Я смотрел на проблемы отсутствия SLOAD и как бы их обойти... Да без SLOAD иногда понадобиться использовать 2 LUT4 сцепленных каскадно, или более хитро, ISE 9.2 уже научился уже это делать хорошо,.. даже слишком хорошо. А SLOAD - один на весь LAB, также как и ALOAD, SCLR; а ACLR и CLKEN - только два на все LAB триггера. Да, эти управляющие линии очень приятны, но уже очень их ограниченный набор на весь LAB... А жаль, задумка полезная, побольше бы было таких независимых линий и было бы очень хорошо. У Xilinx FPGA на каждый Slice приходит по своему CE, CLK, CLR/RST, PRE/SET - правда, есть архитектурный недостаток - эти сигналы всегда подаются на оба триггера в Slice. Но в Slice только 2 триггера,.. а в LAB до 16.
У Xilinx есть GSR (Global Set/Reset), только он сбрасывает все триггеры кристалла, поэтому эти цепи выброшены из схемы Slice. А по поводу активного использования асинхронных сбросов и предустановок только недавно (в пределах полугода назад) обсуждался вред такой техники работы - уж очень надо аккуратно работать с ними - не все могут справиться, поэтому с синхронными сигналами Set/Reset понадежней получается.
А зачем... между соседними CLB сигналы передаются по коротким трассам - это я и имел ввиду под разницей разводочного ресурса, в Spartan и Virtex между соседними CLB груда трас... и все они быстрые (поэтому их и не выпячивают с помпой), а что по ним передавить - неважно: выход логики X (Y) или выход триггера XQ (YQ), причем всё равно какого Slice из имеющихся в CLB. А в пределах CLB данные передаются еще быстрее.
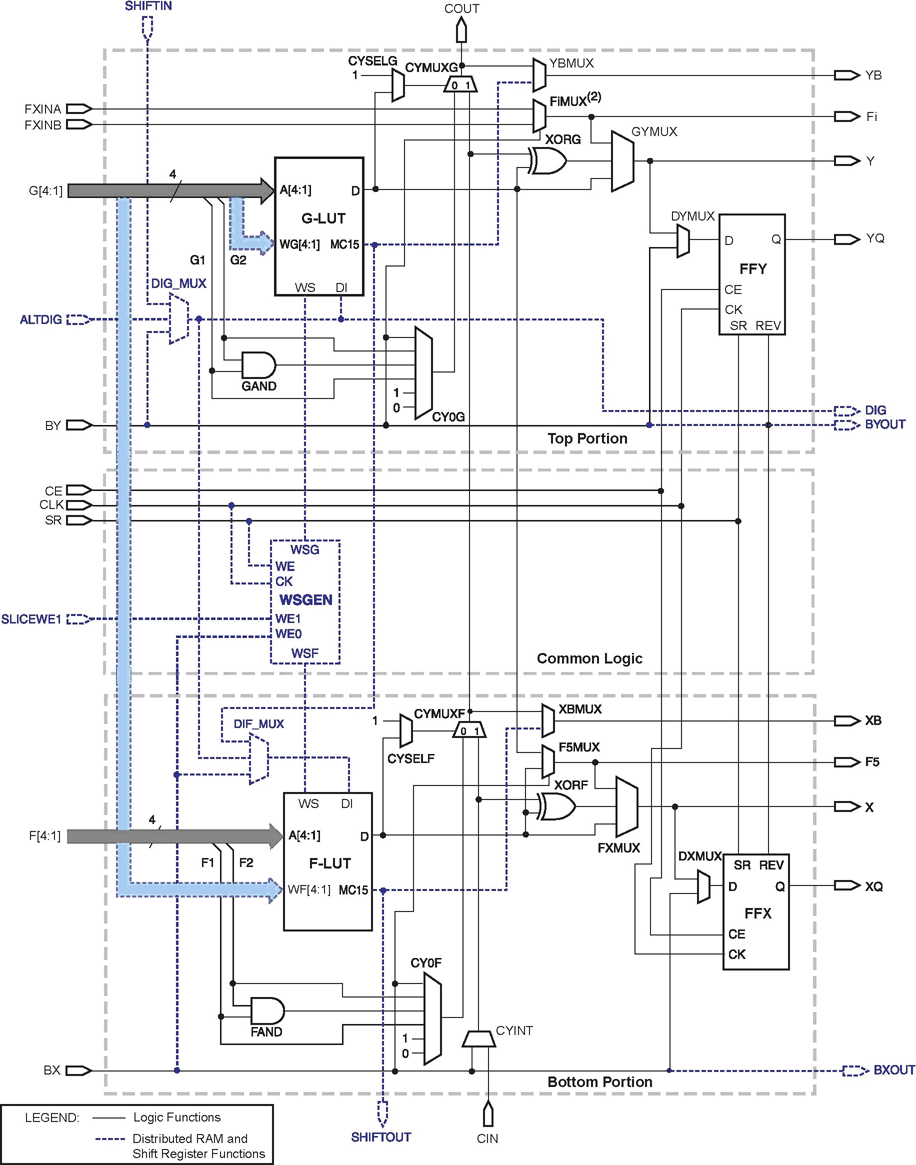
Он действительно не всегда нужен, но когда нужен, то очень полезен. Для чтения Distributed RAM - асинхронная память. При любом использовании LUT4 можно использовать и FF, правда, если LUT4 используется не как ROM, то с некоторыми небольшими ограничениями (clock у них общий...)
А вот, например, в Pico Blase на 32 LUT собирается 16 16-разрядных регистров S0-S15 с 2 выходами, со встроенными дешифраторами адреса, выходными коммутаторами и почей обвязкой характерной для SRAM - получается очень компактно и блочная память не расходуется.
Редкость... поэтому место отвода динамически задается адресом (входными данными LUT'а - 4 бита) - и можно выбирать какую ячейку мы хотим увидеть от 1 до 16. Есть еще и специальный выход для каскадирования - там всегда данные с 16-ой ячейки.
Ну пользуйте триггеры в Spartan - кто Вам не даёт ? При этом тоже можно использовать оба LUT4 сколько влезет. Про то, что у Xilinx все короткие трассы соединения достаточно "быстрые" - я написал выше, да и ниже тоже.
По моему не может, для этого понадобится собрать внешний генератор адреса... А если нужет не очен длинный сдиговый регистр (например на 64 бита) можно воспользоваться теми самыми SHR16, соединенными каскадно, а блочную память использовать для чего-либо более полезного.
CycloneII Architecture, 2 абзац: The logic array consists of LABs, with 16 logic elements (LEs) in each LAB.
Cyclone III Device Handbook, Volume 1: The logic array block (LAB) consists of 16 LEs and a LAB-wide control block.
Ну да мне всё-равно.
У X есть груды local line - это линии с малым временем распространения сигнала на "близкие" расстояния. У Spartan-3A от каждого CLB расходятся local lines предназначенные для достаточно быстрой (для предельных частот работы ПЛИС) к восьми соседним CLB. Для передачи данных на большые расстояния есть local lines пробрасывающие сигнал на 3 и 6 CLB одновременно, если надо еще дальше, то используется каскадное включение local lines, или уже long line. Если не лень гляньте FPGA Editor'ом в любую Xilinx FPGA и Вы увидите все детали этого кристалла (и заметьте: разводочный ресурс потребляет очень много места в Xilinx FPGA).
Мои соседи сидят на Cyclone 1, 2 и 3, он им подходит больше, в т.ч. и из-за большего количества "маленьких" (4K) блоков памяти на триггер - такие задачи.
А мне больше подходит Xilinx FPGA... - такие задачи.
Да весьма похож, но не он (нет Distributed RAM)... интересно кто появился раньше Virtex 1 или Arria ?
P.S.
Недеюсь нигде не опечатался.
Вот, наверное, и описаны основные + и - для Spartan-3x и Cyclon 1, 2, 3... в сравнении так сказать.