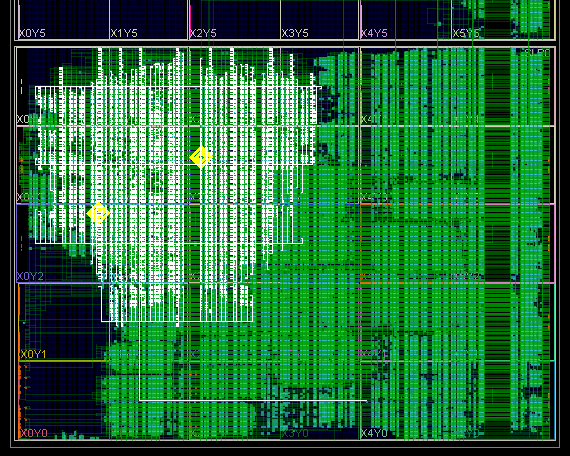

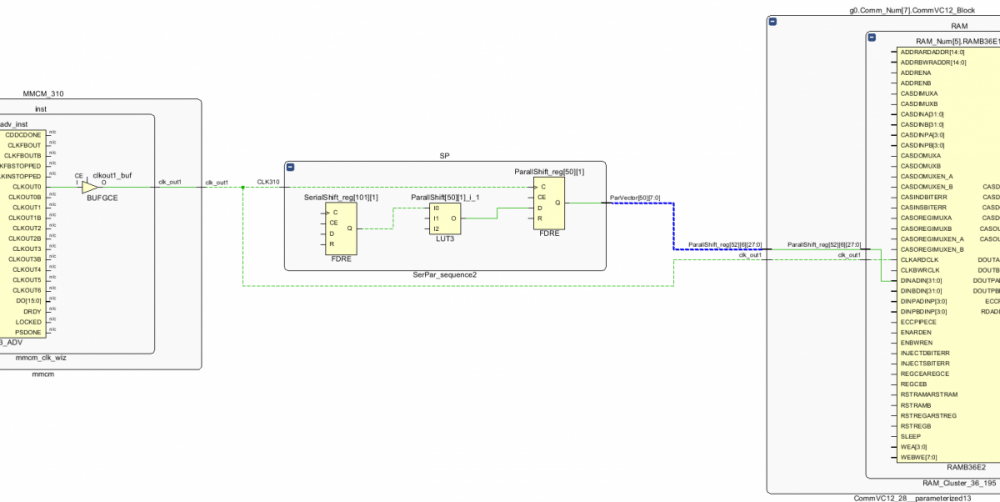
-
При довольно низком уровне загрузки кристалла проект перестал укладываться по времянкам. Львиная доля проекта работает от 2-х тактовых 155.52 и на ней же удвоенной 311.04, кое где данные пересаживаются с одной на другую. Из приведенных ниже картинок видно, что тактовые буферы практически не использованы, собственно в основном работают упомянутые 2 из них, при этом проблема вылезает из-за Clock Path Skew. У меня есть подозрение, что это можно вылечить используя хваленые "UltraScale Architecture Clocking Resources", распихав BUFG во все углы. Раньше проект разводился при заполнении около 60%, но после небольшого увеличения нагрузки на частоту 155 перестал: возникают связи между (SLR) двумя кристаллами из которых состоит ПЛИС с задержками по 15 нс, но это, видимо, проблема из другой оперы! При уменьшении количества каналов и соответственно загрузки до 15% разводится, на 20% начинает сыпаться с более высокой частоты, что в данный момент и представлено вашему вниманию. Отсюда вопросы: 1. Верно ли мое предположение про BUFG? 2. Если верно, то как это грамотно сделать, желательно не залезая в код. 3. Если не верно, то..... стратегии синтеза и разводки?...