dxp
-
Постов
4 593 -
Зарегистрирован
-
Посещение
-
Победитель дней
15
Весь контент dxp
-
Нет, скрам -- это методология ведения работы. А система следующий, более низкий уровень иерархии, система управления строится на основе методологии. Что не делает методологию системой. Конечно. Логистика, закупки, отлаженные производственные процессы -- да. Где всё более-менее предсказуемо и поддаётся адекватному прогнозированию. Но не в разработке нового. Серьёзно? 🙂 Ещё как даёт -- просто методы лодыри применяют другие. Например ИБД (имитация бурной деятельности). А в совокупности к хорошо подвешенным языком бездельник вообще может казаться самым деятельным -- скрам предоставляет как раз возможность демонстрировать (дейлики и прочие регулярные митинги). Не даёт лодырничать никакой не скрам. Вообще, никакая методология или система управления не решает сама по себе эту задачу. Её решает конкретный человек -- руководитель. Если он на своём месте, он прекрасно видит, кто что стоит, кто чем занимается, где есть толк, а где пустота (имитация). Потому что принцип "Кадры решают всё!" применим не только к исполнителям, но и (в первую очередь!) к руководителям. Управление -- живой процесс. И всё зависит от квалификации, умений, опыта и адекватности человека, который осуществляет это управление. Никаких других вариантов нет. Полагать, что скрам что-то там кому-то не даёт или наоборот обеспечивает результат -- есть вредная иллюзия. Далее по пунктам. Ещё одна иллюзия. То, что скрам-методология предполагает ежедневные митинги наряду с планированием спринтов и ретрами, никакой вовлечённости не повышает и не обеспечивает: сидят люди на митинге, слушают бубнение очередного выступающего, ждут своей очереди отчитаться и того, когда это бесполезное и бессмысленное мероприятие закончится. Только и всего. Много раз лично участвовал в этих митингах и наблюдал оную картину. Вовлечённость в проект может поднять тот же самый человек, который руководит процессом, применяя три рычага (это известная тема из психологии): поднять интерес подчинённого сотрудника-коллеги, правильно выбирая для него задачи -- далеко не все задачи интересны всем, поэтому тут надо внимательно и чутко подходить. Будет интерес -- будет результат. Интерес -- это самый главный мотиватор; помочь с пониманием трудных моментов (сам или привлекая других, более квалифицированных в вопросе людей). Когда человек имеет хорошее понимание того, что он делает, это тоже прилично мотивирует (повышает вовлечённость), позволяет работать эффективнее, что поощряет исполнителя, который видит позитивный результат своей работы; довести важность дела до сотрудника-коллеги: нужность результата, ответственность перед заказчиком, уважение товарищей и т.п. Всё это -- живая работа с людьми. Только она и даёт результат. А пустая говорильня на дейликах -- просто трата времени и сил. За счёт чего? Что такого уникального даёт скрам для этого? Что собрались и поговорили? Ну, собрались и поговорили. Наговорились, устали, ничего не решили -- это сколько угодно. Даже более того -- это обычный результат, когда толпа пытается что-то решить. "Лебедь, рак и щука". И эта говорильня продолжается из раза в раз без всякого результата. Решение менять курс (адаптироваться) должен принимать тот, кто отвечает за результат. Его ответственность, его и решение. Как правило, это тот же самый руководитель работы. Он может собрать людей, спросить их экспертное мнение, выслушать каждого, и на основании этого, а также своего опыта и знания своих людей (к чьему мнению в какой ситуации нужно прислушиваться больше, а чьё умножать на 0.1) принять решение, за результат которого ему потом отвечать. Никакие общие собрания и пустопорожная болтовня на них не нужны. Соблюдение сроков обеспечивается грамотным разбиением работы на этапы и контролем выполнения работы по этим этапам. А коллективная ответственность -- это миф! За исключением крайних случаев: типа, все мегасознательные и ответственные как главный герой из советского фильма "Коммунист", или когда в случае неуспеха всех расстреляют (лишат премии, уволят и т.п.). Во всех других случаях коллективная ответственность проявляет себя как коллективная безответственность. Всегда в группе (статистически) находятся раздолбаи, тормоза, рукожопы, эгоисты-индивидуалисты и т.п. И без присмотра и персональной ответственности всё это приводит к тому, что результат провальный, с спросить не с кого. Итого, опять всё сводится к компетенции и квалификации управляющего процессом конкретного человека. Работает только в случае простых задач. Проходили не раз. Когда задачи сложные, требующие серьёзного вникания, всё это не работает от слова совсем. Пример из реальности: пилим командой ПЛИСовый проект, я занимаюсь PCIe DMA (на TLP), а коллега -- поиск паттернов в потоке сетевого трафика. У нас задачи не пересекаются вообще никак! И каждая из них требует глубокого погружения. В итоге, все скучают, когда я что-то бубню запросы чтения памяти хоста, проблемы негарантированного порядка прихода CplD от разных запросов, про кредиты non-posted запросов и подобное, а когда коллега говорит про свою работу, я из его рассказов понимаю только, что у него там какие-то блум-фильтры, перфектные таблицы кукбука и ещё какая-то хрень, названия которой я не запомнил. Чтобы мне понимать, о чём он говорит, мне нужно серьёзно погружаться в тематику его работы, но я не могу этого делать -- у меня своей выше крыши. И у него ровно та же ситуация. И у всех в группе. Получается, что все сидят и тупо ждут, чтобы отчитаться, и когда это пустое мероприятие закончится. Скрам-мастер не понимает вообще ничего из того, что там говорят, т.к. он не специалист ни в ПЛИС, ни в тематике проекта. Ну, по скраму он и не должен. Его задача -- быть секретарём заседания. И вот в итоге проектом занимается 8 человек, но задачи у всех перпендикулярные, какие-то общие места есть только на стыковках, а это очень небольшая часть проекта. В итоге, на общие темы мы можем поговорить только про какое-нить CDC FIFO, проблемы с STA, нюансами использования общего инструментария (симулятор, синтезатор и т.п.) и другими общими вопросами, которые к непосредственно проекту имеют опосредованное отношение. Итого, эффективно задачи решаются при правильно организованной иерархии управления, когда все люди -- и специалисты, и руководители (от крупных до тимлидов) на своих местах. Иерархия -- это естественный способ решения сложности в человеческой коллективной деятельности.. Да, тут важно не скатиться в раздувание иерархии на пустом месте, не допустить возникновения и роста бюрократии и формализации. Поддерживать процесс живым -- это достигается только правильным подбором кадров и никак иначе. Скрам же тут не помогает совсем никак. А мешает изрядно. Он размывает ответственность, распыляет цели, место чётко выверенного курса получается "рыскание". На локальном уровне хорошо работает самоорганизация, когда подбираются (или подбирают) люди ответственные, мотивированные, знающие и умеющие -- она сами между собой наладят и взаимодействие, и рабочий процесс. Но это происходит самодвижущимся образом у них без всяких скрамов. Скрам и тут только мешает, пытаясь формализовать этот естественно сложившийся процесс. Когда задача совсем новая и непонятная, то, конечно, никакого внятного ТЗ быть не может. Поэтому ведётся предварительная работа -- например, как вы правильно назвали, выполняется НИР. А потом при выполнении ОКР ещё эскизный проект (ЭП), на входе которого присутствует проект ТЗ, и цель ЭП -- создать технический облик объекта разработки и разработать уже нормальное ТЗ, с которым можно смело идти в технический проект (ТП), коий уже и есть собственно разработка. Где тут рулящая роль скрама? Да без него это сто лет делалось и делается. Он сюда вообще не вписывается. Что же касается корректировки ТЗ по ходу дела, то и это возможно, но не так огульно как это делается со скрамом. Если заказчик предлагает (просит) что-то поменять, это рассматривается, и если принимается, то выпускается специальные документ: дополнение к ТЗ. Все эти доп. хотелки отражаются там. И всегда видно, что было исходно, а что изменилось по ходу дела. Отдельный документ позволяет хорошо видеть, сколько чего, когда и как изменилось. И это позволяет эффективно пресекать излишнюю тягу заказчика к фантазиям . При разработке софта эти изменения реализуются ещё как-то более-менее безболезненно. При разработке железа -- это как правило боль, и часто оказывается неприемлемым. Иначе разработка затягивается на годы. Это проблема, когда софтовая контора берётся делать железо: тематика и средства радикально другие, а подходы те же самые. Я работал в софтовой IT комании, которая взялась разрабатывать железо (для себя, для своего продукта), в итоге 6 лет хардварному отделу, объём работы проделан колоссальный, сами разработки технически очень достойные (специалисты высокого уровня там трудятся -- контора может себе таких позволить), но в серии и у клиентов по истечении этого срока нет ни одного из полудюжины разрабатываемых изделий. Это происходит именно по причине постоянных корректировок хотелок, отрицания ТЗ как такового, отсутствия этапности в работе, зато есть скрам во всей его красе с коллективной ответственностью безответственностью и прочим. Да и странно предъявлять ответственность исполнителям, если от них тут мало что зависит -- каждый из них на своём месте свою работу сделал хорошо. Подводя итог Скрам, возможно, неплохо себя проявляет при разработке, например, веб-приложений, когда результат работы можно сразу предъявить, и заказчик видит его, может попросить что-то поменять или откорректировать -- вот тут спринты, как контрольные точки, помогают. Но когда ведётся разработка материнской платы сервера (со 128-ядерным процессором и 16 планками DDR4), где работа схемотехника и конструктора ПП занимает по полгода, какие нафиг спринты?! То же самое и с ПЛИС: тот же PCIe DMA я пилил несколько месяцев, и эта работа почти никак не пересекалась с другими -- она несмотря на известную сложность, является локальной, законченной в себе -- ни вводные никакие снаружи тут не нужны, ни результат показать в конце спринта невозможно (вряд ли кому будет интересно смотреть на очередной добавившийся тест того или иного модуля). По итогу пристального наблюдения за этой темой и невольного участия в ней, для себя я сделал следующий вывод: скрам -- это вредная иллюзия управляемости процесса, которая проникла глубоко в сфере IT. Секрет успеха этого внедрения состоит из двух частей: Потребность руководства IT компаний в инструментах управления, которые оное руководство само создать не смогло, но тут ему предложили готовое "решение". Агрессивная реклама этой методологии со стороны консалтинговых агентств и лавок вроде AgileLab, желающих рубить немалые деньги на некомпетентности, доверчивости и легковерности руководителей IT контор. Ну, почему руководители контор ведутся на это -- это Даннинг-Крюгер в полный рост: уровень управленческой компетентности не позволяет ни организовать процесс эффективно, ни понять, что предлагаемое тоже не решение. Процесс разработки и продвижения софта сам по себе прощает многие косяки -- цена ошибки невелика, стоимость производства ноль, сроки производства -- тоже почти нулевые (сколько на пересборку требуется), возможность отлаживаться на клиентах и т.п. Всего этого нет в теме разработки железа, там всё эти ошибки стоят дорого. Поэтому там этот подход не работает совсем. Если в какой-то конторе ввели Scrum, это по факту и по сути является ничем иным как росписью руководства этой конторы в собственной управленческой несостоятельности. Не больше, не меньше.
-
Прогон для Vivado 2023.1.2: Конфигурация PC: AMD Ryzen 9 7900X, DDR5 2x32GB (на частоте 5200 МГц), MB на чипсете B650, NMVe (1000 ГБ SSD M.2 Samsung 970 EVO Plus). Время что-то очень коротким вышло -- либо проект простой (для современного железа), либо, может, сделал что-то не так. Но просто открыл проект вивадой, она предложила конвертнуть в нынешний формат, я согласился. Дальше пнул сборку и всё.

-
Это что за ТЗ такое, когда через месяц оказалось, что оно не про то? ТЗ -- серьёзный документ, от него зависит результат чуть не на все 100%. ТЗ -- это отправная точка в разработке. Из него формируются этапы работы. Если через месяц выясняется, что ТЗ не про то, что надо, разработчика ТЗ (или того, кто ему задачу ставил) гнать за профнепригодность. Меняет и дополняет по ходу дела?!!! Серьёзно?! Вот это и корень проблем при использовании IT'шных подходов в разработке железа! Это в софте можно быстро перех..якать, с железом это не прокатывает. Да и с софтом эта практика порочна и является источником массы проблем, просто там последствия ощущаются не так больно. Вместо того, чтобы сразу подумать и спланировать процесс, там доминирует метод "х.як, х..як и в продакшн". Единственный сценарий, где такое оправдано -- это когда задача (что нужно конкретно сделать) недостаточно ясна на старте, и пока не начнёшь, невозможно понять, как конкретно это надо сделать. Поэтому применяется этот метод "тыка" -- сделали что-то, увидели, то или не то. Тут, конечно, нужно всем участвовать -- и заказчику, и разработчику, и периодичность этих контрольных точек должна быть достаточно короткой (1-4 недели) -- те самые спринты. Это как-то работает при разработке софта, но с железом это полный провал. Там нужно всё заранее тщательно проектировать и планировать, потому что перефигачить по ходу дела не получится, т.к. стоимость производства в отличие от софта далеко не ноль. Что знают? Что мешает это знать без скрама? А нужно ли всем участникам это знать? Не будет ли это "знание" отвлекать их от своей конкретной и сложной работы? Это нужно знать всем участникам команды? Зачем? Об этом нужно знать тем, кто к этому причастен. Это узнаётся адресно без всяких скрамов. При правильной организации работы есть её руководитель, который всё аспекты курирует (или назначает ответственных, если задач много). И для этого скрам нужен? А как же без него-то обходились десятки лет и продолжают обходиться? Когда приступать к выпуску КД -- очевидно на этапе РКД. Ну да, тут никак не обойтись без планирования спринта, дейликов, ретры. Ведь все разработчики должны быть в курсе, когда же надо отдать корпус в покраску. И уж стопроцентно это должны знать скрам-мастер и продукт овнер. Ну, если потеря кучи времени и отвлечение на посторонние процессы, зачастую искусственные и бесполезные, как натягивание работы на сторипоинты, никого не расстраивает, то пожалуй поверю. 🙂 Ну, о чём и речь -- годится только для простых и понятных задач, которые ясно, как делать, можно достоверно спрогнозировать трудозатраты и т.п. Словом -- не про разработку. Логистика, снабжение, какие-то уже более-менее отлаженные производственные процессы, когда есть опыт, на который можно опереться. В разработке нового такого опыта как правило нет, поэтому всё это скрам-планирование идёт лесом. Ну, удачи вам
- 21 ответ
-
- 3
-

-

-
Помнится, было дело тут на форуме: кто-то скидал простой, но затратный на сборке проект под Quartus (как бы не для Cyclone II), и все желающие могли собрать его на своём железе и выложить результаты -- была какая-то более-менее объективная оценка эффективности сборочной машины. Может тоже так же сделать: скидать проект под Vivado, например, на Artix7-200, и выложить, чтобы все желающие могли попробовать и доложить какие-то более-менее объективные результаты? Показать: конфигурация РС, время сборки в формате: IP ядра. Синтез. P&R. Общее время. Вот только состав проекта надо подобрать, чтобы там не было перекосов, чтобы все компоненты равномерно задейстовались: комбинационная логика, флопы, блочная память, IP ядра (как минимум PLL, а ещё, может PCIe), DSP блоки (но без фанатизма). Может есть что-то готовое на примете? Думается, такое было бы и интересно многим, и полезно.
-
Vitis Appearance
dxp опубликовал тема в Среды разработки - обсуждаем САПРы
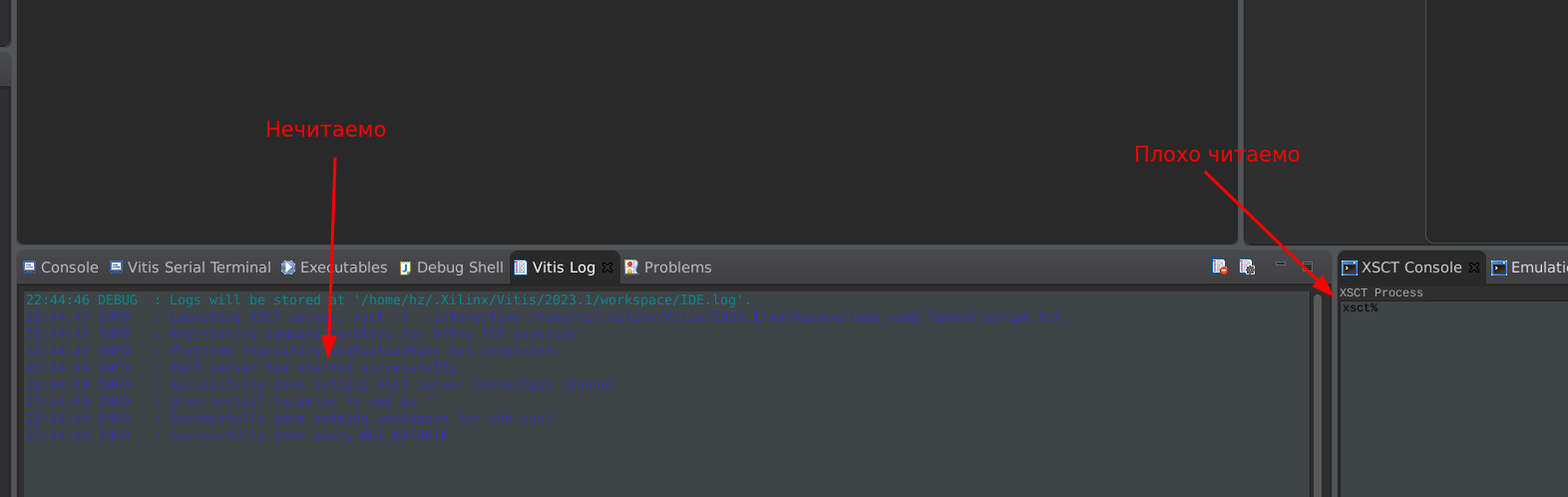
Всем привет! Какое-то время назад доводилось работать с Xilinx SDK. Потом была пауза в несколько лет, и вот сейчас опять возникла такая необходимость, но вот SDK канул в лету, и теперь вместо него Vitis. Ну, в целом вроде то же самое - эклипсообразная хрень, но сразу же столкнулся с неприятной неожиданностью: если раньше там (SDK) была традиционная светлая тема, которая, может, не слишком красивая, но вполне функциональная -- во всяком случае, всё хорошо читаемо, но теперь это просто... я не знаю, как это назвать. Оно стало тёмно-тёмно серым (щас такая мода пошла -- многие софты в этот мышиный цвет красят), и ладно бы, если бы не некоторые "но". А именно: на этом фоне содержимое отдельных окон или плохо читаемо, или вообще нечитаемо! Вот сразу с ходу при загрузке: Прочитать этот мутно-синий текст можно, только выделив (тогда контрастно)! Такая же история, например, с окном дизассемблера -- тоже такой же блёкло-синий на фоне мышиного. Ковырял настройки нашел про цвета, но там в основном настройки цветом элементов интерфейса, подсветка синтаксиса и подобное. Можно поменять фон отдельных окон, от этого вид ещё ужаснее -- некоторые окна с белым фоном, некоторые -- вот такие, тёмно-серые. Изменить цвет шрифта этих окон и окна дизассемблера не смог. Погуглил про темы (скины), вроде нашёл какое-то описание что-то там установить в виде плагина через некий marketplace, но интерфейс плагинов в Vitis или отключен (так было сказано по одной из ссылок -- и есть основания этому верить, т.к. длительные попытки найти возможность что-то установить через этот самый маркетплейс, не увенчались успехом), либо унесён куда-то в непонятное место. В общем, у меня два вопроса: 1. Риторический, к авторам этой поделки: они сами-то пробовали этим пользоваться? 2. Практический: кто как обходит эту неприятность? есть ли способы?
-
Падение 0.12 при токе 0.5А -- это характеристика силового элемента этого стабилизатора - т.е. то, что он может обеспечить, а не всей схемы. При питании 3.6В и падении на светодиоде 3 В остальные 0.6В рассеятся на внешних элементах. Итого, 0.5*0.6 = 0.3 Вт. Если питание будет выше, потери на тепло будут больше. А 0.12 падения на стабилизаторе говорит только о том, что он способен обеспечить 0.5А и выдать в нагрузку 3В при питании 3.12В. Если вам КПД и тепловыделение не препятствуют, то это другое дело. Но линейным силовым схемам по КПД тяжело тягаться с импульсными. У линейных есть другие преимущества.