repstosw
-
Постов
2 650 -
Зарегистрирован
-
Победитель дней
2
Весь контент repstosw
-
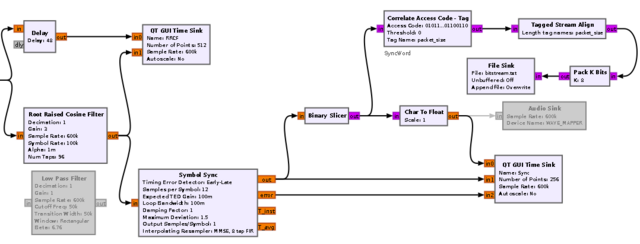
OK, ещё раз перечитаю посты в теме. От 10 до 13 отсчётов на один информационный бит Да. Заметил. При больших значениях синхронизатор уходит в расколбас и комп повисает намертво, симуляция останавливается. Удалось заставить синхронизатор правильно работать. А также сдетектил синхро-слово и сформировал пакеты.
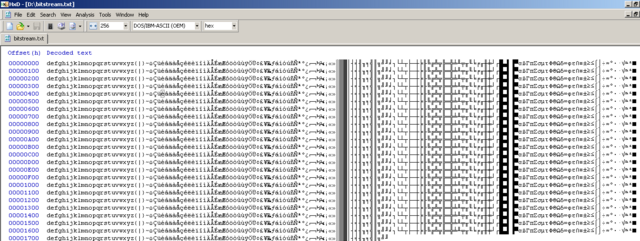
-
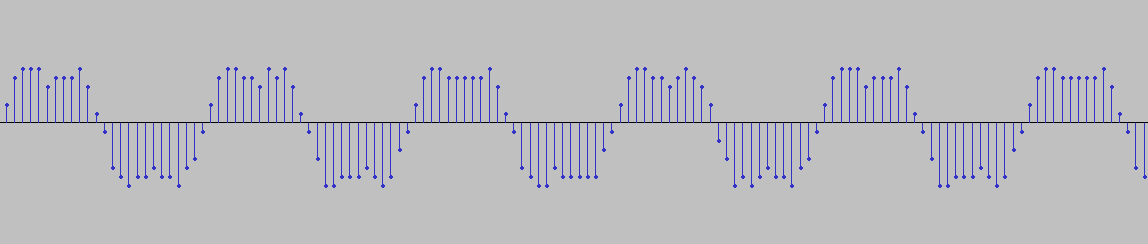
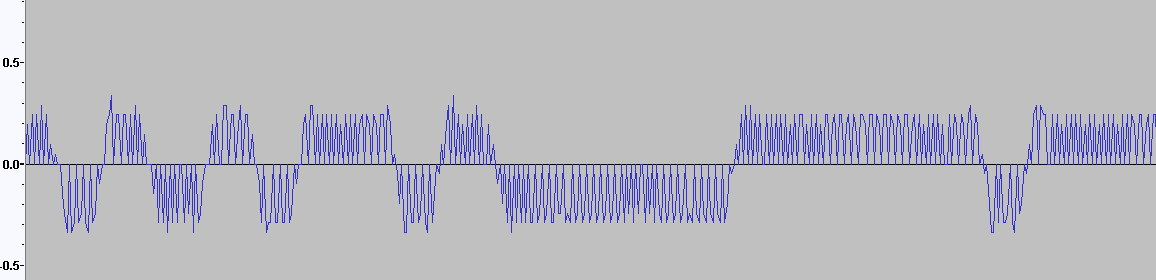
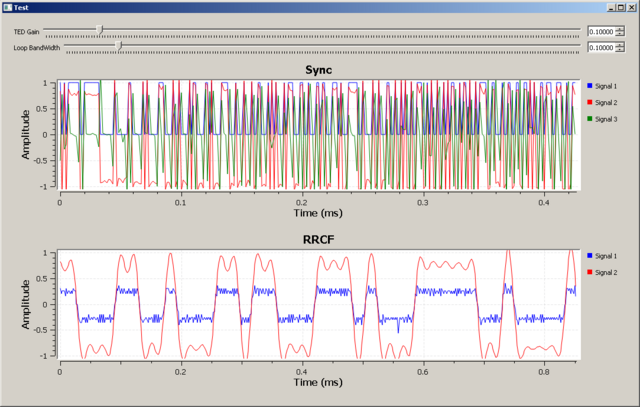
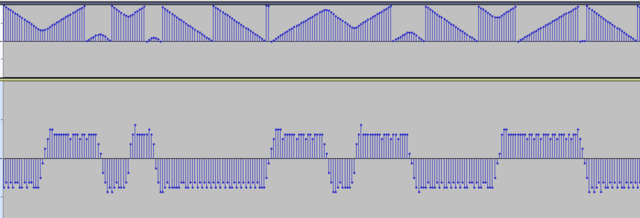
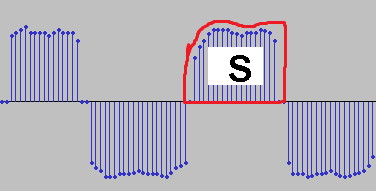
Попробовал фильтр корня приподнятого косинуса. После определённых настроек теперь число горбов с выхода этого фильтра показывает число смежных бит в сигнале. Красный - выход с фильтра косинуса Синий - исходные отсчёты, полученные как разность фаз (снятые с Si4463) Зелёный - слайсер Надеюсь, оно теперь будет являться хорошей пищей для Symbol Sync.
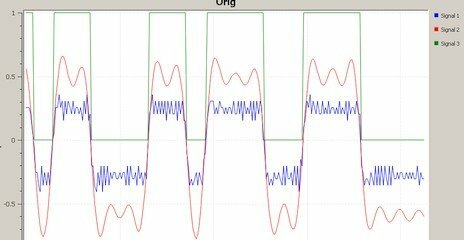
-
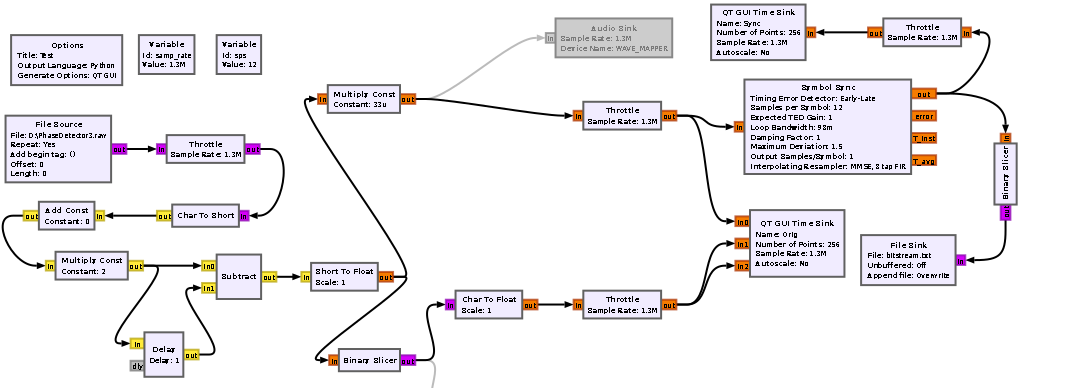
Поигрался в GNU Radio. Завёл свои отсчёты фазы в программу, привёл к нужному типу данных и нашёл мгновенную частоту как разность фаз. На этом лыжи дальше не едут: не получается восстановить частоту символов с помощью штатного блока Symbol Sync. У меня на каждый бит приходится 10...12 отсчётов, это и задаю в программе, но восстановленный поток битов вообще и близко не похож на исходный: Binary Slicer и то правильно работает, в отличие от Symbol Sync. Пробовал записать выходной поток бит после слайсера в файл: в момент преамбулы, запись бит "1" и "0" содержит по 10..12 отсчётов - по понятным причинам. Собственно 2 вопроса: 1) А точно Symbol Sync может работать именно на моих отсчётах сигнала? Может требуется какая-та предварительная обработка сигнала? 2) Возможно ли выровнять число отсчётов на бит уже после слайсера? Мне кажется, так даже будет логичнее - выровнять длительность каждого бита.
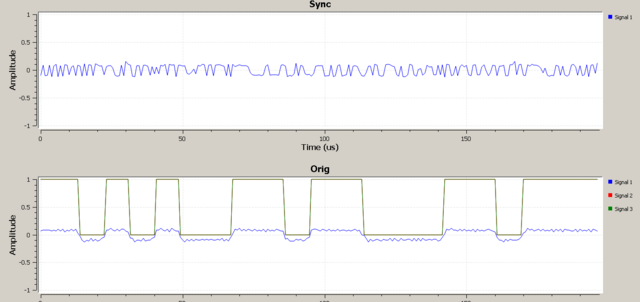
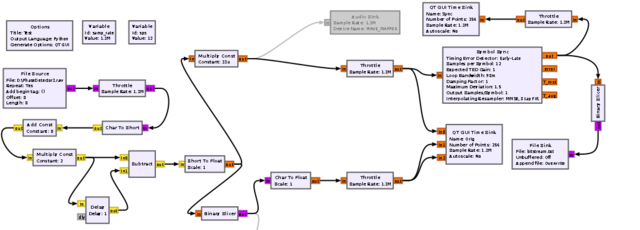
-
Удалил повторяющиеся отсчёты из raw-файла. Теперь соседние отсчёты фазы различны, и мгновенная частота не возвращается к нулю несколько раз. Очевидно, для скорости 50 кбит/с было пересемплирование. И теперь на 1 бит приходится 12-13 отсчётов всегда: Насколько высок потенциал для нахождения мягких решений?
-
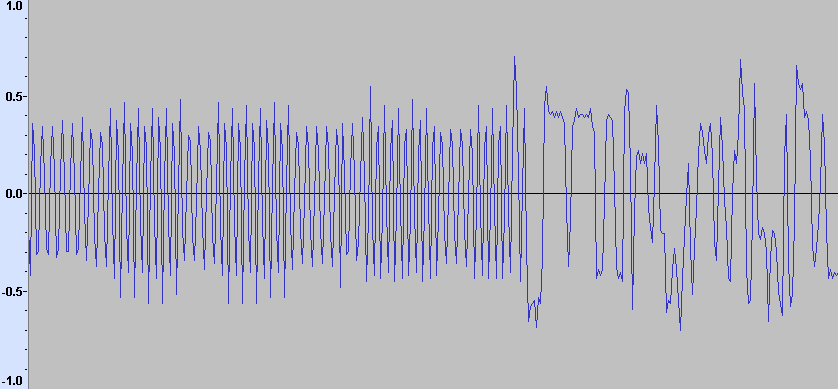
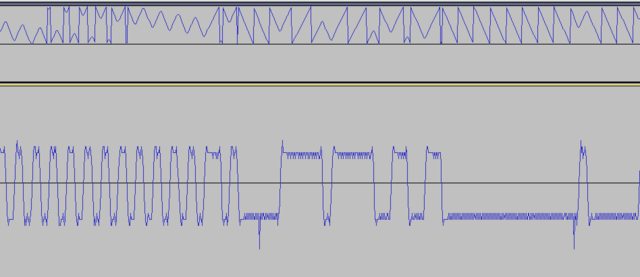
Да. Возвраты к нулю происходят от того что иногда соседние отсчёты фазы одинаковы (на скорости 50 кбит/с): Пофиксил отсчёты: +0+, -0-, +00+, -00-. Значения в нулях - нашёл интерполяцией. Вот так вышло (рисунок внизу): Для +0+ и -0-: //Step 1: Kill -0- for(u32 t=0;t<SIZE;t++)if((s[t]<0)&&(s[t-1]==0)&&(s[t-2]<0)) { y[t-1]=(s[t]+s[t-2])/2; //-2147483648.0/2; } for(u32 t=0;t<SIZE;t++)if((s[t]>0)&&(s[t-1]==0)&&(s[t-2]>0)) { y[t-1]=(s[t]+s[t-2])/2; //2147483647.0/2; } Для +00+ и -00-: //Step 2: Kill -00- for(u32 t=0;t<SIZE;t++)if((s[t]<0)&&(s[t-1]==0)&&(s[t-2]==0)&&(s[t-3]<0)) { float k=(s[t]-s[t-3])/3; y[t-2]=s[t-3]+k*1; y[t-1]=s[t-3]+k*2; } for(u32 t=0;t<SIZE;t++)if((s[t]>0)&&(s[t-1]==0)&&(s[t-2]==0)&&(s[t-3]>0)) { float k=(s[t]-s[t-3])/3; y[t-2]=s[t-3]+k*1; y[t-1]=s[t-3]+k*2; } Каким фильтром это можно сделать? ФНЧ боюсь срежет скаты, будет плохо. А если ноль между минусами превратить в минимум, а ноль между плюсами - в максимум, то получается прямо закраски битов данных дискретно. В логарифмической шкале ещё лучше: Мусор слева: Уже можно детектор преамбулы писать! :))) Кстати, что есть мягкое решение для одного бита? Нормированная площадь отсчётов на 1 бит?
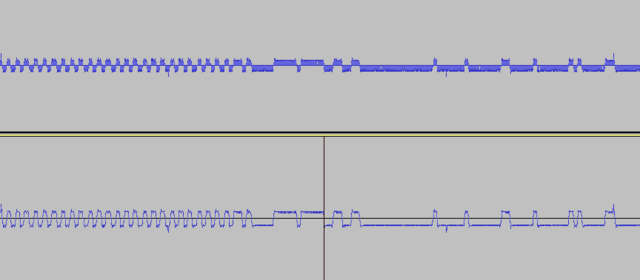
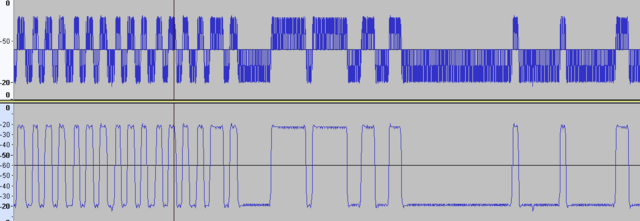
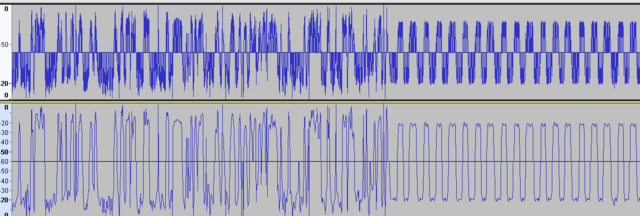
-
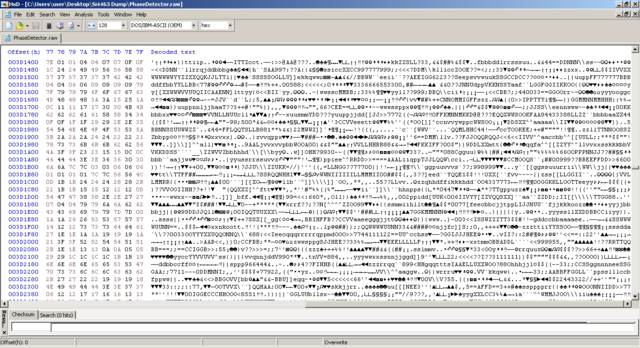
Прочитайте название темы. Причём тут замирания? Нужно получить битовый поток из сигнала модулятора. Про замирания - в других темах. Пока мне нужно оценить, насколько полезно может быть применение отсчётов мгновенной фазы для моих целей. Мои цели - отказаться от встроенного модема Si4463 и научиться находить битовый поток с отсчётов фазы демодулятора. Задача как я понял, не тривиальная. При этом мне нужны не просто биты в виде 0 и 1, а результат в виде мягких решений: [0.0...1.0], для того, чтобы загнать это на LDPC или Турбо-код. Хочу поиграться с мягким выходом демодулятора и оценить насколько FEC на мягких решениях более эффективна, чем FEC на жёстких решениях, которая уже работает. Тоесть, если разбить на под-этапы: 1) Получение сигнала мгновенной частоты с отсчётов фаз 2) Обработка сигнала (фильтрация, клиппинг, интерполяция,...) 3) Обнаружение преамбулы, нахождение тактовой частоты потока бит (сколько отсчётов на бит - среднее, и плюс-минус) 4) Нахождение синхрослова 5) Получение мягких решений для каждого бита, коррекция тактовой частоты битового потока (на базе алгоритмов корелляции, предсказания, ...) Нужна конкретика, а не общие слова... Тот же эквалайзер Витерби. Я ничего по нему не нашёл, кроме как хвалебные оды о том, какой он хорош. А где микросхема этого эквалайзера? А программная реализация? Или может мне сразу выломать кусок с сотовой БС и использовать готовую плату? К тому же, ЕМНИП эквалайзер Витерби борется с частотно-селективными замираниями. А у меня плоские замирания. Так что нужен он мне или нет - ещё большой вопрос. И MIMO - это тоже мимо для моих целей. Ставить 4 антенны на передачу (привет, матрица Аламоути!) или на приём - как-то не хочется. У трубки телефона - 1 сотовая антенна. И отсылка к книгам Скляра - это тоже ни о чём. Нужен - номер раздела, параграф, название. Конкретика. Какой фильтр посмотреть, как подчистить шумы, как получить мгновенную частоту битовых отсчётов и тому подобное. Формализую задачу. raw-файл отсчётов фазы (не обработан - прямой забор с демодулятора): https://dropmefiles.com/aNLMd Дано: raw-файл с отсчётами фазы, снятыми с демодулятора Si4463. Каждый отсчёт хранится в байте. Каждый отсчёт 7-битный знаковый: -64...+63. Причём знаковый бит - 6-й, а не 7-й (7-й бит пустой и всегда равен 0) В файле есть участки с принятым пакетом, который содержит: преамбулу 64 байта, синхрослово 32 байта (значение 0x5A0FBE66 ) и 6080 байт PayLoad (байты от 0 до 255, по возрастанию, повторяются). Параметры модема: модуляция 2FSK, скорость 50 кбит/c, девиация частоты +/-25 кГц, полоса пропускания приемника: 150 кГц. Надо: получить буфер бит данных (6080*8) мягких решений в диапазоне от 0.0 до 1.0. Допускается использовать мгновенные отсчёты и окна фиксированного размера (для оконных функций, фреймов). Тоесть - обработка данных в оффлайне. на 50 кбит/c обработанные отсчёты фазы (мгновенная частота) смотрятся веселее: снизу - отсчёты фазы:

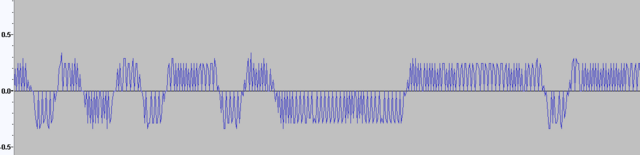
-
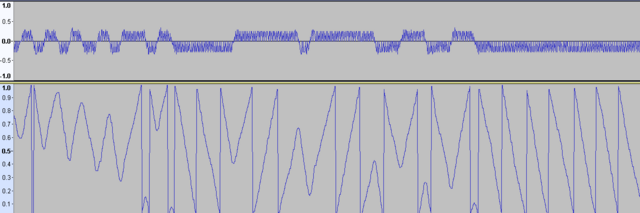
Какие следующие шаги должны быть? Нужно засинхронизироваться и начать по выборкам определять биты. Сделал полифазный фильтр, работающий в сторону апсемплинга. Код брал на гитхабе. Вышла лажа: отсчёты делает некорректно. Попробовал ресемплинг в Audacity - довольно неплохо 4:1. Как теперь найти интервал взятия отсчётов и нужна ли энергия битов? Пробовал вручную найти интервал выборки - получается уход постоянно:
-
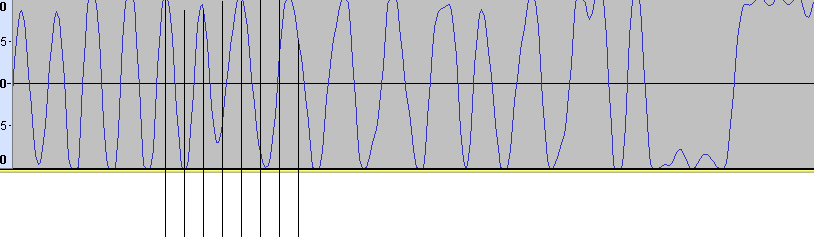
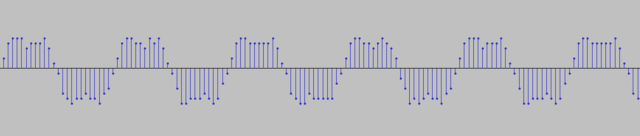
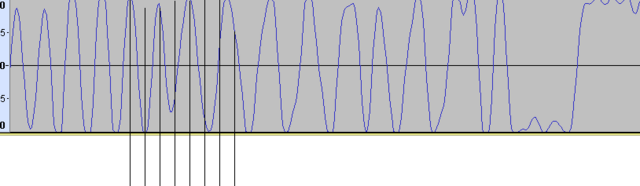
Сделал замеры. На битовой скорости 625 кБит/c получается 2,19 отсчётов. Грубо - 2 отсчёта на символ. Ни о каких мягких решениях нельзя говорить при таком битрейте. Но для скоростей десятки килобит в секунду сгодится. Всё из-за ограниченной пропускной способности SPI: максимально работает на половине тактовой частоты кварца: 37.5/2 = 18.75 МГц. Дальше только усекать разрядность выборок и толкать в байт. ЕМНИП для мягких решений достаточно трёх бит, остальное лишнее. Попробовал ещё включить логарифмическую визуализацию - с ней красивше смотрится: Вверху - через квадратуры, внизу - через разность. И что там в первом GSM смотреть? Слишком много всего написано, и не факт что найду нужное. К тому же я не припомню, чтобы первый GSM решал вопросы скоростей выше 0,5 МБит/c
-
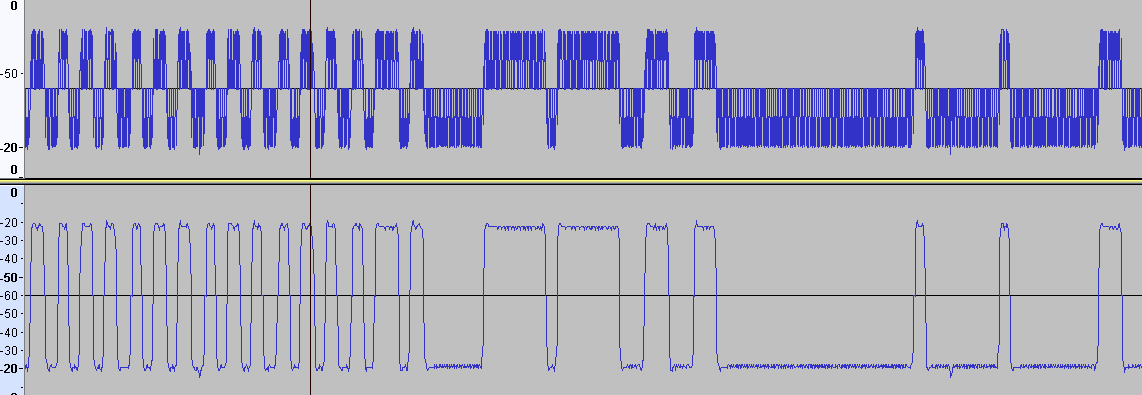
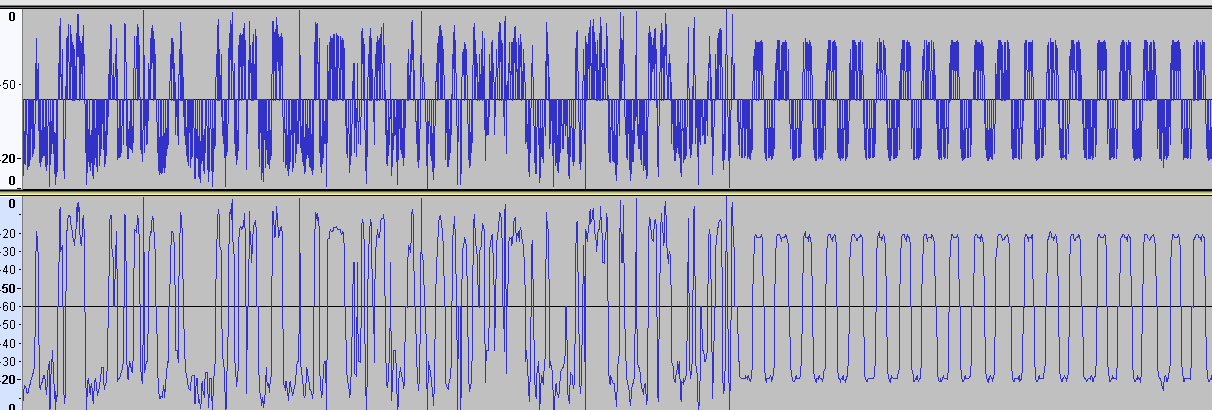
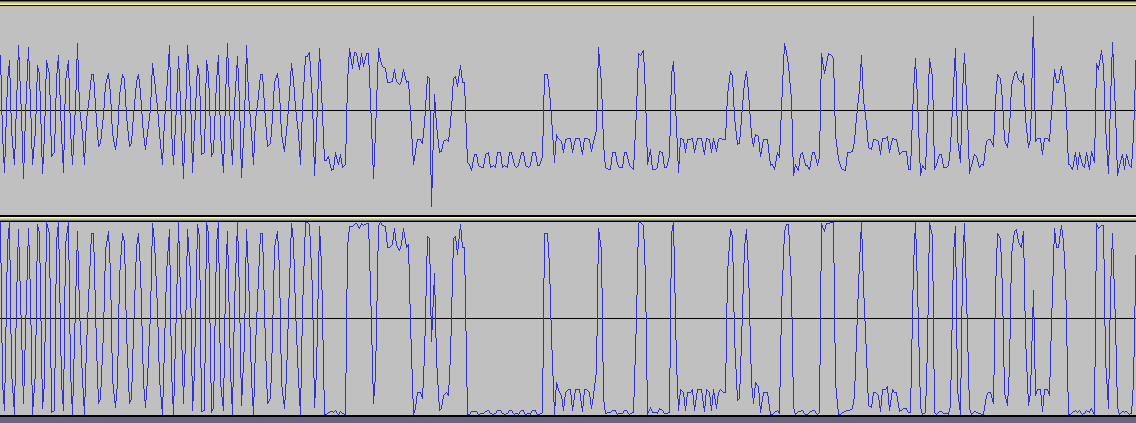
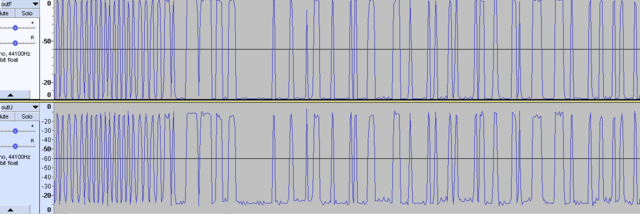
Соединил ВЧ входы двух устройств через аттенюатор -30 дБ. Мощность -10 дБм. Снял фазу сигнала. Результат ничем не отличается от сигнала, принятого с эфира. Потому что оба устройства находятся рядом. И всё-же КМК форма сигнала, найденная через квадратуры и раскрытую производную арктангенса лучше смотрится, чем производная с раскрытого арктангенса. Проще говоря, рисунок ниже - лучше (нет АМ и меньше заусенцев): И кстати, почему когда передаётся преамбула, видно на графике, что частота слегка подплющивается периодически? Ну тоесть она как бы слегка частотно-модулированная визуально. Выровнял чтения регистра фазы. Теперь отсчёты фазы бирутся через одинаковый временной интервал. Стало лучше. Но выбросы всёравно остались.
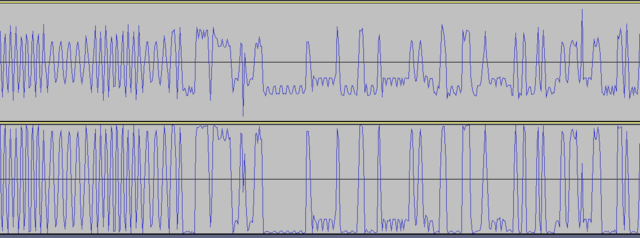
-
Заработал нормально diff (unwrap ( ) ) Нужно было диапазон -64...+63 привести к 8 битному. Иначе скругление разницы не работало. Пока просто умножил на 2: диапазон -128... +126. Правильнее надо -128...+127 s8 BufferIn[SIZE]; s8 BufferOut[SIZE]; BufferOut[0]=0; for(int i=1;i<SIZE;i++) { BufferOut[i]=2*(BufferIn[i]-BufferIn[i-1]); } Выбросы как я понимаю из-за погрешностий интервала взятия отсчётов. При нахождении разницы unwrap не нужен. Так как происходит переполнение 8-бит с скругление с + на -.
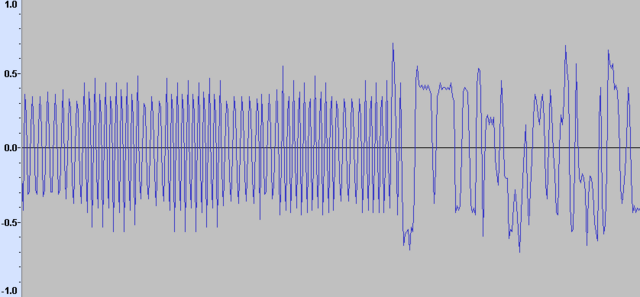
-
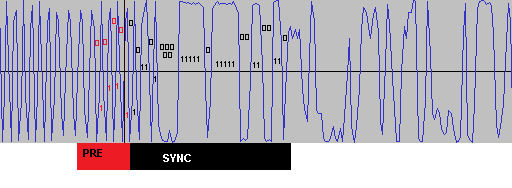
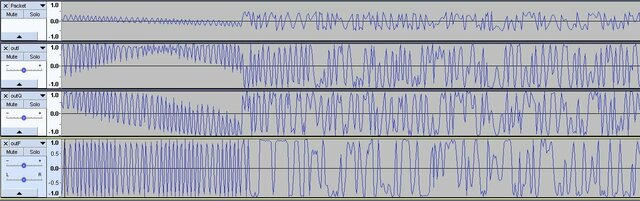
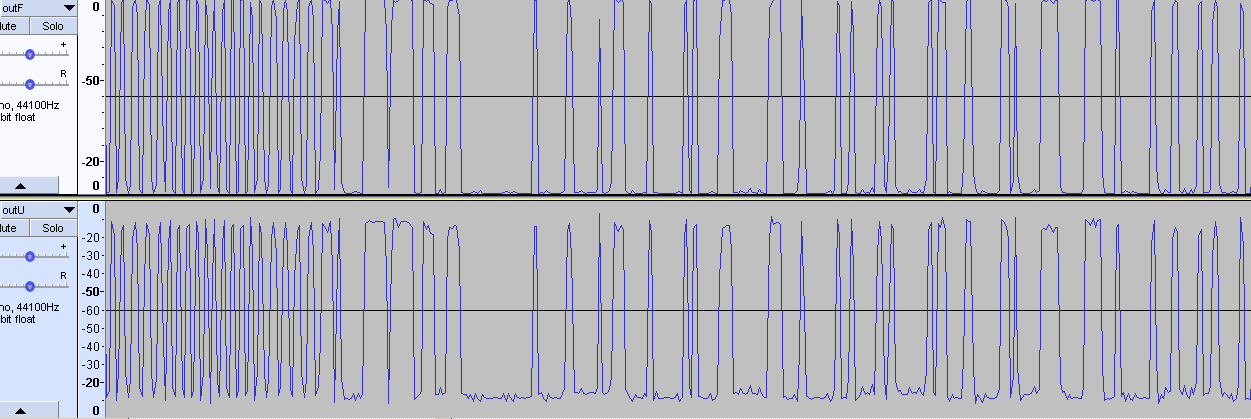
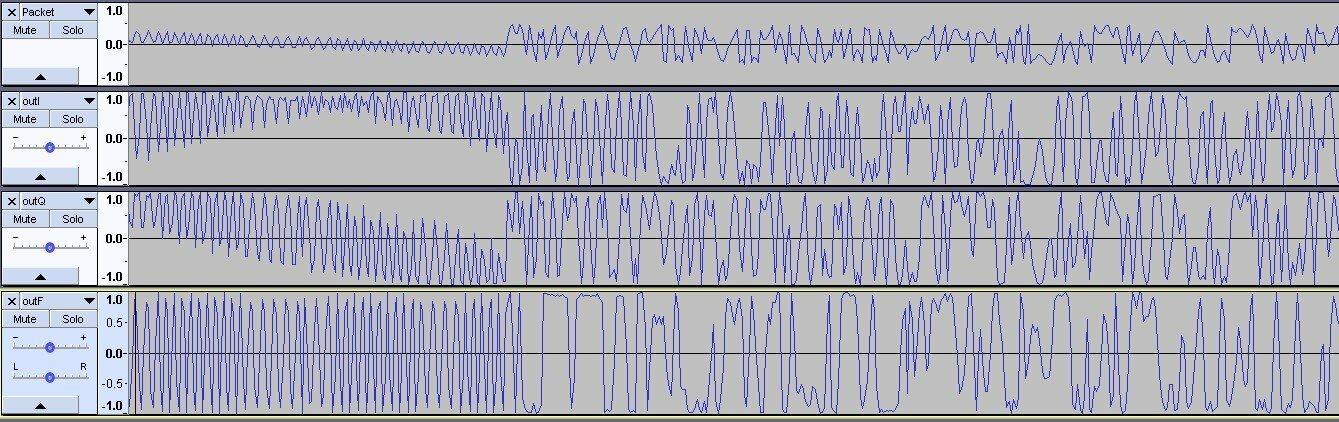
Задача решена. Нашёл синхро-слово после преамбулы, которое передаю (преамбула 010101...0101, синхрослово: 0x5A0FBE66 - в эфире: 01011010 00001111 10111110 01100110). Скорость 0.5 МБит/c, модуляция 2FSK: Очень помогла вот эта статья: https://ru.dsplib.org/content/signal_fm_demod/signal_fm_demod.html В ней написано, как получить мгновенную частоту FM-сигнала и как избавиться от разрывов арктангенса. По мгновенным отсчётам фазы, вначеле построил I- и Q- сигналы. Их магнитуда условно принята M=1, так как амплитудная составляющая предполагается постоянной при угловой модуляции (ЧМ, ФМ) а также включено АРУ в приёмнике. Затем нашёл мгновенные значения модулирующей частоты по формуле из статьи: Весь конвеер: Packet - исходные отсчёты фазы (полученные из Si4463 с помощью программы-эксплоита, и переданные на хост-контроллер для записи данных). OutI - синфазная составляющая, найденная по отсчётам фазы: I(o)=M*cos(o) OutQ - квадратурная составляющая, найденная по отсчётам фазы: Q(o)=M*sin(o) OutF - итоговая модулирующая частота, по которой ищется синхро-слово и пакет за ним. Программа на Сях (накидал на скорую руку): #include <stdio.h> #include <stdlib.h> #include <string.h> #include <math.h> #include "Type.h" #define SIZE 32538 s8 BufferIn[SIZE]; float BufferOutI[SIZE]; float BufferOutQ[SIZE]; float BufferOutF[SIZE]; int main(void) { FILE *f=fopen("Packet.raw","rb"); fread(BufferIn,SIZE,1,f); fclose(f); for(int i=0;i<SIZE;i++) { s8 o=BufferIn[i]; float fi=((float)o)*M_PI/64; if(fi<-M_PI)fi=-M_PI; else if(fi>+M_PI)fi=+M_PI; float I=cosf(fi); float Q=sinf(fi); BufferOutI[i]=I; BufferOutQ[i]=Q; } BufferOutF[0]=0.0F; for(int i=1;i<SIZE;i++) { float dI=BufferOutI[i]-BufferOutI[i-1]; float dQ=BufferOutQ[i]-BufferOutQ[i-1]; BufferOutF[i]=((dQ*BufferOutI[i])-(dI*BufferOutQ[i]))/((BufferOutI[i]*BufferOutI[i])+(BufferOutQ[i]*BufferOutQ[i])); } f=fopen("outI.raw","wb"); fwrite(BufferOutI,SIZE,sizeof(float),f); fclose(f); f=fopen("outQ.raw","wb"); fwrite(BufferOutQ,SIZE,sizeof(float),f); fclose(f); f=fopen("outF.raw","wb"); fwrite(BufferOutF,SIZE,sizeof(float),f); fclose(f); } Пока есть небольшой джиттер. Я могу позволить себе до 8 отсчётов на символ максимум при символьной скорости до 625 кбит/с. Так что-ли? Мне пока интересно софтово это сделать. Уже вычислил. Нормированные, правда. Но в моём случае амплитуда не нужна.