repstosw
-
Постов
2 650 -
Зарегистрирован
-
Победитель дней
2
Весь контент repstosw
-
Разработан новый Lossless видео-кодек
repstosw ответил repstosw тема в Алгоритмы ЦОС (DSP)
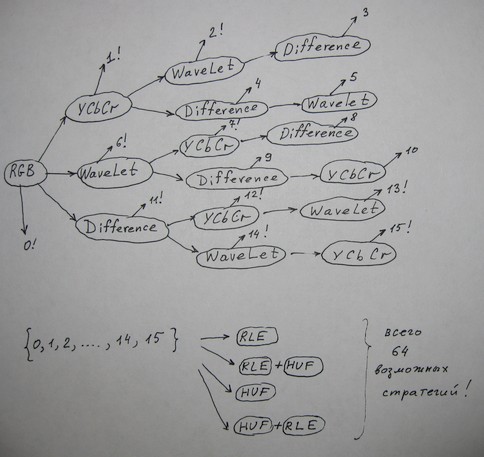
Рассматривал JPEG2000 Lossless, его программная реализация (которая есть в открытом виде) - очень громоздка для переноса на МК STM32F407 и алгоритм просто не пошёл (из-за применения менеджера кучи для данных и кода). К тому же, кодек MJPEG2000 Lossless проигрывает по степени сжатия даже тому же Lagrith. Dirac - тоже жмет хуже Lagarith и требует много вычислительных ресурсов. HuffYUV - прост, но хуже всех жал. MSU - нет исходников Lagarith - хотел вначале портировать его, но мой кодек его обскакал по сжатию (в анимешных мультфильмах) Остался 1 путь - написать свой, взяв всё лучшее со всех. Я - человек науки, поэтому тут ещё дополнительно академический интерес. Жал много фильмов, мультфильмов, коэффициент сжатия был не ниже 2. Обычно от 2.8 - 3. Конечно, если жать белый шум, то выигрыша не даст :) Пробовал применить ZLIB, слишком затратно по времени на декодирование. LZH тоже. Так что только энтропийное кодирование. ---------------------------------- Я вот тут подумал и сообразил новый Мульти-Стратегический кодек. Суть его в том, что пробуются все возможные сочетания блоков конвеера на предмет сжатия. И выбирается лучшая стратегия. Если исходный сигнал у нас - это RGB, то блоков конвеера у нас 5: 1) преобразование YCbCr 2) WaveLet преобразование 3) Difference преобразование (межкадровое вычитание) 4) Huffman 5) RLE Просчитал, возможно 64 комбинации, они на рисунке ниже. Написал кодер, прогнал вариант 3): "Space Cobra": 1034.24 МБ С учётом 6 бит из 8: 775.68 МБ PackMan rev.0: 225 МБ PackMan rev.1: 211 МБ получилось 187 МБ против 211, что неплохо! Причем задача декодирования нисколько не усложняется, а наоборот даже - в некоторых случаях конвейер декода будет короче, номер стратегии пишется в хедер - каждый номер определяет жестко заданный порядок декодирования . Это немаловажно для STM32F407. Восклицательным знаком помечены те варианты, которые были распознаны как оптимальные по сжатию. (подсчитал статистику по стратегиям )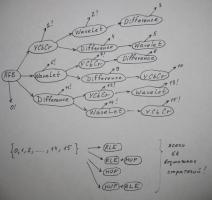
-
Разработан новый Lossless видео-кодек
repstosw ответил repstosw тема в Алгоритмы ЦОС (DSP)
Фото плеера: Принципиальная схема (элементы, помеченные как NC - отсутствуют): Видео в действии (на мерцание экрана не обращать внимание, это из-за фотоаппарата): video1.zip и video2.zip
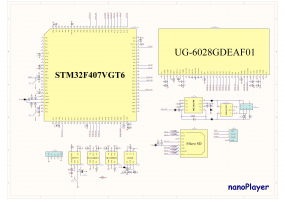
-
Разработан новый Lossless видео-кодек
repstosw опубликовал тема в Алгоритмы ЦОС (DSP)
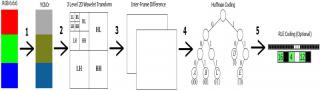
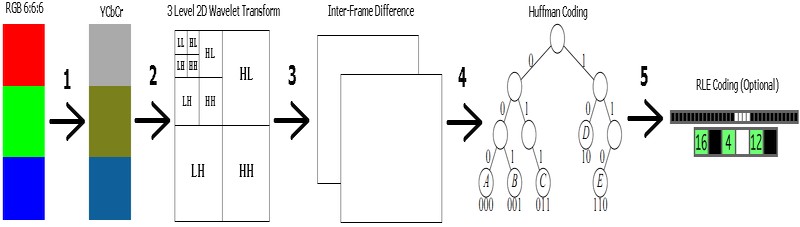
Здравствуйте! :) Решил поделиться с общественностью своими наработками в области сжатия видео без потери качества. :yeah: Разработан битэкзактный 4,5 ступенчатый Lossless Bitexact кодек видео под названием "PackMan" rev.0. Кодек соперничает с MSU и Lagarith, исходники открыты и доступны для платформ: - ПК (ДОС, все Винды) - ARM Cortex-M4 (STM32F407), только декодер Конвейер кодера: Декодер - обратим. Подробное описание здесь: http://vrtp.ru/index.php?act=categories&am...mp;article=3713 Про nanoPlayer здесь: http://vrtp.ru/index.php?showtopic=29688&st=90 и здесь: http://vrtp.ru/index.php?act=categories&am...mp;article=3712 Макет плеера: Релиз будет скоро спаян, печатные платы есть: Принципиальная схема плеера: http://vrtp.ru/index.php?act=Attach&ty...t&id=769410 Исходники кодера и декодера + билды под форточки, ДОС, скрипт, тестовый образец: PackMan_Codec.zip Исходники декодера для STM32F407, вывод оптимизирован, параллельно играет FLAC с asm-оптимизацией: nanoPlay_PackMan.zip Кодек зарелижен, оттестирован. Битэкзактный на уровне 6 бит (специфика железа) Замечания, пожелания, эксперименты и предложения по улучшению сжатия кодера и/или скорости декодера приветствуются!