


des00
-
Постов
9 579 -
Зарегистрирован
-
Победитель дней
4
Сообщения, опубликованные des00
-
-
Я-то думал эти библиотеки уже компилированные под Альдек...первый раз пытаюсь работать с third-party stand-alone пакетами...
для пользователей которым лень самостоятельно компилировать библиотеке есть уже скомпилированые, но т.к. формат библиотек от версии к версии отличается то извольте каждый раз качать нужные либы с сайта.
А как компилировать в Альдеке отдельно библиотеки ? Сорри, не понял ваше второе предложение (насчет обычного проэкта в Альдеке который цомпилируется в бинарник)..да вроде уже сказал как, но еще раз по полочкам. Берем открытые исходные коды библиотек из IDE целевой фпга. Положим что взяли либу pipa_lib.v. Создаем в альдеке проект pipa_lib. Включаем в него файл pipa_lib.v. Компилируем. В папке проекта после компиляции будут файлы pipa_lib.lib, 0pipa_lib.mgf...3pipa_lib.mgf. Это и есть искомые вами библиотеки. Создаются они для любого проекта. Потом эту библиотеку можно сделать глобальной и использовать ее, даже без сорцов, везде где угодно.
Кстати про это красочно, с рисунками и примерами расписано в хелпе альдека. То же самое делается и для всех остальных симуляторов.
Все больше качать ничего не надо, вы слезли с библиотечной иглы производителя сорца и вашего провайдера (если у вас например 2 рубля за метр %))
Есть более простой вариант действий. Если когда либо вы скачали готовые либы, там есть как сорцы либ, так и скрипт запуска компиляции. Катайте исходники поверх и запускаете скрипт. Вуаля у вас либы именно той IDE от которой взяты библиотеки.
ЗЫ. Иногда нужно симульнуть по быстрому, а времени создавать все правильно нет. Тупо берем нужный исходник библиотеки, включаем в свой проект, компилим и вуаля все работает. Но это в хелпе не написано, это обычная логика здравого смысла.
Помните в хелпе все есть, ищите и найдете ответы. Удачи !!!
-
А,ну да. Спасибо,мультициклы уже проверил,тоже нормально.Там только имя клока нужно заменить.
я тут подумал вобще то цап какой то не сильно вам подходящий. ну смотрите tsu/th = 2.5/2нc. Т.е. предельный период обновления данных, в идеальном случае выравнивания это 4.5нс. Вы заводите его на 4.62нс. Т.е. запас на разброс выравнивания у вас всего 0.12 нс. В вашей схеме, в температуре это может вылезти боком. ИМХО если есть возможность я бы подобрал другой цап.
-
Строчки с мультициклами проверил,компилятся,но эффекта на картинке нет.А каким боком здесь мультициклы?Ведь частота клока на входе и данных на выходе одинакова.
А если такой вариант:
Тогда получим задержку на 1 такт.Но это не важно.Главное чтобы все биты шины переключались внутри одного тактового интервала,тогда Tsu и Th выполнятся,но в другом такте.
дык это и есть мультицикл, в том смысле в котором он вводится в тайм квесте, т.е. анализировать валидные данные на втором/третьем и т.д. тактовом интервале :)
Еще как вариант, правда со своими последствиями это сделать system synchronus output систему. т.е. кинуть клок на цап с фпга.
Ну в общем проблема ясна, все остальное это варианты ее решения %)
-
Спасибо!Отправил на диод.
ндя, пока проект моделировался, покопался, занятная вешь. И ведь все по даташиту %))
не будет у вас времянка сходиться, как ни пишите %)
Дело вот в чем, смотрим документ Cyclone III Device Handbook, Table 1–65. EP3C25 Column I/O Pin Output Timing Parameters for Single-Ended I/O Standards (у меня страница 401). Затем смотрим ваш проект там стоит CycloneIII C8, 2.5V, 8мА. Смотрим табличку для этого режима GCLK tCO 5.384 ns/GCLK PLL tCO 3.620 ns. Теперь смотрим ваш проект и видим что в пути от выходного триггера до пада стоит задержка порядка 3.8нс. Прям даже лучше чем по даташиту %)).
Так что все нормально, никаких чудес. Рисует TimeQuest все правильно, при перекосе клоков около 3 нс и tco около 4х ну никак не влезть в 2.5нс tsu цапа за один такт %))
Вариантов решения 2 :
1. Воспользоваться мультициклом
set_multicycle_path -from [get_clocks {ClockDac}] -to [get_clocks {virt_dac_clk}] -setup -end 3 set_multicycle_path -from [get_clocks {ClockDac}] -to [get_clocks {virt_dac_clk}] -hold -end 12. Подкрутить фазу на PLL.
ЗЫ. не забудьте для более точного анализа
create_clock -name {ClockDac} -period 4.620 [get_ports {ClockDac}] create_clock -name virt_dac_clk -period 4.620 set_clock_uncertainty -from { virt_dac_clk } -setup 0.25 derive_clock_uncertaintyЗЗЫ. для экспериментов сделайте назначение пинов, так по идее будет более правильно.
Удачи !!
-
Не понял, о каком документе речь.В mnl-sdctmq.pdf фигур нет.
речь идет о документе Quartus II TimeQuest Timing Analyzer Cookbook, там приведены 2 схемы запитки тактовой частотой, 1. от внешнего генератора и 2. от самой фпга.
В общем так, вырежте секретное из проекта, оставьте на цап какой нить счетчик на частоте 250МГц и с описанием ваших времянок киньте мне ваш проект на мыло. Мой адрес у вас вроде бы есть
РЗ. Кстати времянки могут и не выполняться %) тогда нужно будет двигать фазу клока %)
-
Стало ещё непонятней,а Data Arrival не изменилось.
такс, отставить панику, надо разложить все по полочкам.
Про регистры понятно, не заметил %)
Судя по вашим констрейнам вы используете схему запитки DAC клоком как в Figure 1–9. Chip-to-Chip Design, выше указанного документа. Это так ?
Кстати в этом документе есть ошибка я о ней уже писал, вы ее тоже совершили :) http://electronix.ru/forum/index.php?act=S...f=5&t=52323 см. пост #12
Клок логики выходного сигнала на DAC пропущен через PLL ? Если да то в каком режиме стоит PLL? дает ли она сдвиг по фазе ?
Что именно у вас падает Tsu/Th ? приведите на картинке WaveForm и отчеты Path для обоих случаев. Хочется посмотреть через что у вас идет сигнал.
-
получается что в этом примере уже ошибки нет
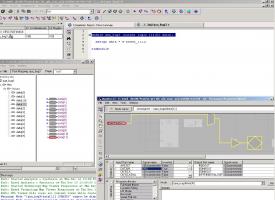
ошибки синтеза и не было, была ошибка Technology Mapper в отображении логики. Именно по-этому на картинке : код, его отображение в Technology Mapper и его отображение в Resource Editor. Т.е. копаться в схеме по TM бесполезно, т.к. он неправильно отображает логику.
-
а имелось ввиду видимо:
assign data = 12'b0000_1111_0000;
или
assign data = 12'b1111_0000;
в любом случае по стандарту чистого верилога в данном случае, при присвоении, должно быть беззнаковое расширение разрядности числа, т.е. слева должно быть дописано 4 нуля. А в случае знакового расширения результат должен содержать 8 единиц, а на рисунке видно что таких единиц 4.
хотел полюбопытствовать, насчет таких(похожих) граблей у хилых, неужели там хуже обстоят дела чем в альтере?Именно про такие грабли не в курсе, моя фраза относилась к общему уровню софта.
По удобству, скорости работы, результату ИМХО квартус много выше чем ИСЕ, исключая версию 8.1 %)
-
Тады я пошел в инсталляцию Lever 7.2 в его Альдек, скопировал все vendor (Латиса) библиотеки из vlib директории в таковую в Альдеке stand-alone и соотв. изменил library.cfg.
ну а компилировать их кто будет ? Сорцы скопировали это хорошо, но вот еще и билд запустить не помешает.
Либа в альдеке обычный проект, который компилируется в свой бинарник и подключается к проекту.
-
Коллеги,можете что посоветовать?
ко всему вышесказанному добавлю :
1. Судя по изображению не понятно откуда у вас, по мнению тайм квеста, идет клок на цап.
Это клок с генератора стоящего вне фпга и заходящего на цап и фпга? Если да выровнен ли он по фазе с клоком в фпга? в курсе ли таймквест соотношения фаз клоков фпга и цапа?
Или это клок идущий с фпга? Описан ли этот выходной клок в таймквесте ?
Лечение в этих случаях разное.
2. Вы не сказали находятся ли у вас выходные регистры в IO ячейках или нет.
3. Насчет таймквеста. У вас есть документ mnl_timequest_cookbook.pdf вы смотрели раздел I/O Constraints пример Example 1–11. Input and Output Delays Referencing a Virtual Clock ?
В примере приведен полный расчет необходимых времен. В задании set_output_delay нужно учесть 1. Tco фпга, Tsu/Th цапа, TBDmin/TBDmax по данным, TBD_CLKmin/TBD_CLKmax по клоку. (BD - Board Delay).
Просто вколотить туда какую нить цифирь от балды не совсем корректно %)
PS. совсем забыл, по разведенному нетлисту можно менять параметры IO буферов без переразводки проекта. Заходите в чип эдитор и делаете правки. Например можно уменьшить задержку на выходных буферах, если она была включена %)
-
Когда разрядность соответсвеет такого поведения не должно быть.
+1 К соотвествию указания разрядности (как-то давно вроде обсуждали).
вы внимательно посмотрели на рисунок ? разрядности приведены правильно, но вектор развернут lsb <-> msb %(
если тестеры пропустили этот очевидный косяк минус 50% зарплаты таким тестерам с понижением в должности.
-
Хм, а можно поподробнее пожалуйста про SV и randcase?
смотрите стандарт на System Verilog в нем все расписано. Ссылки на документы по SV в топе подфорума.
Просто есть ограничение...функция $random это функция стандарта языка Verilog, она должна быть в любом симуляторе, который поддерживает данный стандарт. Смотрите в стандарт, там все написано. В том числе и как можно расширить набор системных функций в конкретном симуляторе, например введя функцию $deposit.
-
Увы, пока требуется ...
Какие характеристики cpu, dma_мастеров необходимы для сравнения характеристик sdram core?
не те характеристики вы пишете,
полоса в память сколько требуется ? (100/200/300 МБ/с)
размеры и выравнивание бурстов ? их характер ? требуемая латентность доступа к памяти ?
2 шины - для исключения тактов ожидания от wb_arbiter (wb_req, wb_gnt).всего 2 шины ? кого ждем ? однотактный арбитр вишбона(Wishbone classic only)
module rrarb_1(request, grant, reset, clk); input [1:0] request; output [1:0] grant; input reset; input clk; reg [1:0] grant; reg last_winner; always_ff @ (posedge clk) begin if (reset) last_winner <= 0; else if (request) last_winner <= get_winner(request); end always_comb begin grant <= 2'b00; grant[get_winner(request)] <= 1'b1; end function automatic bit get_winner(input reg [1:0] request); case (request) 2'b01: get_winner = 1'b0; 2'b10: get_winner = 1'b1; 2'b11: get_winner = last_winner+1'b1; default : get_winner = last_winner; endcase endfunction endmodule ... rrarb_1 rra ({wbm_cyc_0, wbm_cyc_1}, {wbm_grant_0, wbm_grant_1}, reset, clk); assign wbs_cyc = (wbm_cyc_0 & wbm_grant_0) | (wbm_cyc_1 & wbm_grant_1); ...Какие характеристики cpu, dma_мастеров необходимы для сравнения характеристик sdram core?пока еще маловато данных
Или Вы порекомендуете интегрировать в проект все core по очереди с запуском тестов пропускной способности на реальном железе?это вам решать
Также вопрос: С Вашей точки зрения система с раздельными шинами [cpu- sdram], [pci, ide- sdram]будет предположительно иметь лучшие характеристики, чем с единой шиной?в случае wishbone_bus, будет необходим буфер по записи, принимающий пакет c wb_bus и подсчитывающий длину буста. После этого производится запись в sdram. Дополнительно за счет буферизации вро-де бы должна увеличиваться пропускная способность?
Вопрос о лучшести пока подвешен, но мне кажется что вы не представляете потенциальных проблем шины wishbone по работе с бурст транзакциями. Рекомендую вам почитать внимательно главу Wisnbone Register Feedback ее стандарта и попробывать на коленке сделать для этой реализации арбитр и слейв со случайным временем доступа :) Оччень увлекательное занятие.
Как уже говорил, у вишбона есть потенциальные проблемы :
1. нет стандартной возможности сообщить слейву размер буртса (обходится тегами, но нужен специальный арбитр и специальный мастер)
2. отсутствие разнесенных транзакций, т.е. мастер выставил первый запрос и держит его до посинения, пока не получит ответ, только потом идет смена адресса/данных/транзакйии(это обходится сложнее, тут нужен специфический арбитр).
3. отсутствие требований на выравнивание бурст транзакции, т.е. в транзакции Linear Burst вы можете легко перейти в другой ряд памяти и это вызовет "дырку" в тех же командах к сдрам (в общем виде не обходится, только соглашениями как в AMBA на размеры сегментов).
Вот это вы должны учитывать в своей системе.
Реализация с буфером требует наложения ограничений на размеры бурста и как вы будете решать проблему латентности записи/чтения если бурст относительно большой?
В моем мосту Wishbone/HSSDRC (выложить пока не могу, ибо не тестирован хорошенько) запись идет "транзитом", практически без кеширования. А вот чтение сделано с кешированием по запросу. Это позволяет работать как с WbClassic так и с WbRegisterFeedback шинами, с поддержками WS в обоих направлениях, при разумной тактовой частоте %)
Но в любом случае, без специального арбитра очень сильно падает полоса памяти, из-за латентности чтения и отсутствия разнесенных транзакций в шине.
PS. посмотрите AMBA AXI, у нее таких проблем нет, правда ее реализация сложнее.
ЗЗЫ. арбитра не того скопировал, поправил, теперь точно однотактный %)
-
В общем не нравится мне все тот же факт, несоответствия =)
Какой факт несоответствия?
RTL вьювер в квартусе работает не по результатам синтеза, а по результатам парсинга(лексического и синтаксического анализа) файла. Что у вас написано, то он и отображает, разбивая схему на Register Transfer Level (уровень регистровых передач).
Прошу заметить это всего лишь уровень представления описания логики, а не результат синтеза(!!!). Нужен результат синтеза смотрите Technology Mapper.
Прошу заметить в хенбуке на квартус все это описано.
...на rtl уровне в схеме с case присутствует один мультиплексор, многоразрядный, а в if - на кажду ветку if по одному мультиплексору. Т.е. поидее аппаратные затраты и временные характеристики должны быть совершенно разными, однако по результатам полной компиляции проекта все одинаково.Если у вас в мультиплексоре уникальные условия, то при включенной оптимизации квартус за вас проводит реструктуризацию мультиплексора. Что бы потом пользователи не писали в саппорт что то вроде "почему я пишу if (addr == 5) else if (addr == 6) else, а квартус городит иерерахический выбор, ведь адрес в каждом if уникальный".
Еще раз прошу заметить в отчетах квартуса все это есть(!!!) и в хендбуке на квартус это тоже описано.
Лично я часто сталкиваюсь с тем, что rtl viewer показывает то, что соответствует vhdl коду, но синтезатор решает это дело по-другому, видимо идет какая то оптимизация или еще чего.Ответил в пункте первом, рекомендую, несмотря на размер хендбука в ~3000 страниц, искать ответы о работе квартуса в нем и в случае проблем работы квартуса читать внимательно его логи.
-
ну и напоследок
вот это полный п.....
такое ощущение что у хилых индусов переманили, ну уж так то лажать зачем (!!!)
ЗЫ. Не могу зарегится на альтере, у кого есть там канал стукнитесь в саппорт если не сложно.
ЗЗЫ. Всё, назад к 8.0sp1
-
Если кто знает как решить эту проблему - заранее благодарен.
проблемы не вижу, что именно вам не нравиться ?
Если хотите видеть именно железо смотреть надо Technology mapper.
PS. Кстати после синтеза в отчете считаются ВСЕ триггеры проекта, даже те, которые будут упакованы в аппаратные блоки. В итоговом отчете кол-во регистров меньше (если такая упаковка была).
-
Просто как я понимаю в Верилоге нет функции рандома.
Если как-нибудь можно это реализовать, буду премного благодарен Вашим идеям!
смотрите стандарт, все там есть.
хотя именно в вашем случае лучше использовать SV и его randcase
-
Какую opencore Вы порекомендуете (с учетом возможного downgrade ddr opencore)?
странно, вообще то переход с sdr sdram на ddr sdram это upgrate, а у вас наоборот. Я бы с ддр не рекомендовал вам связываться, сразу ставить ддр2.
Лучше ли core от altera || xilinx чем представленные на opencores? Или эти примеры имеют худшие характеристики?Лучше/хуже без конкретизации параметров разговор на пустом месте, побольше конкретики.
Контроллер des_00 при переделке его в контролллер sdram - возможны ли грабли?вы вообще проект смотрели ? это и так sdr sdram. В названии же написано HSSDRC == HighSpeedSDRamController.
С ддр будут проекты HSDSDRC/HSD2SRD== HighSpeedDdrSDRController/ HighSpeedDdr2SDRController. Но это когда время будет, уже год зашиваюсь :(.
-
2007a.18. Аналогично. Проект собрался.
ну значит оччень быстро сие поправили, на моей версии 2007.a17 проект не собирался, на тот момент это другой у меня не было %)
-
в копилку "расширенной поддержки систем верилога"
module qua_bug2 (input logic [1:0] mode, code, output logic [11:0] used_bits0, used_bits1); typedef logic [1:0] mode_t; localparam int cPREAMBLE = 20; localparam int cPOSTAMBLE = 20; function automatic int get_all_bits (input mode_t mode); get_all_bits = cALL_BITS_0; case (mode) 2'd0 : get_all_bits = 4000; 2'd1 : get_all_bits = 3050; 2'd2 : get_all_bits = 3000; 2'd3 : get_all_bits = 2500; endcase endfunction function automatic int get_field1_bits (input mode_t mode); get_field1_bits = cFIELD1_BITS_3; case (mode) 2'd0 : get_field1_bits = 10; 2'd1 : get_field1_bits = 20; 2'd2 : get_field1_bits = 30; 2'd3 : get_field1_bits = 40; endcase endfunction function automatic int get_field2_bits (input mode_t mode); get_field2_bits = cFIELD2_BITS_3; case (mode) 2'd0 : get_field2_bits = 10; 2'd1 : get_field2_bits = 20; 2'd2 : get_field2_bits = 30; 2'd3 : get_field2_bits = 40; endcase endfunction function automatic int get_used_bits0 (input mode_t mode, input mode_t code); get_used_bits0 = get_all_bits(mode) - get_field1_bits(mode) - get_field2_bits(mode) - cPREAMBLE - cPOSTAMBLE; endfunction function int get_used_bits1 (input mode_t mode); case (mode) 2'd0 : get_used_bits1 = get_all_bits(0) - get_field1_bits(0) - get_field2_bits(0) - cPREAMBLE - cPOSTAMBLE; 2'd1 : get_used_bits1 = get_all_bits(1) - get_field1_bits(1) - get_field2_bits(1) - cPREAMBLE - cPOSTAMBLE; 2'd2 : get_used_bits1 = get_all_bits(2) - get_field1_bits(2) - get_field2_bits(2) - cPREAMBLE - cPOSTAMBLE; 2'd3 : get_used_bits1 = get_all_bits(3) - get_field1_bits(3) - get_field2_bits(3) - cPREAMBLE - cPOSTAMBLE; endcase endfunction assign used_bits0 = get_used_bits0(mode, code); assign used_bits1 = get_used_bits1(mode); endmodule
количество слоев логики/лютов по сигналу used_bits1 - 1/4, а по сигналу used_bits0 - целых 14/28(!!!)
"когда наши корабли бороздят просторы вселенной..." (с) явно проблемы с логикой преобразования функций в содержимое лютов.
Чудны дела твои господи
-
Cкажется ли куда (row/col/bank) отправлять разряды адреса wb_шины?
Интересно как вы сами думаете ? :)
Все следует из характера работы сдрам памяти и используемого вами режима. Если вы будете всегда писать по 1 слову, вы вообще можете распихать адреса как вам будет угодно.
Обычно отображение адресов выбирают исходя из :
1. размер бурста
2. выравнивание бурста
3. частота обращений по адресам
Нужно смотреть ваш конкретный случай.
Оптимальное, рекомендуемое отображение приведено в документации.
Удачи !!!
-
Итак господа, решил новый проект собирать под 8.1 и вот первые итоги.
Запустите вот это в 8.0sp1 и в 8.1
function automatic uint16 get_crc16x1 (input uint16 crc, input bit b); bit msb; uint16 crc_next; begin msb = crc[15]; crc_next = crc << 1; crc_next[0] = b ^ msb; crc_next[5] = b ^ msb ^ crc[4]; crc_next[12] = b ^ msb ^ crc[11]; return crc_next; end endfunction function automatic uint16 get_crc16x16_1 (input uint16 crc, input uint16 data); int i; uint16 crc_next; begin crc_next = crc; for (i = 16; i > 0; i--) begin crc_next = get_crc16x1(crc_next, data[i-1]); end return crc_next; end endfunction function automatic uint16 get_crc16x16_2 (input uint16 crc, input uint16 data); uint16 crc_next; begin crc_next = crc; for (int i = 16; i > 0; i--) begin crc_next = get_crc16x1(crc_next, data[i-1]); end return crc_next; end endfunction module qua_bug (input uint16 data, output uint16 crc0, crc1); assign crc0 = get_crc16x16_1(0, data); assign crc1 = get_crc16x16_2(0, data); endmodule
8.1 радостно сообщает что crc1 сидит на земле, видите ли драйверов этого порта нет(!!!). 8.0 в отличие от него отрабатывает честно.
Вот это подляна так подляна, вот это Improvement SV support.
-
dess00, Ваш проект собрал, как и обычно :)
я использовал 2007.а17, какой использовали вы ? Если более поздний думаю что уж за 1.5 года они смогли этот баг поправить

-
Я извиняюсь, а заклинание setup_design -all_file_cunit_scope=true использовали?
нет не использовал, т.к. в гуй не нашел где это ставиться.
но вот сейчас задал это в командной строке, так проект вообще не собирается. ни в одном варианте. поставил setup_design -all_file_cunit_scope=false
с подправленым инклудником собрался
проект в атаче, если интересно посмотрите.
Все дело в строке файла include/hssdrc_define.vh
// `define __HSSDRC_DEFINE_VH__

Интерфейсы с параметрами в интерфейсах модулей
в Языки проектирования на ПЛИС (FPGA)
Опубликовано · Пожаловаться
дык в стандарте же написано. Правда синтезируемость не гарантирую %)