


Lionet
-
Постов
36 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные Lionet
-
-
Добрый день
Есть Vivado и SDK, версия 2014.4 и отладочные платы (ZC706, ZedBoard и другие).
Есть несколько сложностей с корректным взаимодействием между Вивадой и SDK, и вообще
иделогией Xilinx в этом плане. Разъясните, пожалуйста, кто "в теме".
1. Vivado: Export hardware - здесь момент следущий:
опция "Include bitstream" - насколько я понимаю, если нам нужен только процессор (PS) без программируемой логики (PL),
то создаём Block design, добавляем Zynq Processing system, настраиваем, экспортируем без Include bitstream (его и не будет),
работаем в SDK как с обычным ARM-процессором. Так?
Если мы что-то насоздавали в ПЛИС, то генерируем bitstream и экспортируем с ним. Но тогда возникает проблема
синхронизации файлов - копия битстрима уходит в SDK и, если мы потом что-то изменим в FPGA-коде, SDK всё равно будет
использовать старый вариант. Можно, конечно, попробовать обновить данные путём Change Hardware Platform Specification в SDK
или вручную скопировать новый битстрим, но это какие-то костыли. Непонятно.
2. SDK. Создание конфигурации отладки/выполнения (Debug/Run configurations) приложения.
Вообще, по логике должно быть два варианта:
1) полный сброс системы, заливка указанного пользователем bitstream, загрузка в память приложения и его отладка.
Настройку процессора можно было бы сделать в виде Си кода в начале приложения ну или tcl-скриптами, как сейчас, но
как-то более прозрачно.
2) сброс только процессора (если в ПЛИС ничего менять не надо, для экономии времени), инциализация процессора,
загрузка и запуск приложения.
У Xilinx всё как-то хитрее - в окнах Run Configurations, Debug Configurations и Program FPGA
кнопки Search (которая позволяет, видимо, выбрать файл (bitstream или скрипт) из текущей Hardware Platform Specification) и
Browse (позволяющая выбрать произвольный файл) становятся активными и неактивными по каждый раз
по-новому по какому-то неведомому алгоритму.
Опция Run ps7_post_config (которая отвечает, судя по Гуглу, как раз за включение мота PS-PL и выдачу тактовых
сигналов и сброса в PL от PS) никак не даёт себя включить (хотя в других проектах бывает доступна).
В общем, чуть-чуть сильно запутался (с)
-
Концептуально-практический волрос: сейчас все IP-cores для потоковой обработки данных (DSP FIR, FFT и прочее) реализуются с
использованием шины AXI-stream - по крайней мере, в Xilinx Vivado DSP ядер с классической шиной "данные-и-стробы" уже нет.
(То, что другие типы ядер используют вообще "полноформатную" AXI4 - это отдельная проблема).
Собственно, вопросы:
- разве использование специфической шины не ведёт к дополнительным накладным расходам ресурсов ПЛИС?
- что делать, если надо реализовать какую-то bitwise-magic - вытащить статусный бит, инвертировать, "обрезать" разрядность и т.д.?
Ранее всё это делалось достаточно нативно, поскольку линии данных доступны непосредственно.
Получается, что на каждый "чих" теперь нужно реализовывать своё ядро с интерфейсами AXI и добавлять в интегратор (для Vivado)?
- собственно, как правильно реализовать поддержку AXI-stream? Толковых мануалов и примеров найти пока не удалось.
Аналогичные вопросы и по AXI (не stream). С готовыми ядрами всё красиво - собирается, настраивается, даже как-то "подтягиваются" драйвера в devicetree
(хотя уже не всегда и не для всего). А вот как что-то своё, написанное на том же Verilog и нормально работающее в ISE, сделать совместимым с нетривиальной шиной - проблема...
-
К сожалению, что-то никак я не освою работу с обсуждаемым предметом.
Кроме, собственно, того, что Эклипс вызывает не очень хорошие эмоции, никак не разберусь с тулчейном.
Есть демо-проект от терровской платы с stm32f107, несколько статей в pdf-ках. Отладчик их же te-arm-link.
При заливке бинарника из проекта (т.е. который уже был в архиве) всё работает нормально. А вот скомпилить заново такой же -- ну никак..
Основная проблема сейчас -- unresolved inclusion заголовков стандартной библиотеки Си (типа stdint.h) (path к тулчейну прописан)
Пытался разобраться со структурой тулчейна -- непонятно, почему некоторые файлы повторяются несколько раз, почему папка include в корне пустая... и т.п. Помогите разобраться, пожалуйста. Очень хочеться понять.
На всякий случай: ОС ВинХР, 32bit, Eclipse IDE for C/C++ Developers Helios Service Release 2
-
>> 160$
Какой-то он дорогой. Можно BF561-х поставить линейку и соединить через SPORT и PPI.
И будет вам кластер или конвеер обработки. Во всяком случае, софт будет пистать, легче если его пофункционально разложить по кристаллам.
А вот вроде как раз SPORT и реализует нужный мне интерфейс TDM. Так что его занимать нельзя.
Сейчас появилась мысль попробовать с каким-нибудь одним DSP. Но что-то не знаю, какую плату взять, тем более, что в той же терре всё весьма дорогое, а ждать из буржуинии и таможить неохота)
-
Вот это уже интересно. Если удастся добыть в наших краях хотя бы за 450 баксов (у TI - 399).
Правда, пока ещё непонятно, что там с TDM интерфейсами... И что ешё надо закупать. Отладчик там вроде строенный. А вот на среду разработки не хочется разоряться.
-
Если вернуться к картинкам, то на первой получается такая структура:
N АЦП -> коммутатор/микшер на FPGA -> N DSP -> еще один коммутатор/микшер на FPGA -> N ЦАП + некоторая общая схема управления, которая и раздает задания для каждого компонента.
На второй же просто несколько трактов обработки с объединенными входами и независимыми выходами.
По картинкам получается так, да. Но по задаче -- совсем не то, увы ( Разобрать и посмотреть, к сожалению, нельзя. Гугл тоже не помогает.
В конце концов, если отвлечься от звука -- как-то же делают блоки из нескольких DSP...
-
Опубликовано · Изменено пользователем Lionet · Пожаловаться
Если есть, допустим, 32 входных и 32 выходных канала 24 бит/96 кГц оцифровкой, то в любом случае пара-тройка TDM интерфейсов такую пропускную способность не обеспечит. А ведь это средненький пульт по числу каналов.
То же, собственно, касается и производительности DSP. Звук процессить, конечно, не так сложно, как HD-видео, к примеру.
Но при таком потоке... У меня один эквалайзер получился что-то вроде 10 млн умножений с накоплением в секунду на канал.
А ещё динамическая обработка (вполне возможно, что с преобразованием Гильберта) и всё это на каждом канале.
Плюс явно отдельные DSP для пространственной обработки (реверберация и проч.)...
Как-то так... Да и вообще, думаю, не будет плохо разобраться, как же всё-таки делаются DSP-кластеры)
P.S. На картинках DSP между собой никак не связаны, т.е. никакого кластера нет. Есть несколько параллельно работающих узлов с общим управлением.Самое главное "П.С." я не чуть не пропустил. Это структурные схемы именно микшеров. А там (я с таким оборудованием профессионально работаю) сигнал можно направить куда угодно. У них, да, как-то странно получилось -- как будто входы и выходы группами. Но, сами понимаете, как минимум, если есть 10 входов для микрофонов и 1 главный выход на "колонки", то в общем случае сигнал на выход надо смешивать со всех входов )
-
Добрый день!
Заинтересовался темой многоканальной цифровой обработки аудиосигналов (с сфере проф. оборудования - театрального, концертного)
Добыл даже несколько Cirrus-овских восьмиканальных АЦП и ЦАП для экспериментов.
А вот собственно по ЦОС возникло несколько проблем (не считая стоимости отладочных плат с DSP):
1) АЦП/ЦАП имеют интерфейс TDM, а в DSP таких интерфейсов 1-2, таким образом много не подключишь;
2) алгоритмы бывают достаточно сложные (сейчас в Матлабе экспериментирую с параметрическим эквалайзером на FIR-фильтрах),
соответственно одного DSP может либо не хватить, либо это будет что-то очень дорогое.
Поиск Гуглом дал достаточно мало информации по ЦОС именно в таких задачах, но кое-что нашлось:
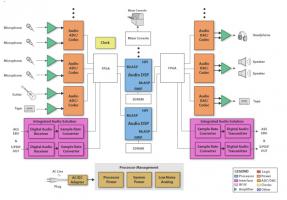
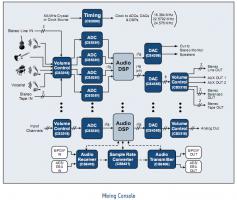
Т.е. предлагается использовать именно несколько DSP, как мне хотелось.
Ключевой вопрос: как реализовать то, что на рисунках обозначено тремя вертикальными точками?? т.е. связь DSP между собой?
При этом, в тех же микшерных пультах сигнал с любого входа может быть подан в различных пропорциях на практически на любой выход (да ещё и с разными обработками). Соответственно, пути сигнала могут быть весьма длинными и запутанными. Так что связь должна быть шустрая и многоканальная...
В документации поискал, но, честно, ничего не нашёл...
Может кто подскажет правильное решение и, заодно, вариант DSP для оптытов (желательно, чтобы отладочную плату можно было приобрести)?
Такой же вопрос интересует в отношении ARM процессоров - можно ли объединять несколько в кластер.
Но пока в разделе ARM тему создавать не буду. Если что - потом выделим в отдельную тему.
Заранее спасибо!
-
Немного не по теме. Но
Новичкам на форуме, видимо, недоступны личные сообщения.
Спасибо, _Vova, что ответили в ICQ.
По сабжу: травить плату некогда, подключился пока проводками к технологическим "пятачкам" на поверхности.
В UART пошёл отладочный вывод загрузчика (но он майкрософтовский, походу, позволяет грузить новые прошивки только через USB или сеть, - этого там само собой нет, оно должно быть на "матернке"), вроде начинает грузиться ВинСЕ, но ей, думаю, нужен как минимум экран...
Путаюсь запустить Линух с SD карты, но то ли не так её форматирую и заливаю загрузчик, то ли подключил не так... Вывода отладки от u-boot не видно.
Документация вообще кривоватая какая-то. Дали 3 Гб данных средней полезности (смайл)
-
нашел все-таки отладку и тп- Custom base board со странички mini6410.
да, похоже, паяться придется проводами.
всем спасибо, тему можно закрыть
Добрый день!
У меня такая же плата и такая же проблема.
С арм-мами только разбираюсь, с платой повезло не очень...
Не поможете, раз у Вас получилось?
Можно постучаться в ICQ -- 2 три 7 четырe 05 56 нoль
Заранее спасибо!!


Интерполяция сигнала с получением двух отсчётов за такт
в Алгоритмы ЦОС (DSP)
Опубликовано · Пожаловаться
Есть модуль ЦАП, принимающий данные по два отсчёта за такт обмена. Т.е. частота оцифровки сигнала 500 МГц, а обмен идёт на 250 МГц, но по два отсчёта. Модуль подключён к ПЛИС.
Есть сигнал с частотой оцифровки 250 МГц. Соответственно, необходимо произвести передискретизацию (интерполяцию) сигнала на частототу оцифровки 500 МГц и, далее, группировку симплов парами.
Проблема в том, что привычные методы (например, FIR и CIC ядра для ПЛИС), выдают по одному отсчёту за такт и требуют тактовой частоты не менее 500 МГц, соответственно.
На такой частоте проект у меня не собирается даже в пустой ПЛИС.
Само по себе это странно, используется Kintex-7, Xilinx FIR пишет в конфигураторе допустимую тактовую до 700 с лишним МГц, но, возможно, проблема в том, что используется LabView FPGA и это добавляет
какие-то дополнительные модули, не дающие проекту собраться на такой частоте. На 250 МГц всё собирается нормально даже в больших проектах.
Есть ли какие-то методы, позволяющие проводить интерполяцию "параллельно", получая сразу N-й и N-1 отсчёты выходного сигнала?