


adnega
-
Постов
3 603 -
Зарегистрирован
-
Посещение
-
Победитель дней
3
Сообщения, опубликованные adnega
-
-
2 минуты назад, jcxz сказал:
Да уж... Видимо вы из тех, кто на каждую минимальную функцию (типа захвата фронта/спада) ставит по отдельному процессору.

В этом вы ошибаетесь сильно: у меня все разрабатываемые контроллеры нафаршированы максимально) Под задачу я выбираю МК из типовых (что уже серийно используем, чтоб не раздувать номенклатуру), затем свободные ресурсы задействую для добавления функционала в перспективе.
Я максимально использую аппаратные возможности МК. "Хоть поллингом флагов" это не призыв к действию, а иллюстрация простоты задачи.
Для захвата ШИМ я использую два варианта:
1) с обработкой в реальном времени каждого импульса в прерывании;
2) с постобработкой порции или всего пакета импульсов в связке TIM+DMA.
ТС не поставил никакой практической задачи, поэтому конкретно ответить сложно, но это точно не "использовать нормальный МК". Когда мы подменяем принцип выбора подходящего под задачу камня, нытьем танцора, которому в "обычных" МК все жмет. Не хочу переходить на личности, но мимо заявления о существовании неких "нормальных" МК пройти не смог.
Итого, ТСу нужно зафиксировать задачу. Если это анти-ШИМ чего-то нешустрого, то советую освоить TIM+ISR. Для более шустрого, но не требовательного с реалтайму - TIM+DMA. Это закроет 99% типовых потребностей. Будут вопросы - поможем.
Если задачу экстремалить, т.е. повышать частоту до предела, то, разумеется, в этот предел упрешься, а там уже принципиально иные способы решения могут возникнуть. Вместо этого рекомендую освоить TIM_master+TIM_slave - добавит в копилку решений еще 0.99%
-
 1
1
-
-
>Может не будем валить с больной головы на здоровую? Речь шла о фиксации длительности одиночных импульсов.
С одиночными импульсами вообще проблем никаких нет - хоть поллингом флагов CCR таймера.
Речь шла о захвате в пределе - в терминах ТС "с минимальной задержкой". Я понял, что речь идет о задержке между соседними импульсами.
>отсутствие информации, что такая потеря произошла.
И что делать с информацией, что потеря произошла? Какой практический смысл?
> была короткая иголка (в несколько тактов)
В таймере перед блоком захвата есть аппаратный фильтр - для борьбы с такими иголками)
> Поэтому при наличии всякого рода дребезгов, анализ посредством DMA на STM32 очень сложен.
Я борьбу с дребезгом поручаю аппаратному фильтру. Иначе "дребезги" разобьют в дребезги любую систему, борющуюся с ними программно.
Разве нет?))
Системы, типа, "я зафиксировала дребезг на входе поэтому работать дальше не буду" я рассматривать не готов)
> Тогда расскажите - как будете действовать в случае...
Вообще проблем не вижу. Недавно сдал систему захвата 12 каналов датчиков детонации с привязкой к углу возникновения с точностью 0.025 градуса. Помехи от частотника прут и по каналам захвата и от энкодера)) Есть и аппаратная борьба на входе МК (причем лайтовая, чтоб импульс не сдвинуть и не наврать с углом), и программная низкоуровневая, и программная высокоуровневая. Забавно, вообще все построил на EXTI-прерываниях. А точность получилась - мама не горюй - видно как вал скручивается в зависимости от нагрузки и оборотов)) Кста, есть программная компенсация задержки распространения сигнала во входных аналоговых цепях.
ШИМ-декодировать приходилось в драйвере приемника от ИК-пультов. Или в вызывной панели VIZIT. Или в работе с 1-wire устройствами. Вообще без проблем.
Итого: если не придумывать себе проблему, чтоб потом ее героически решить, то и проблемы не будет.
> ЗЫ: Или всё-таки в таймерах STM32 есть какой-то способ зарегистрировать факт потери события? Кто знает?
Я же сказал: задача фиксировать факт потери события в большинстве случаев не стоит.
Кто знает систему, где обработка потерь импульсов играет рояля?
-
Могут предложить такую задачку (если ТС не против):
1) Есть адресные светодиодные ленты (типа WS2811) - 4 шт.
2) Есть источник данных для этой светодиодной ленты.
3) Нужно сделать контроллер с одним входом (WS2811) и 4 выходами (WS2811).
4) На каждом выходе нужно индивидуально задать сколько светодиодов будет пропущено из потока.
Проще: нужно входные импульсы пропустить на выход, но первые 24*Ni (i от 1 до 4, Ni > 0) заменить на лог "0".
Будем считать, что импульсы со скважностью 2 и частотой 800кГц.
Я сделал такое на STM32F042 (аналог F030, на F030 тоже заработает). Контроллер позволяет данные для одной длинной светодиодной ленты поделить на сегменты с индивидуальным смещением - резко удобнее становится подключение.
Кста, одноканальный вариант вообще на Тини13 делал)
-
36 минут назад, jcxz сказал:
Кто? Очевидно программа на этом МК. И в чём именно проблема обработать?
Чушь. FIFO не может быть "на один элемент". По определению.
И как например хотя бы узнать, что произошло переполнение (была потеря события) с одним CCR? Не говоря уж о полноценной регистрации...
Идут импульсы/паузы в тактах: 1/1-1/2-1/1-1/1 и т.д. непрерывно. Сколько тактов стоит CPU вытащить эти данные из FIFO (со всеми флагами переполнения и т.п.)? Очевидно же, CPU не сможет обработать такой непрерывный поток. Очевидно же, DMA тоже может обеспечить поток, который CPU не сможет обработать.
Чушь - ок.
Отсутствие потери событий гарантируется архитектурой системы. Кто-то проектирует систему, где допускается потеря событий - я так не поступаю и другим не советую.
Предметнее проще: приведите пример задачи, где без "нормального" МК не обойтись. Я довольно сильно использую таймеры - пока все задачки решаются STM-совместимой таймерной периферий большинства популярных МК.
-
12 часов назад, ozforester сказал:
Как лучше поступить? Или я просто чего-то недочитал, и выдумал проблему на ровном месте?
Обрисуйте конкретную задачу - будет проще предложить решение.
Регистры CCR - это и есть FIFO на один элемент, далее - DMA (с характерным темпом не чаще 12 тактов CPU).
Не знаю зачем "нормальным" МК какие-то FIFO: ну наловишь импульсы "хоть в 1 такт" - дальше что? кто их будет способен обработать?
-
2 часа назад, Zlumd сказал:
Ремаппинг USART1 на PB6, PB7 не работает
А мне приходится их оба (USART1 и I2C1) включать, чтобы USART1 работал на PB6, PB7.
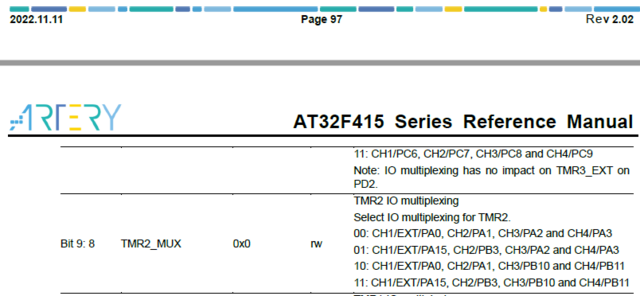
Ремаппинг TMR2 на PB8, PB9 не работает при IOMUX->remap_bit.tmr2_mux = 3
При IOMUX->remap_bit.tmr2_mux = 2 ремаппинг TMR2 на PB8, PB9 нормально работает, но почему не работает при 3 ?
Ремаппинг TMR9 на PB14, PB15 никакими ухищрениями не удалось заставить работать.
А разве TMR2 должен ремапиться на PB8/9 ?
"Non-timer peripherals has priority over timer peripherals". Нужно проверить, что на этих пинах нет никакой нетаймерной периферии.
Кста, в чем отличия _MUX и _GMUX регистров?
-
Надеюсь, про защитный резистор 56кОм никто не забыл


-
 1
1
-
-
1 час назад, dimka76 сказал:
Значит нужен свой startup
li t0, 0x1f csrw 0xbc0, t0 /* Enable nested and hardware stack */ li t0, 0x0b csrw 0x804, t0 /* Enable floating point and interrupt =0x6088 / =0x7888 */ li t0, 0x7888 csrs mstatus, t0 la t0, _vector_base ori t0, t0, 3 csrw mtvec, t0 /* la t0, main csrw mepc, t0 mret */ j mainМожно поправить исходный примерно так.
-
В своем загрузчике startup от производителя не заработает, т.к. там делается переход в U-режим. И уже попытка записи csr в startup приложения вызовет сбой.
-
Чему равен Page_Address ?
#define FLASH_BANK1_END_ADDRESS ((uint32_t)0x807FFFF)
- не много для 16кБ флешки?
-
2000014a: jalr t0,160(zero) # 0x0 <_start>
А это что?
Что лежит по адресу 0xA0 ?
-
Почитал внимательно .
ТС вызывает функции из функций ))
Да, функции находятся в ОЗУ, но они могут использовать флешовые __riscv_save_0/__riscv_restore_0
Выглядит так:
в начале функции 200000e0 <test_ram>: { 200000e0: 0c0002e7 jalr t0,192(zero) // 192=0xC0: <__riscv_save_0> 200000e4: 03000793 li a5,48 while(!(USART1->STATR & (1 << USART_STATR_TC))); ... и в конце 20000138: dfe5 beqz a5,20000130 <test_ram+0x50> test_foo(); 2000013a: 37b9 jal 20000088 <test_foo> - вызов вложенной ram-функции } 2000013c: 0ca00067 jr 202(zero) // 202=0xCA: <__riscv_restore_0> 000000c0 <__riscv_save_0>: c0: 1151 addi sp,sp,-12 c2: c026 sw s1,0(sp) c4: c222 sw s0,4(sp) c6: c406 sw ra,8(sp) c8: 8282 jr t0 000000ca <__riscv_restore_0>: ca: 4482 lw s1,0(sp) cc: 4412 lw s0,4(sp) ce: 40a2 lw ra,8(sp) d0: 0131 addi sp,sp,12 d2: 8082 ret
-
посмотрел v003 сильно отличается: CSR 0xBC0 - отсутствует; U режима нет совсем (mstatus.MPP=0b11, т.е. всегда в режиме M).
-
Не ваш случай, но на старших камушках еще и с частотой непонятки: ядро может 144МГц, а флеш то ли 120, то ли 60 МГц максимум. Типа нужно замедлятся при работе с флешью. Причем, read тоже за работу считается - не понятно(
-
Прямо сейчас на ch32v307 подобным занимаюсь. Код слинкован с адреса 0x0000_0000, но шить нужно по адресам флешки 0x0800_0000, иначе FLASH_STATR_EOP не взводится.
Еще добавлю загадочный CSR 0xBC0. Туда пишется нечто, отвечающее за выборку. Может его как-то нужно сбрасывать, чтоб на флешку не влиял?
И стартап от WCH любит из M переключить в U-режим исполнения. Привилегий меньше, и при работе с CSR можно улететь в HF.
Кста, установка RDP блокирует от записи первые 4кБ.
-
Примерно в то время использовал КР1878ВЕ1, но мало.
-
А если по делу, то MCP я бы в trt.ru поспрашивал.
-
В 01.12.2023 в 15:46, jcxz сказал:
когда наступите на грабли в прошивке, а обновить удалённо возможности не будет.
+1 Я везде закладываю возможность обновления прошивки. И после этого позволяю себе не боятся граблей в прошивке)
-
 1
1
-
-
Сам пользуюсь расширителями на МК - периферийными контроллерами. Обновление прошивки нужно, но с каких пор это проблема?
-
Придется скрещивать. Готовой реализации Host для Миландра не нашел - нужно будет ее делать. А реализацию MSD-класса можно взять/подсмотреть из чужих исходников.
Глянул, по-моему, Host в Миландре больше похож (но не есть одно и то же) на CH32V203, а не на STM32.
-
Ему внешнее питание от target`а нужно? Может, в эту сторону копнуть.
-
Таки подключил модуль к МК по USB-FS. Удалось выжать порядка 0.5 Мбит/сек при использовании USB-CDC и реализации TCP-IP средствами модуля.
Это сильно меньше предела полосы пропускания USB-FS (10 Мбит/с) и не дотягивается до желаемых 2-5 Мбит/с, которые дает модуль при подключении к ПК в режиме сетевой карты.
Есть ли смысл выжимать скорость через интерфейс AT-команд? Типа, отказаться от встроенного TCP-IP и обмениваться на более низком уровне?
Или напрячься и сделать поддержку режима сетевой карты? Дык, в ней те же 10 Мбит/сек максимум, и уровень сетевых пакетов (насколько я понимаю)...
Вообще, насколько я рискую, делая поддержку модуля без официальной документации? И есть ли она в открытом/закрытом доступе? Драйвера под Linux и Windows есть, а исходники есть?
-
Попробуйте пошагать по шагам в ассемблерном виде. Или просто глянуть листинг. Скорее всего, переменная лежит в регистре, и сейчас этот регистр занят чем-то другим.
У вас что-то не работает при этом?
-
Еще как вариант выдать STALL. Затем хост запросит REQUEST SENSE (03h), на который можно в ответе в поле Sense Key вернуть код 2h = Not Ready.
Хотя, нужно быть аккуратным т.к. "Operator intervention may be required to correct this condition".


Вопрос по захвату таймера stm32f030
в STM
Опубликовано · Пожаловаться
Это очень хороший результат.
Я бы разделил понятия: "точность-погрешность-и т.п." Тут все ок, без предфильтров будет 1 такт таймера.
И "пропуски-дребезг-загнулись". Нужно до ядра доводить только ту информацию, которая нужна для принятия решений. Т.е. если можно аппаратно выкинуть часть импульсов - это нужно делать.
У вас настроен DMA на два переноса - в будущем можете просто увеличить размер буфера или вообще перейти на кольцо.
Если передавать ядру всю информацию об импульсах, то оно загнется раньше TIM/DMA/ISR.
> Применить смогу, например, при измерении частоты
Частоту можно двумя способами измерять:
1) измерив период между соседними импульсами.
2) измерив количество импульсов за единицу времени.
В зависимости от требований выбирается тот или иной способ.
> Анти-шим это обратное извелечение информации из ШИМ, декодирование что-ли?
Да. Очень во многих областях/протоколах информация передается длительностью импульса/паузы.
> Правильные МК посмотрел. Купить в розницу незадорого, и собрать минимальный набор для отладки не получится.
Не знаю что в них правильного? В наличии нет, ценник конский, решение получится не универсальное, т.к. будет привязано к конкретному МК.
Сразу поставить ПЛИС, если программист не способен решить задачу без красивостей/правильностей в железе.
> Для того, чтобы сделать вывод о возможном пропуске
Вариантов много. Я часто один из свободных каналов захвата/сравнения использую для аппаратных таймаутов.
> Для меня интересным было время, которое тратится на дма, на вход в прерывание, на синхронизацию, время сохранности результата в регистре.
Это правильные интересы. У вас ядро популярное. Советую книги Джозефа Ю - зачитаться.