


FLTI
-
Постов
399 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные FLTI
-
-
Вопрос по блоку Slave_bidir_Tx и шине bidir1_data_bus[15..0] на отправку по схеме Source-Synchronous Output (выдает шину bidir1_data_bus и частоту CLK_TX1). Блок тактируется частотой 125МГц, получаемой на pll_c5gx. Эта же частота уходит вместе с шиной bidir1_data_bus наружу, чтобы приемник этой частотой защелкивал данные.
ИМХО , если частота уходит вместе с шиной bidir1_data_bus наружу, чтобы приемник этой частотой защелкивал данные, то это схема не Source-Synchronous Output, а System-Synchronous Output и соответственно констрейны надо делать иначе.
-
3. взял готовую программную реализацию:
Не могли бы Вы дать ссылку на источник этого кода.
Я его уже видел, но в несколько ином виде, например там не использовалось i2c_wait_rxnack(port) и по-иному описан i2c_wait_tip(long port).
Кстати, компиляция на i2c_wait_rxnack(port) и i2c_wait_tip(long port) выдаёт ошибки в тех местах, где Return.
Как Вы это обошли?
Также мне непонятно что означают и откуда взяты данные константы?
#define I2C_CR_STA 0x80
#define I2C_CR_STO 0x40
#define I2C_CR_RD 0x20
#define I2C_CR_WR 0x10
#define I2C_CR_ACK 0x08
#define I2C_CR_IACK 0x01
#define I2C_SR_TIP 0x02
#define I2C_SR_RXNACK 0x80
#define DELAY_TIME 35
В I2C-Master Core Specification с OpenCores они не значатся.
Ну и в итоге разобрались ли с проблемой?
-
А почему не используете i2c_opencores_hw.tcl и не делеете через QSYS?
А затем .bsf, полученный в QSYS добавляете в .bdf.
У меня встречный вопрос: откуда Вы взяли функцию IOWR_8DIRECT ?
Не встречалась ли Вам функция записи/чтения по I2C Opencores в удобном виде, где в одной строке задаются три параметра:
1). адрес,
2). субадрес
3). что записывается по данному адресу/субадресу и что читается
-
Вы пишите, что для PCIE корки установлено Maximum Payload Size = 128, тогда (по идеи) абсолютно не важно какой Maximum Payload Size у матери, она возвращаемые пакеты должна урезать до 128 байт. Вот если она этого не делает, тогда будут конфликты.
А вдруг у P75 матери Maximum Payload Size < 128 ?
А как вы формируете заголовок пакета? Какие Requester ID и Tag задаете? Другие поля заголовка?И в чем проявляется потеря данных?
Это ядро у меня в виде .qxp, поэтому подробностей не знаю.
Потеря данных - при пересылке host->FPGA вместо потока данных время от времени идут постоянные уровни.
При пересылке FPGA->host такой проблемы нет, плата с этим ядром нормально работает на 300 МБ/с и на P55, и на P75.
То есть дело не в плате, не в ядре, а какая-то особенность материнки.
Возможно, что и на каких-то других материнках проблем не будет, а на каких-то будет.
-
Да вот в соседней теме http://electronix.ru/forum/index.php?showtopic=121074 столкнулся с проблемой, что на матери P75 скорость host->FPGA падает по сравнению с P55.
В ядре PCIe x 4 GEN1 на базе Altera HardIP в настройках PCIE тоже установлено Maximum Payload Size = 128.
Ядро небыстрое, работает на внутренней частоте 125 МГц, поэтому максимум может ~400МБ/c.
Но на P75 матери даже 300 МБ/с не пропускает, идут потери данных, а на P55 всё нормально.
Я пытаюсь понять - в чём разница между этими двумя матерями, что так отличаются скорость в слоте PCIe x 4.
Начать выяснение решил с того, чтобы выяснить - какой у них Maximum Payload Size.
-
По ходу поиска инфы о Maximum Payload Size наткнулся в книге "Юрий Зозуля Тонкая настройка компьютера с помощью BIOS. Начали!" ( Питер; Санкт-Петербург; 2010
ISBN 978-5-49807-693-5 ) на следующее определение:
Maximum Payload Size
Параметр присутствует в некоторых системных платах с шиной PCI Express и задает максимальный размер пакета данных, передаваемого по этой шине.
Возможные значения – 128, 256, 512, 1024, 2048,4096. Они определяют максимальный размер пакета в байтах.
По умолчанию устанавливается значение 4096, которое не следует менять без особой необходимости, поскольку при этом обеспечивается максимальная производительность PCI Express.
Неужели Maximum Payload Size по умолчанию устанавливается значение 4096?

-
Облазил весь Рciscope, но о Maximum Payload Size ничего не нашёл. В нём точно это есть?
-
Под виндоусом можно попробовать в программе pciscope посмотреть.
Подскажите пожалуйста где в Рciscope есть данные о Maximum Payload Size?
-
Какой утилитой можно узнать Maximum Payload Size материнской платы?
-
Народ. Странность. Есть PCIe, на альтере сделаный (HardIP 4x Gen1). Если плату воткнуть в тот PCIe который прямо из CPU идет, то работает. Если воткнуть в тот сплот что идет из чипсета, то не работает. Операционка виснет (и линух и винда). Дос работает. Что может быть?
На каких матерях Вы проверяли? У них несколько PCIe x 4 слотов?
Как распознали - какой прямо из CPU идет, а какой идет из чипсета?
В чём в итоге была проблема?
-
Здравствуйте!
Есть ли какое-то отличие в работе слотов PCIe x 4 на разных материнских платах, например на 55-ом интеловском чипсете и на 75-ом интеловском чипсете?
Судя по описанию на материнской плате на 55-ом интеловском чипсете PCIe x 4 соответствует GEN1, а на 75-ом - уже GEN2.
На своей тестовой плате с ядром PCIe x 4 GEN1 заметил, что скорость передачи host->FPGA на 75-ом чипсете меньше, чем на 55-ом.
Насколько точно меньше, пока померить не могу, но видно , что поток 300 МБайт/с через host->FPGA на 55-ом нормально проходит, а на 75-ом идут потери данных.
Вот как устроено это ядро PCIe x 4 GEN1 на базе Altera HardIP :
Writes "host->FPGA" are made by DMA reads by the FPGA in two steps: The FPGA sends a read request packet and the host sends the data in a completion packet.
The FPGA can have several read requests pending for the same stream.
Таким образом, пропускная способность зависит от того, насколько быстро откликается host, т.е материнская плата.
Так вот получается, что материнская плата на 55-ом интеловском чипсете откликается быстрее, чем на 75-ом интеловском чипсете.
Почему, в чём может быть причина и как это исправить?
-
Нашёл причину!
Оказывается вместо 37,5 Ом был ошибочно куплен и поставлен 37,5 кОм :(
В итоге впараллель 2 штуки по 75 Ом решили проблему!
Всем спасибо, кто откликнулся с помощью! :cheers:
-
Можно аттенюатор по входу попробовать.
Аттенюатор как внешний модуль до BNC-разъёма подключить или добавить в схему?
Внешний модуль до BNC-разъёма исключается.
Добавить в схему - насколько это громоздкая вещь?
Я с ВЧ никогда дело не имел, но вот сейчас неожиданно столкнулся...
P.S. Напоминаю, что проблема только на 3ГГц, а на 1,5ГГц проблем нет в обоих случаях ( что с пальцем, что без него ).
-
Прикосновение пальцем - это внесение затухания в первую очередь - широкополосное согласование. Уменьшение уровня сигнала, улучшение КСВН, уменьшение переотражений...
То есть по-простому ( добавить одну ёмкость или индуктивность ) прикосновение пальцем никак не сымитировать?
-
А если серьёзно, то от прикосновения (смотря куда) будет вноситься в первую очередь ёмкость 5-100 пФ (зависит от состояния пальца и ещё много чего).
Прикосновение именно на то место на печатной плате ( все компоненты SMD0603, а индуктивность 0402 ), где расположены эти элементы. Это площадка размером примерно 5 х 5 мм.
Куда бы Вы в этой схеме посоветовали бы добавить ёмкость 5-100 пФ, чтобы сымитировать прикосновение пальца?
Учитывая миниатюрность размещения особо не поэкспериментируешь...
-
Здравствуйте!
На что влияет прикосновение пальцем к данной схеме, которая выполняет роль входного каскада для согласования сопротивлений и компенсации Return loss перед последующим Cable Equalizer, который включен по дифференциальной схеме?
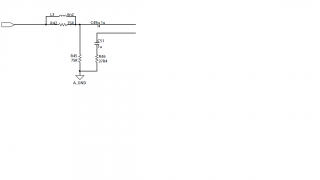
Прикосновение пальцем к данной схеме уменьшает или увеличивает индуктивность или добавляет ёмкость?
Если так, то примерно на сколько уменьшает или увеличивает исходную индуктивность 6,2нГ или куда и какого примерно номинала добавляет ёмкость?
На вход схемы подаётся сигнал 3 ГГц c кабеля через BNC-разъём.
Вопрос связан с тем, что после прикосновения пальцем к данной схеме в последующей схеме не происходят ошибки в приёме передаваемых данных, а без прикосновения ошибки есть.
Если частоту сигнала снижаю вдвое ( с 3 до 1,5 ГГц ), то проблем нет в обоих случаях ( что с пальцем, что без него ).
-
В Москве требуется ремонт осциллографа Agilent DSO3062A.
Не работает горизонтальная развёртка на верхних частотах.
В режиме самокалибровки при калибровке горизонтальной развёртки зависает.
С предложениями пишите в личку.
-
Варианты:
1. простой способ (с привязкой к конкретной ПЛИС): edif, vqm, qxp - практически бесплатно;
Поясните пожалуйста, как именно .qxp могут быть защищены привязкой к конкретной ПЛИС?
К конкретной ПЛИС в смысле - к её конкретному серийному номеру или как-то иначе?
То есть поставщик .qxp заранее узнаёт у потребителя серийный номер ПЛИС, в которой этот .qxp будет использоваться и в .qxp делает привязку к этому серийному номеру?
-
Проверил прохождение сигнала напрямую с АЦП на ЦАП как бы ”в отсутствии ПЛИС” очень просто - вот по такой схеме ( проверено на железе ):

А вот как в реальной схеме в констрейнтах set_input_delay и set_output_delay правильно задать значения min и max по данным из даташитов на АЦП и ЦАП ?
Вот реальная схема, где красным обозначена внутренняя часть схемы, которая не влияет на констрейнты:
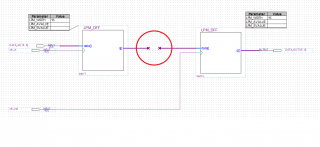
АЦП тактируется клоком clk_in, а ЦАП тактируется клоком clk_out.
Данные из даташитов на АЦП и ЦАП даны в предыдущем посте.
Эту схему пока не могу проверить на железе, но заранее хотел бы для неё выяснить - как в set_input_delay и set_output_delay правильно задать значения min и max по данным из даташитов на АЦП и ЦАП?
-
Здравствуйте!
Исходные данные:
16-битный поток с АЦП подаётся на входы ПЛИС Altera Cyclone IV GX и после обработки в ней выдаётся на ЦАП, подключенный к выходу этой же ПЛИС.
На начальном этапе тестирования требуется подключить АЦП и ЦАП напрямую через ПЛИС, чтобы проверить прохождение сигнала напрямую с АЦП на ЦАП как бы “в отсутствии ПЛИС”.
Для этого в ПЛИС задаю такую схему, в которой вход по схеме Source-Synchronus Input, а выход – по схеме Source-Synchronus Output.
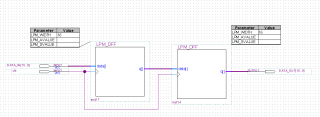
Исходные данные, приведённые в даташите.
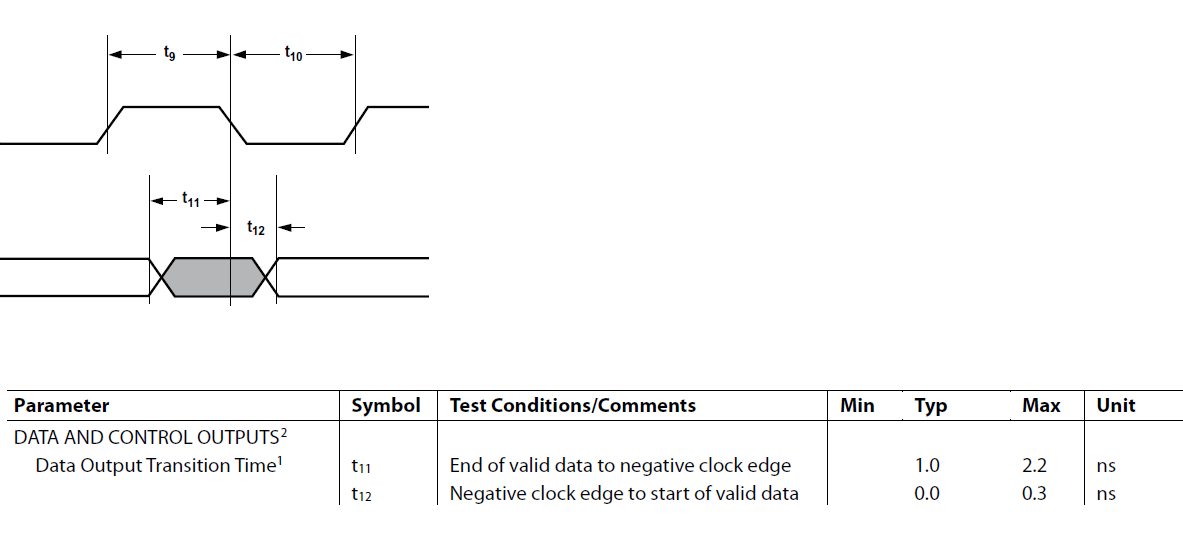
На АЦП:
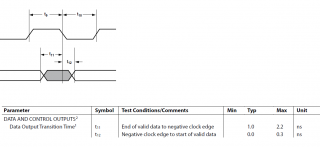
Период клока 6.73 нс, то есть t9=t10=3.367 нс
На ЦАП:
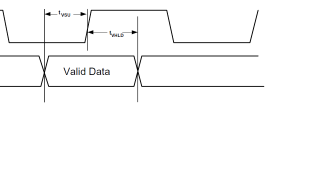
Input Data Setup Time = MIN tVSU = 1 nS
Input Data Hold Time = MIN tVHLD = 0.7 nS
Типичные и максимальные значения tVSU и tVHLD не указаны ( стоит прочерк ).
Период клока 6.73 нс.
Подскажите пожалуйста правильно ли я задаю для констрейнты для этой схемы?
Теорию изучал, а вот чтобы параметры конкретных АЦП и ЦАП заносить в констрейнты , ни разу не приходилось.
Для АЦП:
create_clock -period 6.73 ns -name {clk_ADC} [get_ports { clk }]
create_clock -period 6.73 ns -name {virt_clk_ADC}
set_clock_groups -exclusive -group {clk_ADC virt_clk_ADC}
set_input_delay -clock {virt_clk_ADC} -max 0.3 [get_ports {DATA_IN[*]}]-clock_fall
set_input_delay -clock {virt_clk_ADC} -min 0.0 [get_ports {DATA_IN[*]}] -clock_fall
Для ЦАП:
create_clock -period 6.73 ns -name {clk_DAC} [get_ports {clk}]
create_clock -period 6.73 ns -name {virt_clk_DAC }
set_clock_groups -exclusive -group { clk_DAC virt_clk_DAC }
set_output_delay -clock {virt_clk_DAC } -max 1.0 [get_ports {DATA_OUT[*]}]
set_output_delay -clock {virt_clk_DAC } -min -0.7 [get_ports {DATA_OUT[*]}]
-
3*1080 - это вообще не рекомендуемая комбинация препрегов. В виду их тонкости и "хлипкости" ткани.
При попытке "пожать" их посильнее получим кроме нужной толщины еще и смятую стеклоткань в структуре платы, что грозит внутренними напряжениями и дефектами при монтаже/эксплуатации.
Оно Вам надо?
Однако в таблице, которую Вы размещали ( см. сообщение 55, там скопирована эта таблица ) как раз есть комбинация 3*1080, а комбинации 1080 + 2116 почему-то нет.
А теперь Вы говорите, что 3*1080 - это вообще не рекомендуемая комбинация препрегов.
Каково Ваше мнение о комбинации 1080 + 2116?
Она тоже даёт толщину примерно 0,17мм , то есть ту же самую, что и 3*1080.
-
Правильно ли я понимаю, что если бы слой Au был бы слишком тонким ( например 0,1 - 0,2 мкм ), то это бы привело к тому, что разъём с таким покрытием:
1). был бы слишком жёстким, на нём не оставались бы следы от ламелей ответной части ?
2). на нём образовывалась бы окисная плёнка, которая могла бы вызвать нарушение контакта ?
3). цвет ламелей был бы не характерный золотой, а ближе к цвету никеля, что как раз бы и служило визуальным подтверждением слишком тонкого слоя Au ?
-
Заказывал в Китае платы с Hard Gold Ni7Au1.27.
Есть еще гальваническое покрытие Flash Gold (под пайку, альтернатива иммерс.золочения), там примерно Au0.25
Уточните пожалуйста, Hard Gold Ni7Au1.27 - это на ламелях разъёма, толщина подложки 7 мкм Ni и поверх него 1.27 мкм Au?
-
Если предполагается платку активно юзать - часто втыкать и вытыкать, то необходито покрывать ламели твердым золотом (HardGold). Техпроцесс называется Gold Fingers. Особенность такого покрытия - высокая износостойкость, поскольку используется золото с присадками молибдена (если память не изменяет, технологи - поправте если ошибся), имеющее более высокую твердость по сравнению с обычными покрытиями. Толщина покрытия - Ni: 3,0-7 мкм / Au: 0,125-0,75 мкм (значения разнятся у разных производителей).
Хотел бы уточнить по поводу толщин покрытия HardGold / Gold Fingers.
Действительно типовые значения слоя никеля и золота примерно такие : Ni: 3,0-7 мкм / Au: 0,125-0,75 мкм, т.е толщина никеля примерно в 10 раз больше толщины золота?
Почему спрашиваю - я видел в тех. данных у одной из китайских фирм , что это соотношение не 10:1 , а 100:1.
Thickness of Gold Finger Au: 1μ", Ni: 120μ"
Действительно так всё поменялось с 2009 года ( дата поста от bigor , который я цитировал ), что в HardGold / Gold Fingers золото стали использовать меньше или это особанность данной фирмы?





Source-Synchronous Output
в Работаем с ПЛИС, области применения, выбор
Опубликовано · Пожаловаться
Вот здесь это более понятно описано: http://embedders.org/content/timequest-dly...rfeisov-raznykh ( автор - модератор этого подфорума )
На 3-й странице по ссылке описан System-Synchronous Output, но лучше начать с 1-ой.