Поиск
Показаны результаты для тегов 'fifo'.
-
Нужна помощь по SPI, DMA, Vivado
Nano2021 опубликовал тема в Работаем с ПЛИС, области применения, выбор
Здравствуйте! Я работаю над реализацией высокоскоростной передачи SPI и ищу лучший вариант для блока DMA. Схематическое изображение моей конструкции:прикрепил На сайте Xilinx я нашел следующиe блоки, который могу использовать: DMA Central Direct Memory Access DataMover 1. В чем разница между DMA и CDMA? Судя по описаниям и блок-схемам, это ... как будто потоковым устройством будет устройство, которое производит или потребляет поток байтов. Устройство с отображением памяти подключается к шине памяти. Таким образом, периферийному устройству, которое хранит входящие данные в регистре с отображением в память, потребуется CDMA, а периферийному устройству, где данные поступают непосредственно из буфера FIFO, потребуется DMA. 2. AXI Data Mover. Если я подключу его с блоком AXI FIFO Stream (параметры передачи команд), я получу блок DMA, как я понял. Этот блок дает мне больше свободы в реализации? 3. Какой вариант лучше всего для передачи данных из высокоскоростного SPI через DMA в память? Я бы хотел достичь 50-100 Мбит / с Заранее спасибо за вашу помощь
-
Проблемы с симуляцией FIFO корки в Vivado
Vengin опубликовал тема в Среды разработки - обсуждаем САПРы
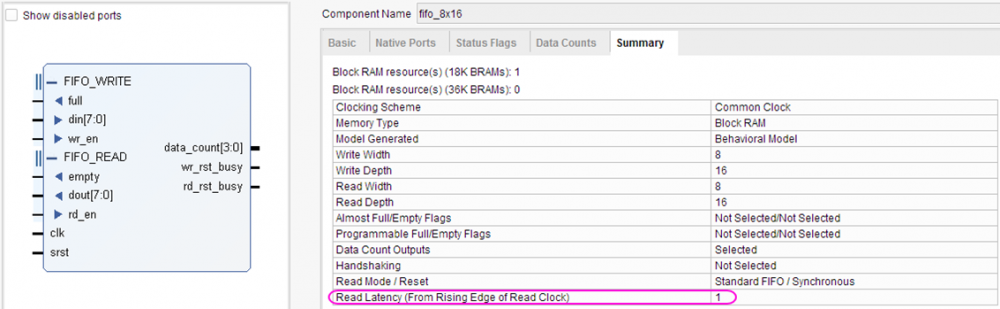
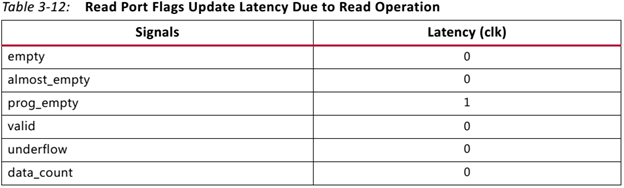
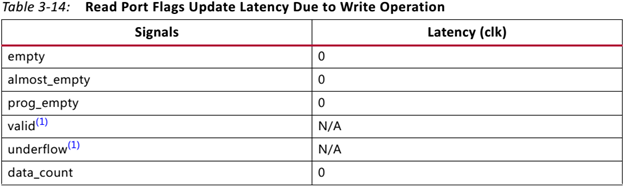
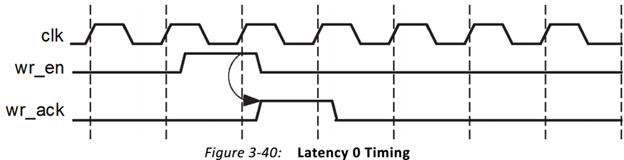
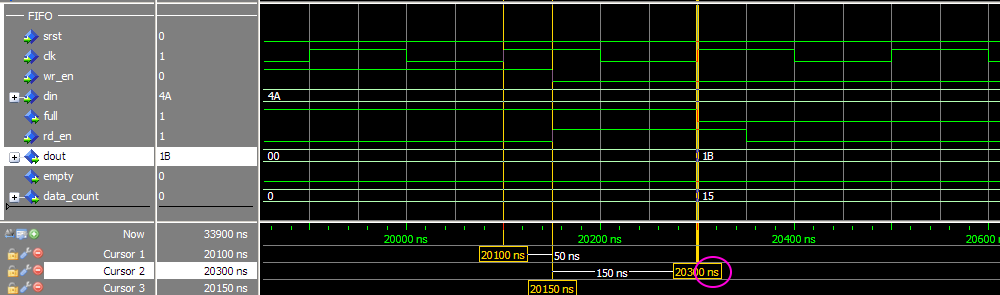
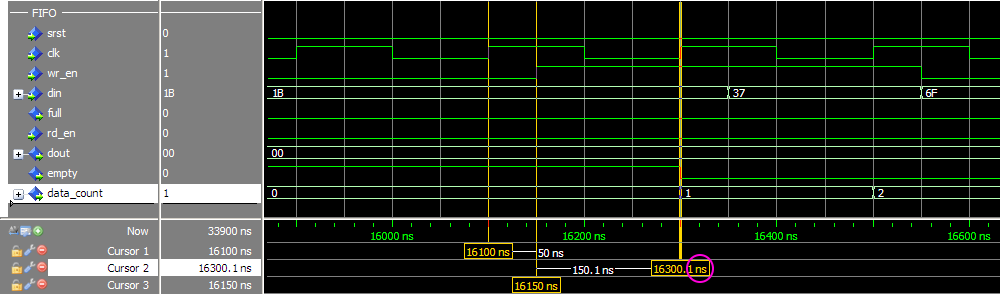
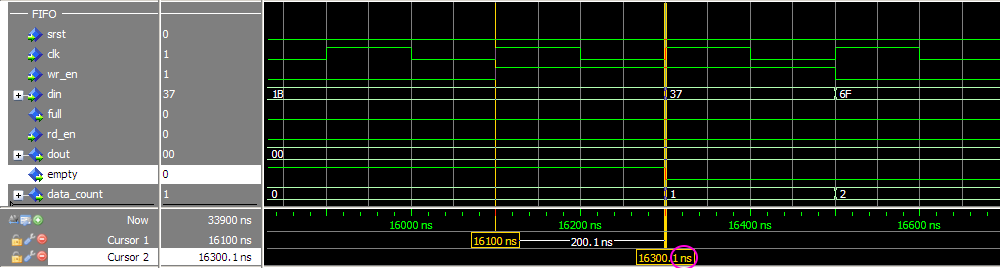
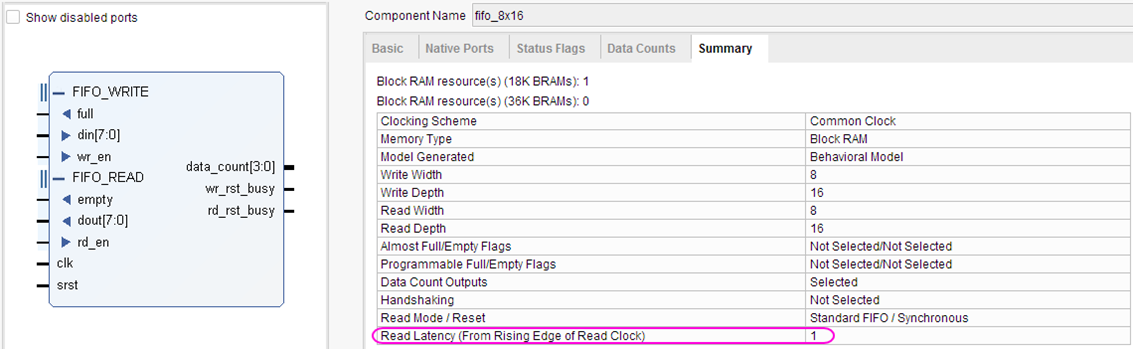
Симулирую FIFO корку Vivado и что-то никак не удаётся получить ожидаемого поведения. Не совпадают результаты симуляции с тем, что описано в даташите (в частости latency выходных сигналов), и с тем, что ожидаешь увидеть. Когда много лет назад приходилось работать с FIFO ядром в ISE, не припомню таких трудностей. Совсем запутался, надеюсь коллективный разум поможет. Итак вводные: Vivado v2017.4 (64-bit), корка fifo_generator_v13_2_1. Генерим простейшее FIFO: Native (без AXI), Common Clock Block-RAM, 8x16, Standard Read Mode (т.е. не First Word Fall Through), без выходных регистров: Как видим, ожидаемая задержка чтения (данных) должна быть 1 такт. А задержка остальных выходных сигналов указывается в даташите (“Ch. 3: Designing with the Core” -> Latency -> Non-Built-in FIFOs: Common Clock and Standard Read Mode Implementations) : Т.е. вроде все остальные выходные сигналы в домене чтения (кроме prog_empty) должны иметь задержу 0 тактов. Хотя лично для меня это звучит странно, т.к. в моём понимании это сигналы «синхронные» (т.е. выходят с неких внутренних регистров ядра), и должны быть задержаны хотя бы на 1 такт. И эти догадки подтверждаются синтезом корки (на схематике выходные «статусные» выходят с регистров. В моём понимании это задержка минимум в 1 такт (или больше, в зависимости от общего количества регистров в каскаде). Уже это вызывает вопросы. Xilinx в даташите на FIFO описывает, как определяется Latency: Тут стоит сказать, что ИМХО такое изображение диаграмм (т.е. не как в function simulation, («синхронное, такт-в-такт»), а как в timing simulation (более «реалистичное» с учётом таких задержек, как setup/hold)) не только не помогает понять логику работы для функциональной симуляции, но скорее больше мешает, ухудшает восприятие и приводит к потенциальным ошибкам. По мне так эта диаграмма больше похожа на latency=1, а не 0. Так вот генерим в Vivado тестбенч для нашего простенького FIFO (правым кликом на IP-Core –> “Open IP Example Design…”). В сгенеренном Vivado тестбенче «имитируются» вышеупомянутые timing задержки, т.е на VHDL используются конструкции вида “… after XX ns”. Таким способом «задержаны» синхронный сброс (srst), входные сигналы записи/чтения (wr_en/rd_en) и входные данные записи (din). В данном случае период клока симуляции 200ns, задержки after = 50ns. И что же мы имеем в симуляции. Вот так выглядит запись в FIFO: А так чтение из FIFO: Сначала я долго не мог понять, что за 0.1ns на выходных сигналах (диаграмма чтения, 3-ий курсор, сигналы empty/data_count обновляются при T=16300.1ns). Покопавшись в даташите и инете, вроде пришёл к выводу, что так явно «имитируются» delta delay симуляции (и/или задержки синхронных сигналов в железе). В даташите (Ch. 4: Design Flow Steps -> Simulation -> Behavioral Model): И на форуме Xilinx: тыц (100 ps delay for Block Memory Generator 6.3) и тыц (BRAM output delay). Т.е. вроде эти 100ps должны быть «более наглядными» (если сравнивать с delta delay, которая в симуляции стремится к нулю), показывая, что «in hardware, it should never assume that synchronous data is available instantaneously with the active clock edge». Переварив всё это, я прихожу к выводу, что: На диаграмме записи задержка сигналов статуса чтения (empty, data_count) по отношению к wr_en вроде как 0 тактов (соответствует значениям в таблице 3-14). Хотя (как уже писалось раньше), эти сигналы вроде как выходят с регистров, и должны иметь задержку минимум 1 такт. На диаграмме чтения задержка сигнала данных (dout) по отношению к сигналу rd_en мне непонятна (получается ещё меньше, чем 0 тактов, т.к. нет 100ps, а исходя из вышеупомянутых параметров FIFO latency=1). При этом если сконфигурировать FIFO с выходным регистром (Embedded или Fabric в поле Output Register), то ожидаемая задержка latency=2 такта, а на диаграмме выход dout «свдигается» на всё те же 100ps (т.е. выравнивается со «статусными» выходными сигналами, что вроде как по описанию Xilinx соответствует задержке 0 тактов, а не 2). Но больше всего мне непонятно, как такие выходные сигналы (с задержкой на 100ps) «стыковать» с остальной частью логики, которая описана естественно без такого рода задержек, как просто «функциональная» схема или «синхронный» дизайн на логическом уровне. Т.е. елсли в проекте стыковать это FIFO ядро, на уровне функциональной симуляции, его входные управляющие сигналы (wr_en, wr_data) не будут иметь «имитируемую» задержку 'after XX ns'. Т.е к примеру диаграмма записи будет выглядеть так: Получается, что с точки зрения остальной «функциональной логики», выходные статусные сигналы empty и data_count будут иметь latency=2. Т.е. любой синхронный процесс «защёлкнет» значение empty/data_count после двух клоков от сигнала wr_en (в момент T=16500ns), т.к. после одного клока (T=16300ns) сигнал ещё не обновился из-за этих 100ps. В то же время у асинхронных процессов эти 100ps будут вызывать glitch-и, и тоже приводить к ошибкам. В конечном итоге, основые вопросы такие. Как работать в «функциональной» симуляции с таким ядром? И почему выходные задержки latency не соответствуют значениям указанным в datasheet? Понимаю, что решение должно быть, но мне оно пока не ясно. Извиняюсь, что так много букв получилось, но не знаю как всё это описать покороче. И это лишь простейший вариант конфигурации FIFO. А что уж будет, если надо использовать скажем разные клоковые домены, в режиме First-Word-Fall-Through, разные Aspect Ratios и т.п.