


Nick_K
-
Постов
860 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные Nick_K
-
-
У меня сложилось впечатление, что это конкретно проблемы с оболочкой Waveform. В моём случае просто сохранял результаты в CSV и переоткрывал другим вьювером. Хотя не уверен, что такой функционал сработает в ILA.
И ещё попробуйте оставить минимум сигналов в ILA (создать с нуля и добавить до 10 пробников) иногда из-за этого тоже бывает тормозит
-
Я бы предложил ForgeFPGA от Renesas, но не уверен что проект добрался до розничного маркета.
-
2 hours ago, TRILLER said:
На моей памяти никогда не было "внутреннего" интерконнекта между триггерами у них.
Чисто внутреннего - не было, всегда коннект идёт через интерконнект матрицу, но так, чтобы в одном слайсе использовались подряд все флопы (к примеру для таймеров), можно сделать физическими констрейнами.
-
2 hours ago, blackfin said:
Внутри SLICE/CLB всё жестко соединено проводами и задержки внутри одного SLICE/CLB не больше сотни пс.
Всё верно. Чисто внутри Слайсов (за Альтеровское не ручаюсь) задержки по разным путям отличаются незначительно (у меня было до 25-50 ps). Проблема вылазит позже, так как разные выходы/входы Слайса подключены к матрице интерконнекта по разному и там задержки могут быть и по 100-200 ps запросто.
-
3 hours ago, dxp said:
А Quartus вполне приличный тул, и поддержка того же SV в нём началась раньше и была лучше, чем в Synplify
Так как я не сильно пользовался Квартусом, не могу предъявить сильные аргументы против него (но могу сказать, что Sinplify и вправду хорош).
Но ребята пользуются Альтеровскими чипами и говорят, что там даже банальное always_comb не работает как нужно (есть подозрение, что это про какие-то вложенные конструкции).
Из-за чего во всём коде после прототипинга стоят always@*, которые потом синтезируются трудноуловимыми Латчами.
Вот такие дела)
-
2 hours ago, dxp said:
А Quartus на том же коде пропускал массу всего, к чему придирался Synplify (кстати, по делу придирался по большей части), зато вот на это ' + 1' ворчал.
Всё потому, что Симплифай - это лидирующий производиткль тулзов для SPnR, а Квартус - условно-бесплатная поделка индусов, чтобы просто работало. Плюс есть мысль, что Симплифай имеет на борту автоматический LEC, который и выдаёт все нужные ворнинги
-
Попробуйте посмотреть тут:
40090 - Design Assistant for XST - Help with Register Duplication and fanout (xilinx.com)
Вроде бы ситуация вполне подобная.
Сама настройка была в более ранних версиях, а теперь видимо является частью параметра register_balancing.
-
Во-первых для указанной технологии должна применятся настройка register duplication (на сколько помню).
Во-вторых, для того, чтобы у Вас был небольшой фанаут... задайте его вручную) порядка 75 подключений будет вполне достаточно и синтезабельно
-
13 minutes ago, Freibier said:
Уж как только не пробовал, никак не понимает.
Можете написать полностью весь констрейн согласно правилам тикля вайлдкарты?
Если раговор про -regexp, тогда все пины VD с любым номерным значение будет выглядеть так:
get_ports -regexp {VD\[[0-9]\]}
По крайней мере у меня так работает.
Самое интересное, что у меня работает так тоже:
get_ports {VD\[?\]}
И так
get_ports "VD*"
Так что мне кажется нужно просто понять какой аннотацией пользоваться и так и писать. Проверить можно всегда в открытом проекте в консоли тикля.
-
34 minutes ago, Freibier said:
set_input_delay -clock clk 0.8 [get_ports {VD[5] VD[4] VD[3] VD[2] VD[1] VD[0]}]
По правилам тикля вайлдкарты используются в кавычках.
get_ports "VD\[*\]"
должно работать. Ну или просто звёздочка в конце, без квадратных скобок.
-
У меня похожее поведение было в следствии внутренних констрейнов ILA.
В частности просто прикрутив клоковую к ILA без всяких дебажных сигналов собирало нормально проект, а без ILA - всё валилось на STA и очень долго собирало (утилизация около 15%).
Увы как решил вопрос - не припоминаю. Наверное просто пересоздал все IP и пересобрал проект с нуля, благо там не так много было модулей.
-
3 hours ago, yes said:
upd2: да вроде ОК - с массивом (это я гугль спросил) - если unpacked массив packed массивов - то вначале перебираются unpacked индексы (в нормальном порядке - как в С), а затем packed (и опять как в С)
Да, вполне возможно. Я просто помню, что наступал на эти грабли пару раз, считая не с той стороны. Вот видно не с той что нужно и запомнил.
-
38 minutes ago, yes said:
logic [MBLOCKS-1:0][15:0] udout;
Если мне не изменяет память (могу ошибаться), то при аннотации типа:
genvar k; generate for(k=0; k<MBLOCKS; k++) begin : mem_pool ... udout[k] ... end endgenerate
Индекс 'k' будет перечисляемым для диапазона [15:0], а не как хотелось [MBLOCKS-1:0], потому как индексация идёт от переменной влево для упакованых и вправо для неупакованных массивов.
А вообще попробуйте запись типа:
csa #( .p_synch_rst (1), .p_preload (0), .p_int_res (p_int_res * p_num_adders)) carry_adder [ 1 : 0 ] ( .i_clk (i_clk), .i_nrst (s_nrst), .i_csa_ce ({s_owerflow_0,i_en}), .o_overflow ({s_owerflow_1,s_owerflow_0}), .o_csa_count ({r_csa_1_cnt,r_csa_0_cnt}));
Без вских дженериков и прочего. Вивада поругается немного, но такая конструкция вполне допустима
-
14 minutes ago, Bovee said:
ну вот допустим строчка:........ то есть при изменении сигнала LD сигналу D идет загрузка???? не совсем в голове укладывается((((( также и про if(SHFT)....
if(SHFT) begin D <= {InS, D[3:1]}
if(LD) begin D <= InP;
Вы сколько занимаетесь разработкой/изучением схемотехники?
Это обычный enable для флопа (читай регистр).
Если такие элементарные понятия не укладываются в голове, то нужно почитать детальнее соответствующую литературу.
-
Код и фактическое наличие такого флопа - две разные вещию Скорее всего это описание некого кастомного компонента.
Данный RTL реализует последовательную загрузку через serial порт InS и сдвигает по одному биту при активном сигнале сдвига (SHIFT).
Если же подать единичное значение на сигнал загрузки (load - LD) произведётся запись из параллельного порта InP во все соответствующие флопы.Хотя куку было упомянуто - описание достаточно корявое
-
На мой достаточно дилетантский взгляд фазовое детектирование можно увеличивать практически до бесконечности. Вопрос в данных, сколько они длятся. Если длинна каждого бита наносекунда и менее, тогда можно и не пробовать (разве что как-то подстраивать гигабитные трансиверы). Если данные висят до десятков нан, тогда можно определить фазирование запросто до 400-200 ps и немного заморочившись до 1-0.5 ps. Тут ещё важный момент, какой допустимый оффсет для получения результата.
-
Спасибо. По сути это и есть интересный мне момент.
От себя добавлю, возможно изменив команду с добавлением $arg получится запускать Виваду и передавать ей нужные аргументы:
58 minutes ago, 5EN5E said:"command": "vivado -mode tcl -source c:/utils/nonproject/synth_step.tcl $arg"
-
10 minutes ago, 5EN5E said:
Тогда остается вопрос по написанию taskов в vscode, чтоб этот же скрипт с новыми параметрами передать в существующий shell.
Вот у меня был собственно вопрос как эти самые task'и создавать. Может и себе смогу чего оптимизировать в процессе.
Это скорее уточнение предыдущего вопроса.
-
3 minutes ago, 5EN5E said:
При Вашем подходе получается сквозной маршрут сборки, т.е. если мне нужно сделать place, то обязательно выполнится этап синтеза. Я бы хотел отсинтезировать проект, запустить ГУЙ, поковырять DEBUG, поиграться с репортами, выйти из ГУЯ. Если все ок, то запустить сборку следующего этапа.
Это то, что я указал последним. Придётся добавлять аргументы на запуск мастер скрипта (по крайней мере у нас так сделано) и получится нечто:
set run_step=place // выполнить присвоение в обычной консоли или через bash/bat скрипт // Далее идёт вместимость собственно мастер скрипта if { $env(run_step) == all } { source synthesis.tcl source place.tcl source route.tcl source program.tcl } elsif { $env(run_step) == syn } { source synthesis.tcl } elsif { $env(run_step) == place } { source place.tcl } elsif { $env(run_step) == route } { source route.tcl } elsif { $env(run_step) == program } { source program.tcl } else { puts "Uncorrect argument passed" }
-
36 minutes ago, 5EN5E said:
Я бы хотел сборку осуществлять по дизайн флоу, как в Vivado, т.е. по шагам. У меня для каждого этапа написан скрипт, а вот запуском скриптов управляют taskи vscodа. У меня собсно вопрос по написанию этих самих taskов, т.к. у меня не получается передать следующий скрипт в уже запущенный Shell Vivado. Мастер скрипт просто прогонит все нужные мне скрипты за раз, а это не то что мне нужно.
Немного не согласен. Мастер скрипт будет вызывать нужные скрипты один за другим в соответствии с вышеупомянутым флоу при этом дожидаясь выполнения соответствующего шага.
Грубо говоря мастер скрипт состоит из:
source synthesis.tcl source place.tcl source route.tcl source program.tcl
соответственно каждый скрипт будет запущен по очереди и только после завершения предыдущего (при условии что в скрипте синтеза есть команда запуска собственно синтеза launch_runs synth_1 и т.д.).
Сложности начнутся, когда нужно сделать только синтез, к примеру. Тогда придётся городить скрипт с аргументами запуска.
-
3 minutes ago, 5EN5E said:
Как будет понимание и реальные результаты, поделюсь. Задал вопрос на Реддите, пока ответов по существу нет.
Ну попробуйте через мастер скрипт всё сделать. Уверен так будет проще всего.
-
On 1/21/2022 at 4:07 PM, 5EN5E said:
2. Хочу реализовать сборку проектов Vivado в non-project режиме. Написал тиклёвые скрипты по сборке, которые кушает Shell Vivadы. Создал task для VSCode, который запускает Vivado и передает ему скрипт. При запуске task успешно запускается Shell Vivado и исполняется скрипт, после чего shell ожидает новых команд. Как мне в уже запущенный shell передать другой скрипт? Мои эксперименты с taskами закончились на том, что запуск taska приводит к запуску нового терминала и у меня никак не выходит обратится к терминалу с shellом Vivadы.
А можно какой-то гайд или может даже пример, так как данный вопрос очень интересен.
У нас фактически используется такой же подход как non-project режим от Вивады. С той лишь разницей, что запускается оболочка и передаётся мастер скрипт, который в зависимости от аргументов выполняет тот или иной шаг (или весь SPnR) и выходит через exit из инструмента (по любой из ошибок или по успешному завершению). Возможно есть опции запуска скриптов по очереди или запуска следующего, но это скорее всего неудобно и принесёт много лишних действий
-
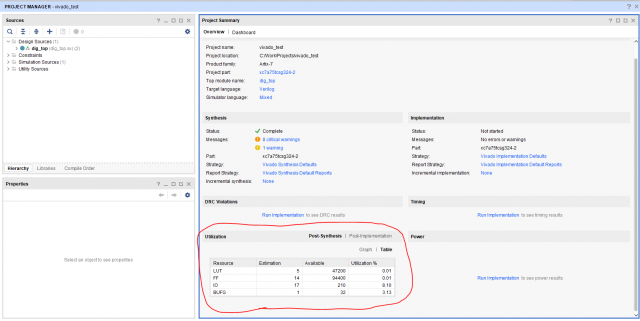
6 hours ago, eugen_pcad_ru said:
Для примера на картинке сколько получается?
Быстрый поиск по просторам дал следующее значение: 6 двухвходовых AND гейтов соответствуют 1му LUTу.
Соответственно данный проект соответствует 30 двухвходовым AND гейтам. -
Почему очень грубо? Для проектов в Виваде в GUI есть финальный репорт, который показывает занятость всех используемых макроячеек (LUT, BRAM, FF и т.д.). Взяв структуру ЛУТа и перемножив - получите более-менее реальные значения в логике, откуда нехитрыми манипуляциями мождно получить значение в вентилях.

Сигнал ресет
в Языки проектирования на ПЛИС (FPGA)
Опубликовано · Пожаловаться
Разницы нет, если только для платформы нет каких-либо ограничений. Иногда бывает, что ПЛИС не содержит понятия, к примеру, синхронный сброс. В таком случае будет дополнительная логика на входах сброса (флоп + гейты).
В таком случае могут быть сложности с утилизацией/плейсментом/деревом/таймингом.
Для ненапряжных проектах по сути не играет роли.