


VladislavS
-
Постов
1 241 -
Зарегистрирован
-
Посещение
-
Победитель дней
9
Сообщения, опубликованные VladislavS
-
-
1 час назад, one_eight_seven сказал:
если я вам прямую ссылку прислал на ARM Compiler'овскую документацию
На заборе много что написано. Вот что об этом компилятор думает.
 1 час назад, one_eight_seven сказал:
1 час назад, one_eight_seven сказал:Но вы, судя по вашему ответу, отказываетесь делать так, как сказано в документации, и пишете, что это глупость.
Ну да, документацию не читал, код не писал. Просто попи...ть на форум зашёл :)
1 час назад, AlexandrY сказал:Давненько не припомню чтоб в FIFO писал программно. На тож DMA есть!
А если не завезли на USB DMA? Да и смысла никакого. Ждать передачи не надо. Копирования в FIDO от 1 до 16 штук максимум. Проще так передать, чем DMA заводить.
-
9 минут назад, AlexandrY сказал:
и меняю все мутные копирования на memcpy.
В общем случае это не прокатывает. Вот в этом моём примере после "стрёмного" чтения происходит запись в FIFO, которое надо 32-битным делать. Это как и с регистрами с помощью volatile решается. Как там внутри memcpy поступит...
-
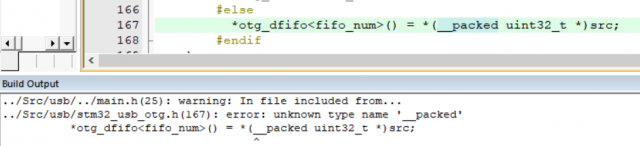
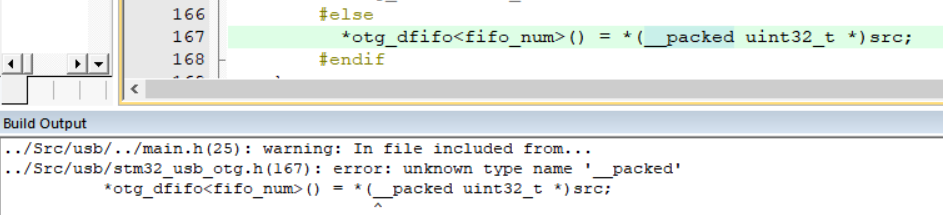
Вообще, __packed это специфика IAR. Вот что у него в документации написано.

Второе применение не про упаковку вовсе, а про ВЫРАВНИВАНИЕ данных. Ну просто неправильно говорить про упаковку применительно к простым типам.
Вот такого второго применения __attribute__((packed)) в стандарте языка не предусматривает.
-
3 часа назад, haker_fox сказал:
Как мне понять, что у меня адрес может быть невыровнен?
Ну если ты приведение типов делаешь от (uint8_t *) к (uint32_t *) это очевидно должно быть.
3 часа назад, haker_fox сказал:Я, признаюсь, __packed только для упаковки структур использую,
И правильно делаешь. Она для этого и существует. Только сейчас в стандарте языка для этого __attrubute__((packed)) есть. Это стардарт, а не расширение компилятора.
-
4 минуты назад, one_eight_seven сказал:
__packed нужна и слева от знака равно, и справа.
Ну это глупость. Операция чтения из памяти в правой части выражения никак не связана с тем куда это значение потом будет записано. Это может быть перегруженный оператор присваивания, который "format c:\ /q" делает в зависимости от принятого значения. Чтение в любом случае сначала в регистр процессора происходит. И __packed в этом месте больше неприменимо.
-
1 минуту назад, __inline__ сказал:
GCC ?
Да чтож у вас со зрением то? ARMCC v6.
2 минуты назад, __inline__ сказал:-mno-unaligned-access
Мне НУЖЕН невыровненный доступ. Я за него борюсь :)
Ещё раз для понимания. У меня нет проблем с этим кодом! Я знаю как его компилируют ARMCC v6, GCC и IAR на всех возможных ключах оптимизации. Давно сделано всё что надо, чтобы проблема не вылезла больше. А вот как сказать на С/C++ компилятору, что я хочу невыровненный 32-битный доступ...
12 минут назад, jcxz сказал:typedef u32 __attribute__((packed)) u32p8;
Ну это то же самое что и выше с using.
-
3 минуты назад, aaarrr сказал:
Нет, всё же правду говорят, что наглость - второе счастье
Ну же, сделайте последний шаг. Напишите что вот в это выражение добавить, чтобы компилятор использовал только LDR и никак не LDM?
*fifo = *(uint32_t *)src;
14 минут назад, jcxz сказал:Просто он забыл указать __packed.
Думаете это так просто сделать? Ну вот, пробую в дурку с компилятором сыграть
using packed_uint32_t = uint32_t __attribute__((packed)); *fifo = *(packed_uint32_t *)src;
Компилируется, но покрутив у виска опять LDM влепил.
-
5 минут назад, aaarrr сказал:
Я только играю бесплатно.
Ну, то есть, бла-бла? Конечно, проще обвинить человека в нежелании читать доки. Спасибо.
-
1 минуту назад, aaarrr сказал:
Хорошо, поиграем в Шерлоков
ARMCC v6 (он же clang). Ну и GCC c IAR заодно. Код должен всем собираться.
-
16 минут назад, one_eight_seven сказал:
Как конкретно это делается, я сказать не могу
Вестимо несколькими чтениями. Но это происходит прозрачно для кода. Если использовать правильные инструкции.
 18 минут назад, aaarrr сказал:
18 минут назад, aaarrr сказал:Так доку почитать, нет?
А носом в доку ткнуть, нет?
-
8 минут назад, one_eight_seven сказал:
Это зависит от шины, которую ядро использует для доступа к памяти.
Я говорю за конкретное ядро Cortex-M4, конкретный адрес в SRAM (0x2000'0001). Я точно знаю что так МОЖНО и хочу воспользоваться этим.
10 минут назад, jcxz сказал:Попробуйте добавить __packed (или её аналог)
Это IAR-овская приблуда. Я не знаю как её в других компиляторах, работающих по стандарту, в данную операцию вставить.
-
Ещё раз. Я осознанно иду на невыровненное чтение, воспользовавшись тем что Cortex-M4 это умеет делать. Вот так же я имею право сделать?
GPIOA->IDR = *(uint32_t*)0x2000'0001;
То что мне компилятор вставит тут LDM в мои планы не входило.
-
1 минуту назад, jcxz сказал:
во что это скомпилировалось.
В LDM и скомпилировалось. На O3 (или Os не помню).
-
2 минуты назад, jcxz сказал:
что адресуете 32-битное значение, которые он по умолчанию считает выровненными (в целях оптимизации)
С чего бы это? Кто так умолчал? 32-битное значение легко может быть частью упакованной структуры.
-
Адрес src на вход функции подаётся в общем случае невыровненный. По этому адресу читается 4 байта. Если бы это был Cortex-M0 какой-нибудь, то компилятор в несколько присестов как-нибудь собрал прочитал эти байты из памяти. Но тут он видит, что у него Cortex-M4 и можно с понтами сразу 32-битное чтение применить и выбирает неправильную инструкцию.
-
Чего это он кривой? СПЕЦИАЛЬНО произведено чтение 32-битного слова по невыровненному адресу. Cortex-M4 это позволяет делать. Почему компилятор от разработчиков ядра выбрал неподходящую для этого инструкцию?
*src + (*(src+1)<<8) + (*(src+2)<<16) + (*(src+3)<<24);
Вот такую операцию он тоже оптимизирует до одного 32-битного чтения, но использует уже правильную инструкцию. То есть, компилятор знает, что на этом ядре так можно. Но пользуется этим знанием как-то странно.
-
13 минут назад, jcxz сказал:
А на каком ядре HF "не может быть по определению"?
Да может, конечно, если уж к буквам придираться. Но ожидать, что компилятор от разработчиков ядра устроит HardFault у Cortex-M4 вот на таком коде при операции чтения из памяти...
void WriteFIFO(uint8_t *src) { uit32_t *fifo = CONST; *fifo = *(uint32_t *)src; }
-
1 минуту назад, one_eight_seven сказал:
Линт и статический анализ используете?
Это другое. Безупречный с точки зрения стандарта языка код может легко в железе "чудеса" творить. Никогда ты ими не отловишь HardFault по невыровненному доступу, особенно на ядре, в котором его не может быть по определению.
-
3 минуты назад, one_eight_seven сказал:
и он стал уметь ещё меньше
Это другой случай. Компилятор же не сделал молча нерабочий код?
-
3 минуты назад, jcxz сказал:
С вероятностью 99% это говорит о наличии багов в компилируемом ПО.
Согласен. Просто не хотел коллегу расстраивать. Мой опыт говорит, что из-под IAR "более рабочий" код обычно выходит, он больше прощает. Например, не оптимизирует доступ к памяти по указателю, если вдруг volatile забыть. Или принимает за constexpr адреса, что противоречит стандарту, но де факто удобно и работает.
Я в последнее время стал свои проекты разными компиляторами собирать. Вместе они больше проблем в коде находят :)
-
1 час назад, __inline__ сказал:
Ну и самое главное, - где вы брали IAR 8.5, когда на офсайте доступна только v. 8.4 ?
Как так? 8.50 17.02.2020 релизнут. А сейчас на оффсайте 8.50.4 раздают. http://netstorage.iar.com/SuppDB/Protected/PRODUPD/014675/EWARM-CD-8504-26143.exe
Проблема GCC в том, что его из "взрослого" компилятора "натягивают" на микроконтроллеры. И не до конца натягивают. Например, GCC не умеет RBIT делать на ARM. Очень не хватает мне человеческих листингов, чтобы С и ASM вместе был.
IAR же наоборот из компилятора для микроконтроллеров старается "большим" стать. С переменным успехом.
ARMCC v6 хорОш, но сыроват. Последний словленый мной его выкрутас - на максимальной оптимизации они умудрились HardFault по невыровненному доступу на ядре Cortex-M4 (оно поддерживает невыровненный доступ) устроить. Профи, ничего не скажешь :)
-
2 часа назад, GenaSPB сказал:
Гуглить про __libc_init_array
__lib_init_array достаточно тяжёлая. Если размер актуален, то можно её подменить. На Cortex-Mx я вот так делают. Думаю на Cortex-A буде что-то подобное.
Код из стартапа.
void SystemInit(); void __libc_init_array(); int main() __attribute__((noreturn)); // These magic symbols are provided by the linker. extern void *_estack; extern void *_sidata, *_sdata, *_edata; extern void *_sbss, *_ebss; extern void (*__preinit_array_start[]) (void) __attribute__((weak)); extern void (*__preinit_array_end[]) (void) __attribute__((weak)); extern void (*__init_array_start[]) (void) __attribute__((weak)); extern void (*__init_array_end[]) (void) __attribute__((weak)); extern void (*__fini_array_start[]) (void) __attribute__((weak)); extern void (*__fini_array_end[]) (void) __attribute__((weak)); // Iterate over all the preinit/init routines (mainly static constructors). inline void __attribute__((always_inline)) __run_init_array (void) { int count; int i; count = __preinit_array_end - __preinit_array_start; for (i = 0; i < count; i++) __preinit_array_start[i] (); count = __init_array_end - __init_array_start; for (i = 0; i < count; i++) __init_array_start[i] (); } void __attribute__((naked, noreturn)) Reset_Handler() { #ifdef __DEBUG_SRAM__ __set_MSP((uint32_t)&_estack); #endif SystemInit(); // User hardware initialization void **pSource, **pDest; for (pSource = &_sidata, pDest = &_sdata; pDest != &_edata; pSource++, pDest++) *pDest = *pSource; for (pDest = &_sbss; pDest != &_ebss; pDest++) *pDest = 0; //__libc_init_array(); // Use with libc start files instead __run_init_array(); __run_init_array(); // Use with the "-nostartfiles" linker option instead __libc_init_array(); (void)main(); }
-
51 минуту назад, MementoMori сказал:
но меню настроек не такое
Сидите дальше на 5-м компиляторе. Сколько он уже не развивается? Прямо некрофилия какая-то.
52 минуты назад, MementoMori сказал:У меня 5.29
Уже 5.30 есть, но это не важно.
-
8 часов назад, x893 сказал:
Не все кейловоды одинаковые.
Ой ли? А кто тогда на -О0 компилит? :)


Кто тестировал IAR ARM 8.50, отзовитесь
в IAR
Опубликовано · Пожаловаться
Угу, показал :)))). Вот оно, суперопределение!