


VladislavS
-
Постов
1 240 -
Зарегистрирован
-
Посещение
-
Победитель дней
9
Сообщения, опубликованные VladislavS
-
-
3 минуты назад, EdgeAligned сказал:
констэкспры прям в интерфейсе обязательны чтоль
Конечно!
-
32 минуты назад, EdgeAligned сказал:
А интерфейс в ×× вообще делается на абстрактном классе
Там проблема с constexpr будет. Не делают так.
33 минуты назад, EdgeAligned сказал:потому как чисто понятия интерфейса в ×× нету.
Сейчас можно концептов навесить и фактически задать требования к интерфейсу.
-
В плюсах всё гораздо проще. Код можно в описании класса писать прямо в заголовочных файлах. Количество единиц трансляции снижается до минимума автоматически.
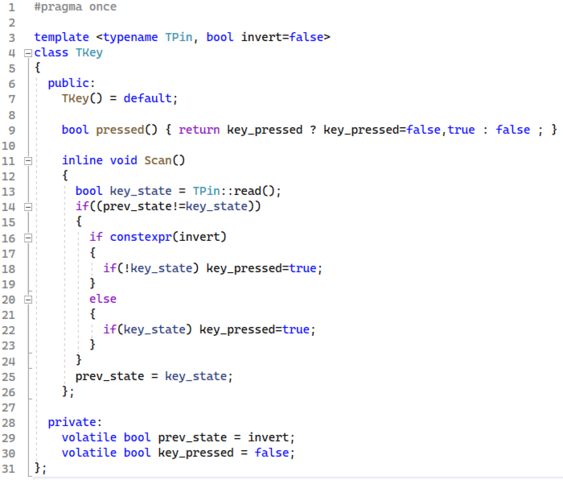
-
В данном случае всё наоборот. Память 32 бита, периферийное <32 бита. Всё одной записью обойдётся.
-
4 минуты назад, Arlleex сказал:
В принципе, может, что ему запрещает
Шина. Не даст она двум устройствам одновременно доступ.
-
14 минут назад, RR2021 сказал:
ГЛАВНЫЙ Вопрос может ли случится ситуация когда одновременно я считываю значения а DMA их записывает в эту же ячейку , и я считаю какуюнибудь белеберду ??
Не может.
4 минуты назад, HardEgor сказал:Наверное для этого надо использовать барьерные инструкции
Причём тут доступ к памяти и барьерные инструкции?
-
 1
1
-
-
Держи нас в курсе!
-
 1
1
-
-
Предать анафеме всю эту макросную муть!!!
-
А это такая народная забава пытаться сделат всё через опу, лишь бы не использовать предназначенное для этого устройство(таймер)?
-
Все попытки сделать импульс программно умрут вот тут
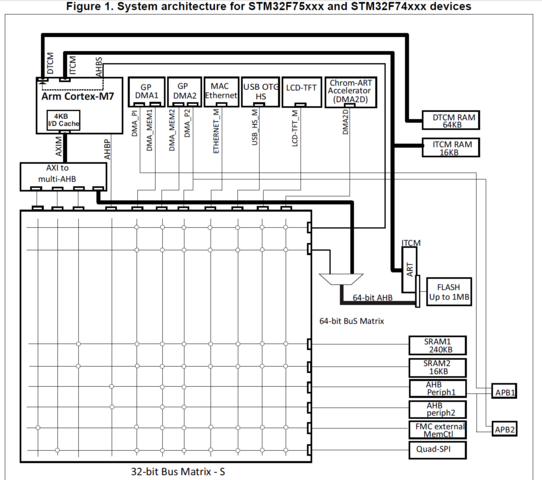
Проследите путь от CPU до GPIO (он не работает на частоте CPU) и всё поймёте. А вот таймер с ШИМ то что доктор прописал.
-
5 минут назад, AlexRayne сказал:
в чем прикол делать таблицу констант волатильной?
Если она в процессе работы перешивается, например. Чтобы компилятор не подумал, что там всегда нули как во время компиляции и не соптимизировал доступ к ней.
-
9 минут назад, razrab83 сказал:
а кто-то так делает?
А какой смысл в этом коде заложен?

Зачем count связан с sizeof('a') ?
-
45 минут назад, razrab83 сказал:
Ещё одна говноособенность иара... неинициализируемая переменная без явных указаний инитится нулём.
Глобальная по стандарту должна инититься нулём. Все остальные нет и иар это, самом собой, не делает.
-
10 минут назад, VaTiKaNeTs сказал:
но я пока не хочу сдвигать всю прошивку на 8 байт
У кортексов в таблице векторов прерываний есть пустые места. Идеальное место для хранения размера прошивки, crc и т.д.
-
На будущее, в кубе отличный конфигуратор системы тактирования. Не надо даже код генерить, а просто установить все делители и переключатели правильно и на их основе код написать.
-
Бинарник должен быть разный? Тогда это и есть условная компиляция, которая делается заданием WE_ARE_RUNNING_UNDER_DEBUGGER в одной из конфигураций.
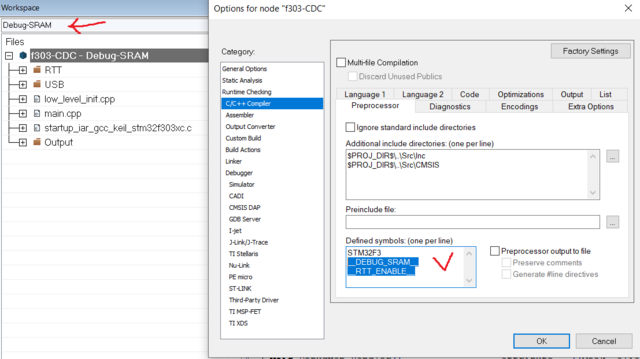
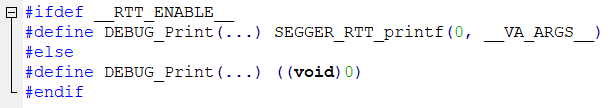
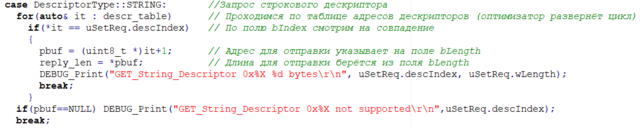
-
Бывают программы, которые работают не благодаря, а вопреки. В них главное - не спугнуть.
-
 1
1
-
1
-
-
12 минут назад, Arlleex сказал:
Ну а откуда у компилятора будет право смешать volatile-доступы в один?
Он их не совмещает, а изначально формирует так как вы описали во втором абзаце вашего сообщения.
12 минут назад, Arlleex сказал:Причем так явно, чтобы это было видно программисту при первом взгляде на исходник.
Зачем? При взгляде на исходник должно быть видно ЧТО делает код, а не КАК. Часто вы кишки printf изучаете при его использовании?
12 минут назад, Arlleex сказал:Какой пример написал автор статьи - его дело, но раз он написал последовательные обращения к GPIOC, пусть они и останутся последовательными, а никак не оптимизированными.
При такой постановке задачи и результата ноль. И выводы ложные. А реальная задача автора "мигать списком диодов".
12 минут назад, Arlleex сказал:Например, у меня бывает так, что нужно перепаковывать биты портов в структуры обмена.
Ну это оно и есть.
12 минут назад, Arlleex сказал:где метадвижок проходился сначала по списку портов, потом по списку пинов, выявлял смежные пины и т.д.
Именно так и делается. Именно поэтому нет совмещения volatile, а есть их оптимальное формирование.
-
11 минут назад, EdgeAligned сказал:
Тогда о чем?
Об ошибочном заключении, что автор статьи получил сложным способом тот же результат и поэтому делать так не имеет смысла. Имеет, просто надо более сильное кунг-фу использовать, тогда результат будет лучше.
-
Нет, я не о том как лучше ногами дрыгать. Вы неправильно поняли.
-
Задача - помигать четырьмя диодами, приведёнными в списке. На С вы решаете сами первым или вторым способом её решать. А на С++ я просто говорю "переключи состояние всех диодов из списка". Есественно, заменить первое<=>второе он не имеет права. Но сформировать одну операцию вместо трёх для решения задачи на этапе компиляции и есть джедайство.
-
-
1 час назад, Arlleex сказал:
то C++ от такой "оптимизации" тупо сел бы в лужу, ибо это два разных кода, не находите?
Не нахожу. Код автора статьи (без delay, он тут ни на что не влияет) я бы написал так.
using LEDS = PinList<PA_5,PC_5,PC_8,PC_9>; for(;;) LEDS::toggle();
Что для STM32 в процессе компиляции превратиться во что-то такое
for(;;) { // PA5 toggle if (GPIOA->ODR & (1<<5)) *((volatile uint16_t *)&GPIOA->BSRR+1) = (1<<5); else GPIOA->BSRR = (1<<5); // PC5,PC8,PC9 toggle GPIOC->BSRR = (((1<<5)|(1<<8)|(1<<9)) << 16) | (~GPIOC->ODR & ((1<<5)|(1<<8)|(1<<9))); }Естественно не в ODR ^=, ибо это неправильно. Ну и из-под ARM Compiler v6 будет как-то так
MOVS r0,#0x14 MOVW r2,#0x320 MOVW r3,#0x818 MOVT r0,#0x4800 // R0 = &GPIOA->ODR MOV r12,#0x20 MOVT r2,#0x320 MOVT r3,#0x4800 // R3 = &GPIOC->BSRR main: // if (GPIOA->ODR & (1<<5)) LDR r1,[r0,#0x00] LSLS r1,r1,#26 ITE PL // GPIOA->BSRR = (1<<5) STRPL r12,[r0,#0x04] // *((volatile uint16_t *)&GPIOA->BSRR+1) = (1<<5); STRHMI r12,[r0,#0x06] // GPIOC->BSRR = (((1<<5)|(1<<8)|(1<<9)) << 16) | (~GPIOC->ODR & ((1<<5)|(1<<8)|(1<<9))); LDR r1,[r0,#0x800] AND r1,r1,#0x320 EORS r1,r1,r2 STR r1,[r3,#0x00] B mainИ никто в лужу не сел, как ни странно.
-
В 22.04.2023 в 16:51, EdgeAligned сказал:
И в особенной степени полезно и показательно то, к чему автор статьи пришел в конце - при максимальном уровне оптимизации разницы в "выхлопе" никакой. Так что, как в той рекламе: "А если нет разницы, зачем
платитьписать больше?".Просто автор не владеет (или не владел в 2019 году) настоящим кунг-фу. Если закрыть глаза на то что нельзя через ODR ^= PIN мигать светодиодами, то соревноваться ему надо было с кодом
for(;;) { GPIOA->ODR ^= (1 << 5); GPIOC->ODR ^= (1 << 5) | (1 << 8) | (1 << 9); delay(); }Вот если бы его класс сам делал подобную оптимизацию (а это на плюсах, в отличи от си возможно), то тогда и можно было засчитывать победу.
В 21.04.2023 в 09:47, jcxz сказал:У меня лучше
 - установка/сброс/toggle пина: Pset(PIN_LED1) / Pclr(PIN_LED1) / Ptog(PIN_LED1) - всё сделано с помощью макросов, без всяких си++. А следовательно - будет иметь минимальный код независимо от уровня оптимизации (не требует максимальной оптимизации для inline-инга, как в той статье).
- установка/сброс/toggle пина: Pset(PIN_LED1) / Pclr(PIN_LED1) / Ptog(PIN_LED1) - всё сделано с помощью макросов, без всяких си++. А следовательно - будет иметь минимальный код независимо от уровня оптимизации (не требует максимальной оптимизации для inline-инга, как в той статье).
В общем случае это не так. Макросом невозможно учесть все особенности архитектуры порта контроллера. В сочетании с классами, умеющими объединять/сортировать пины в порты эффект можно получить заметный.

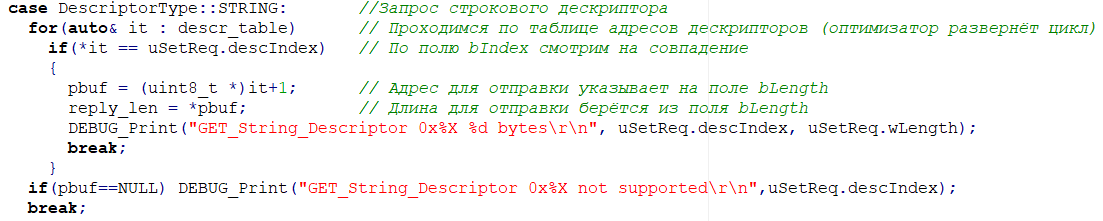
ARM Compiler 6 (LLVM/CLang): можно ли компилировать несколько файлов как один?
в Keil
Опубликовано · Пожаловаться
Так я и смотрю. Ограничение есть. Когда я об него споткнусь - вопрос только времени.