


kan35
-
Постов
649 -
Зарегистрирован
-
Посещение
-
Победитель дней
1
Весь контент kan35
-
Микрон проводит публичный технический практикум на МК Амур. Участие - бесплатное. 2 города - Новосибирск и Екатеринбург. https://www.mcu.mikron.ru/technical-training
.thumb.png.2e43c376c71924ee24c8ccdb3db8e581.png)
-
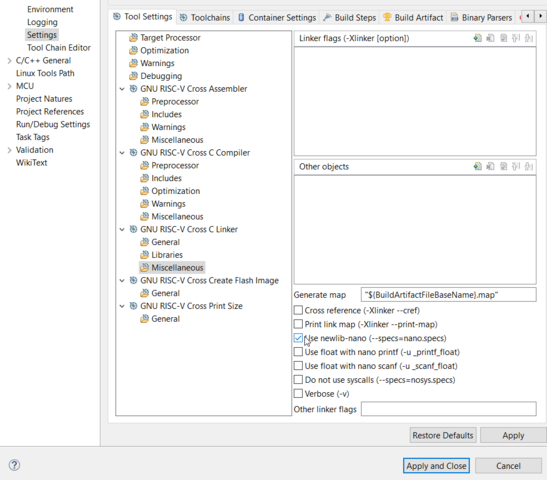
Чтобы вручную не переключать --specs=nano.specs, полнота выбирается в свойствах линкера. Там же включается поддержка плавающей точки.
-
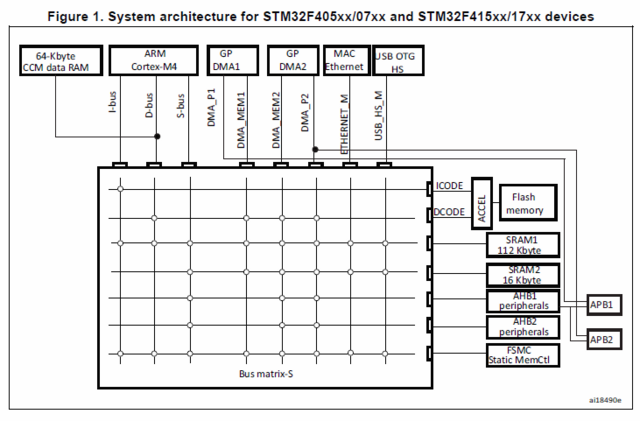
Не совсем так, матрица шин, хоть и работает на частоте ядра, но она делится между многими мастерами, например DMA, у которого есть пачковый burst доступ, плюс время на захват шины и будет процессор M7 сидеть без данных или без кода многие десятки циклов. Только не говорите "а можно не использовать DMA" 🙂 , но кстати за счет деления SRAM банки в STM32 - там можно распределить нагрузку на матрицу шин, но все же . В общем и целом у CM0-CM4 всё те же слабые точки, что и у других архитектур того же уровня интеграции. Кстати, TCM на некоторых контроллерах может быть использована для кода тоже. Конечно же лучше, когда кэш находится и в самом процессоре. Ну и опять мы внезапно пришли к сравнению SCR1 с CM7... Все таки, более честно будет сравнивать с СM0 или хотя бы с СM3, так как у SCR1 есть аппаратное умножение, но точно не с CM7.
-
Цена на Амур будет разумеется выше, чем на wch сравнимого уровня. флэш технологии в России нет, поэтому память только внешняя, или sip В нашем случае, даже если бы была флэш, то наделать зоопарк контроллеров от 8кб до 4мб не представляется реалистичным в короткие сроки, поэтому внешняя флэш - решение даже скорее логичное 8 выводная микросхема за 50центов (8мб) не сильно ударит по карману, тем более сам контроллер дорогой настолько, что его обвязка это прямо скажем - статистическая погрешность по затратам И я уверен, что контроллер потенциально зайдет много куда, но меня две вещи беспокоят - получится ли снизить цену хотя бы рублей до 200 и будет ли стабильным качество… ну и еще вопрос конечно - сможет ли Микрон нашлепать миллионы Амуров в год…
.png.fb656f8735e7fc8a4d26d80b2fe832b7.png)



