


FLTI
-
Постов
399 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные FLTI
-
-
soft-core - это реализация PCIExpress без использования аппаратного блока PCIE.
Спасибо, совсем забыл , ведь у LXT серии есть GTP Transceivers , с использованием которых и реализовано PCIe x 4 на Спартан-6.
-
В моём компьютере PCI Express 2.0
И даже PCIe x 1 слоты PCI Express 2.0? Если так, то назовите пожалуйста эту мать.
Virtex 6 поддерживает PCIE v2.0 и я собираюсь сделать такую реализацию.Наверное на Artix-7 подешевле будет.
-
dsmv, хотелось бы услышать Ваше мнение - что такое soft-core x4 PCIe на Spartan-6 и что можно вытянуть из Spartan-6 через PCIe x 4 ?
Среди Key Features там упоминается PCI Express x4 end-point.
http://www.xilinx.com/products/boards-and-...EV-LX150T-G.htm
-
dsmv, а пробовали ли Вы Ваше ядро на PCIe GEN2?
Удалось ли получить увеличенные скорости по сравнению с GEN1?
Кстати, есть ли сейчас матери со слотами PCIe x1 GEN2?
Будет ли встроенное Spartan 6 ядро PCIe x1 работать на PCIe x1 GEN2 с увеличенной скоростью?
-
Вот результаты измерения.
Компьютер - Intel I7 2.8 ГГц, системная плата GIGABYTE GA-P55-UD6
Модуль AMBPEX5 установлен через переходник x1
Вывод данных ( из компьютера в устройство )
1. системная память (непрерывная) 128 МБайт - 201 Мбайт/с
2. пользовательская память (разрывная) 128 Мбайт - 201 Мбайт/с
В моём контроллере дескрипторы объедены в блок дескрипторов.
Посмотрите мои доклады: http://ds-dev.ru/projects/ds-dma/wiki/%D0%...%86%D0%B8%D0%B8
Там же есть исходный код нового контроллера.
А если Ваш код контроллера, который в Virtex 5 давал 201 Мбайт/с разместить в Спартан-6 используя его аппаратное ядро PCIe x 1, то можно ли ожидать получение таких же скоростей 200 Мбайт/с ?
Или в Virtex 5 есть нечто, чего нет в Спартан-6 из-за чего такие скорости на Спартане-6 не получить?
-
Вот результаты измерения.
Компьютер - Intel I7 2.8 ГГц, системная плата GIGABYTE GA-P55-UD6
Модуль AMBPEX5 установлен через переходник x1
Вывод данных ( из компьютера в устройство )
1. системная память (непрерывная) 128 МБайт - 201 Мбайт/с
2. пользовательская память (разрывная) 128 Мбайт - 201 Мбайт/с
Модуль AMBPEX1 - используется контроллер PEX8311
Вывод данных ( из компьютера в устройство )
1. системная память (непрерывная) 128 МБайт - 185 Мбайт/с
2. пользовательская память (разрывная) 128 Мбайт - 120 Мбайт/с
Для режима x1 скорости от компьютера практически не зависят. Хотя я это давно не проверял.
Огромное Вам спасибо.
Скажите, при выводе данных из компьютера в устройство в чём разница между понятиями "системная память (непрерывная)" и "пользовательская память (разрывная)"?
И почему на AMBPEX5 через переходник x1 скорости вывода в обоих этих случаях равны, а на PEX8311 сильно отличаются?
-
Для реализации x1 у нас используется PEX8311. Насколько я помню, на вывод удалось достичь 150 МБайт/с.
Этот показатель как-то зависил от матери?
Для x8 и чипсет P55 - 1050 МБайт/с. Если найду переходник, то измерю скорость Virtex 5 в режиме x1Заранее благодарю.
-
Правы оба.
FIFO => DMA => PCIExpress
2 кбайт FIFO вполне достаточно для согласования скорости.
Непонятно, в чём тогда прав Bad0512, который пишет, что ФИФО недостаточно и нужен буфер приличного размера?
Напоминаю, что мы говорим о потоках около 200МБайт/с.
-
PCI Express платы на основе Xilinx Virtex 5 выпускаем давно.
Какие реальные скорости получаете для передач "Память ПК->Буферная память на PCIe х 1 плате" ( System Memory Read ) в зависимости от чипсета матери?
-
Да, похоже можно-таки сделать soft-core x4 PCIe на Spartan-6:
Вот современная ссылка: http://www.xilinx.com/products/boards-and-...EV-LX150T-G.htm
Как это понимать - PCIe x 4 soft macro?
И разъём действительно PCIe x 4

-
У меня такая проблема: устройство на базе Endpoint Block Plus
v1.9 не на всех PC работает в режиме х8. Перепробовал кучу машин с различными мостами. В некоторых материнках, устройство сразу работает на х8, в других при первом включении на х1, а после перезагрузки(помогает кнопка ресет), переходит на х8, в третьих только на х1, и никакая перезагрузка не помогает, не смотря на то, что на материнке написано х8 и в биосе тоже все нормально. Неужели Endpoint Block Plus такой привередливый к типу чипсетов?????
Тема привередливости к чипсетам меня тоже интересует.
demon_rt,что Вам удалось за год на эту тему выяснить?
-
Присоединяюсь к вопросу Сергея.
Сергей, если за год ты уже нашёл ответ, то расскажи.
-
Пару слов вдогонку... При потоках 200мБс Вам не обойтись без промежуточной памяти приличного размера.
У 6 спартана кстати есть аппаратный контроллер памяти. Корку ДМА готовую конечно можно найти, но всё
равно в ней Вам как минимум разобраться придётся - все эти корки очень заточены и оптимизированы под
определённые приложения.
неправда, спокойно 200 мбайт сек через 2 кбайта фифошки (скорость записи в память pc), обратно мне больше 170 не удалось получить.Диаметрально противоположные мнения
Кто прав и почему ? Или оба правы, но каждый по-своему?
-
у altera-ы приведен список скоростей для разных материнок.
AN431
Никакого списка скоростей для материнок в AN431 я не нашёл. На какой странице?
И судя по документации на чипсет X58 payload у него не менее 128А вот по поводу payload для X58 Xilinx в XAPP1052 считает иначе:
The x58 supports up to 256 byte maximum payload size (MPS), and the x38 supports up to 128 byte MPS.
Хотя конечно "не менее 128" и "up to 256 byte" в итоге могут означать одно и тоже )
-
Сергей, напишите, пожалуйста, конфигурацию оборудования, на котором проводили тестирование. Я надавно проводил аналогичные тесты для своего проекта, и получил на двух разных стендах скорости чт/зп 460/300 МБ/с и 820/375 МБ/с. Не правда ли, поразительная разница? Для 1-lane получал скорости в зависимости от стенда и ОС от 140/120 до 180/160.
Может, стоит над сим задуматься и попробовать другой ПК?
Не могли бы Вы более конкретно рассказать о том, на матерях с какими чипсетами и на каких ОС получаются самые высокие , и на каких - самые низкие результаты и с чем это связано ?
-
Благодарю, только где выставляется в системе PAYLOAD ? В Bios-е нет :(
Нигде,это свойство заложенное изготовителем материнской платы.
Интересует статистика по матерям.
На матерях с каким чипсетом MPS ( Maximum Payload Size ) 64 байта или даже 32 байта и ниже?
Ну и соответственно, на матерях с каким чипсетом MPS ( Maximum Payload Size ) 256 байт и выше?
-
Теоретически, можно запрограммировать DMA контроллер который есть в чипсете хоста провернуть чтение из хоста и запись в девайс, бОльшими блоками. Но это дает сильную аппаратную привязку к типу хоста + сложность в написании драйвера.
Поясните, что значит - сильную аппаратную привязку к типу хоста? Какие типы хостов имеются в виду?
-
Без ДДР - невозможно. Внутренней памяти мало, в реальной жизни необходимо буферировать минмум 1 секунду потока
для того, чтобы всё работало без дропов.
Буферировать минмум 1 секунду потока - это Вы имели в виду для какого видео, SD или 3G-HD?
Буфер на секунду для капчура+ буфер на секунду для плейбека = транспортная задержка между вх. и вых. видео получется 2 секунды.
Не многовато ли?
6. В дальнейшем перетащил дизайн под архиетктуру Спартана6, но это уже отдельная история.Вы имеете в виду, что на Спартане-6 всё проще получается и без GN4124?
Хотя , конечно не надо забывать, что в Спартане-6 только PCIe x1, а в GN4124 - PCIe x4 и поэтому 3G-HD через Спартан уже не пролезет.
-
Bad0512, а Вы не пробовали вообще без DDR обойтись для капчура и плейбека?
А что полезного вообще есть в pinto если Вы столько оттуда повыбрасывали?
Какие впечатления от самой GN4124, так ли всё работает как в доках описано, нет ли каких явных багов?
-
1. Их машинка для работы с памятью была заточена на работу с фифошками, то есть адрес "протянуть" на память было невероятно сложно.
В моём приложении (туча разных буферов для видео и аудио) адрес был необходим как воздух, пришлось вникнуть и всё переписать.
Добавил механизм так называемых "локальных дескрипторов", то есть небольшая табличка для каждого ДМА движка (на запись и на чтение), которая описывает начальный адрес ДМА и размер ДМА в страничках со стороны локальной памяти ДДР.
2. Крайне неэффективно использовалась память для SG таблиц внутри FPGA (3*32 bit на каждую SG страничку, переделал - у меня всего 32 бита на каждую страничку таблички, при этом всё пашет под 64 битными системами). Память BRAM в моём проекте была в большом дефиците (специфика многочисленных переходов из домена в домен и большое число фифошек).
3. Механизм перехода из 32bit * 200MHz в 64bit * 100MHz мне очень не понравился, исключил все DCMки и сделал всё на 32bit 200 МГц. После некоторой оптимизации по скорости всё разводится на ура, все констрейны выполняются.
4. Всю работу с видео выкинул, вставил свои куски (так было нужно для моей задачи).
5. Для улучшения производительности между памятью DDR и DMA движком вставил фифошки (они там в любом случае были необходимы, ибо клоки - разные). Возложил на этот кусок функции кэширования - сильно помогает поднять производительность системы в целом.
6. В дальнейшем перетащил дизайн под архиетктуру Спартана6, но это уже отдельная история.
7. Да, капчур с плейбеком в моём дизайне естественно живут независимо и одновременно. Нельзя сказать что они друг на друга не влияют, так как обращаются они в итоге к одной и той же ДДР памяти. Но если скорости записи и чтения далеки от предельных это влияние минимально.
Bad0512,благодарю за столь обстоятельный рассказ.
Скажите, а насколько проект pinto в исходном виде, если не вносить в него никакие изменения, решает свою задачу по риал-тайм капчуру и плейбеку для HD-video?
-
Попробуйте запустить Design Entry CIS с лицензией Allegro Design Entry CIS.
Uree, спасибо за помощь, я тоже к этой комбинации склонялся.
-
Вот в списке у Вас Orcad Capture CIS - его и используйте для схемы.
Внутри Orcad Capture CIS ещё много чего есть, посмотрите пожалуйста ( см. вложение с перенахлёстом ).
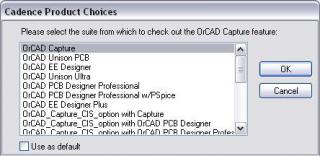
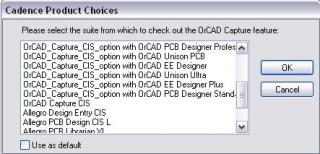
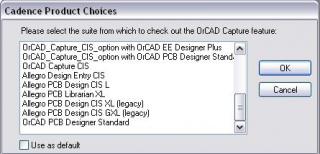
-
Схему редактировать в Entry/Capture CIS.
А Вы в какой версии работаете?
В 16.5 есть несколько программ ( см. вложение ) и внутри них несколько опций , в названии которых есть комбинация слов Entry / Capture / CIS / Design...
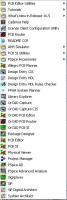
-
ЗЫ Хотя выбор программ - это самая маленькая проблема. Дальше будет интереснее...
Спасибо за быстрый ответ.
Да, действительно это только 1-й шаг.
Где можно посмотреть методику по тому, что мне нужно: внести некоторые изменения в файл схемы ( удалить лишнее и кое-что добавить ) и с учётом этих исправлений переразвести референсную плату, причём так, чтобы разводка большей её части ( та, схему которой я оставлю неизменной ) осталась такой же, как в референсном дизайне.




Ядро PCI Express Block Plus в Virtex 5
в ISA/PCI/PCI-X/PCI Express
Опубликовано · Пожаловаться
Не возникают ли провалы в скорости если начинают работать другие устройства, использующие DMA Bus Master, например если выводимые в плату данные будут поступать из гигабитной сети или с HDD?
Не пробовали ли чипсет x58, возможно там результаты будут повыше?
Как-то расстраивает 410 Мбайт/с на вывод на PCIE_x4_1...